title: Spark系列
第十三章 SparkSubmit提交任务到YARN
13.1 SparkSubmit提交的一些参数解释
local 本地单线程
local[K] 本地多线程(指定K个内核)
local[*] 本地多线程(指定所有可用内核)
spark://HOST:PORT 连接到指定的 Spark standalone cluster master,需要指定端口。
mesos://HOST:PORT 连接到指定的 Mesos 集群,需要指定端口。
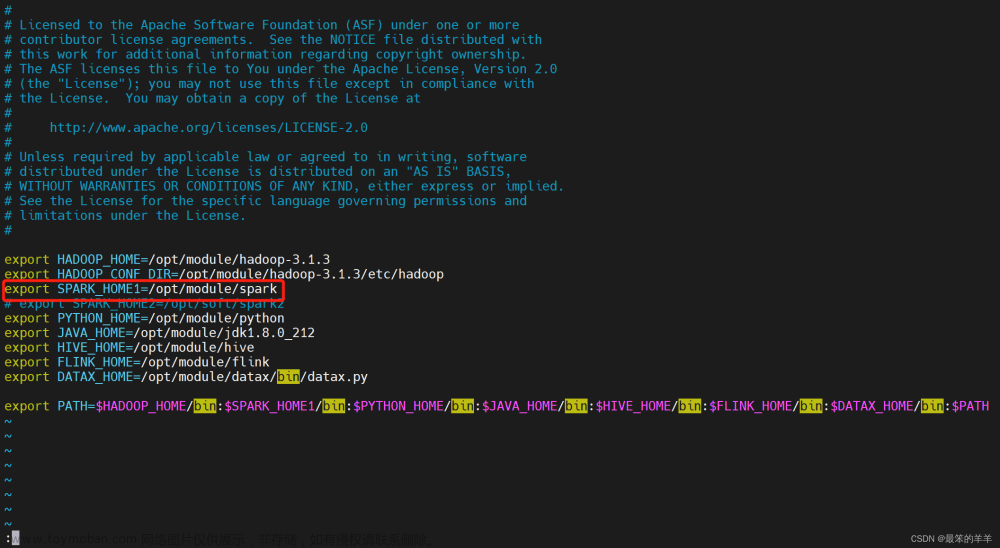
yarn-client客户端模式 连接到 YARN 集群。需要配置 HADOOP_CONF_DIR。
yarn-cluster集群模式 连接到 YARN 集群。需要配置 HADOOP_CONF_DIR。
13.2 提交任务到本地运行
本地模式,不启动spark集群也能运行。
$SPARK_HOME/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[4] \
--driver-memory 512M \
--executor-memory 512M \
--total-executor-cores 1 \
$SPARK_HOME/examples/jars/spark-examples_2.12-3.1.2.jar \
10
实际可运行命令:
/software/spark/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[4] \
--driver-memory 512M \
--executor-memory 512M \
--total-executor-cores 1 \
/software/spark/examples/jars/spark-examples_2.12-3.1.2.jar \
10
运行截图:

结果截图:

13.3 提交任务到Spark集群运行
需要启动Spark的StandAlone集群来运行。
$SPARK_HOME/sbin/start-all.sh
$SPARK_HOME/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop10:7077 \
--driver-memory 512M \
--executor-memory 512M \
--total-executor-cores 1 \
$SPARK_HOME/examples/jars/spark-examples_2.12-3.1.2.jar \
100
13.4 提交到YARN集群,使用yarn-client模式
$SPARK_HOME/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--driver-memory 512M \
--executor-memory 512M \
--total-executor-cores 1 \
$SPARK_HOME/examples/jars/spark-examples_2.12-3.1.2.jar \
10
直接提交可能会报错:
Exception in thread "main" org.apache.spark.SparkException: When running with
master 'yarn' either HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the
environment.
at
org.apache.spark.deploy.SparkSubmitArguments.error(SparkSubmitArguments.scala:657)
at
org.apache.spark.deploy.SparkSubmitArguments.validateSubmitArguments(SparkSubmitArguments.scala:290)
at
org.apache.spark.deploy.SparkSubmitArguments.validateArguments(SparkSubmitArguments.scala:251)
at org.apache.spark.deploy.SparkSubmitArguments.<init>
(SparkSubmitArguments.scala:120)
at org.apache.spark.deploy.SparkSubmit$$anon$2$$anon$1.<init>
(SparkSubmit.scala:907)
at
org.apache.spark.deploy.SparkSubmit$$anon$2.parseArguments(SparkSubmit.scala:907
)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:81)
at
org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:920)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:929)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
13.5 提交到YARN集群,使用yarn-cluster模式
$SPARK_HOME/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 512M \
--executor-memory 512M \
--total-executor-cores 1 \
$SPARK_HOME/examples/jars/spark-examples_2.12-3.1.2.jar \
10
13.6 提交spark任务到YARN集群时,要求配置
spark-env.sh中:
export HADOOP_CONF_DIR=/home/bigdata/apps/hadoop-3.2.2/etc/hadoop/
spark-defaults.conf中:
spark.yarn.jars /home/bigdata/apps/hadoop-3.2.2/share/hadoop/yar
如若不生效,则直接拷贝 yarn-site.xml 文件到 $SPARK_HOME 中
上述任务在启动的时候,有可能会出现异常, 修改hadoop集群的yarn-site.xml文件, 增加如下配置:
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
<description>Ratio between virtual memory to physical memory when setting memory limits for containers</description>
</property>
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true,实际开发中设置成 true,学习阶段设置成 false -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true,实际开发中设置成 true,学习阶段设置成 false -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for containers</description>
</property>
声明:
文章中代码及相关语句为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除。感谢。转载请注明出处,感谢。文章来源:https://www.toymoban.com/news/detail-435638.html
By luoyepiaoxue2014
B站: https://space.bilibili.com/1523287361 点击打开链接
微博地址: http://weibo.com/luoyepiaoxue2014 点击打开链接文章来源地址https://www.toymoban.com/news/detail-435638.html
到了这里,关于Spark系列之SparkSubmit提交任务到YARN的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!