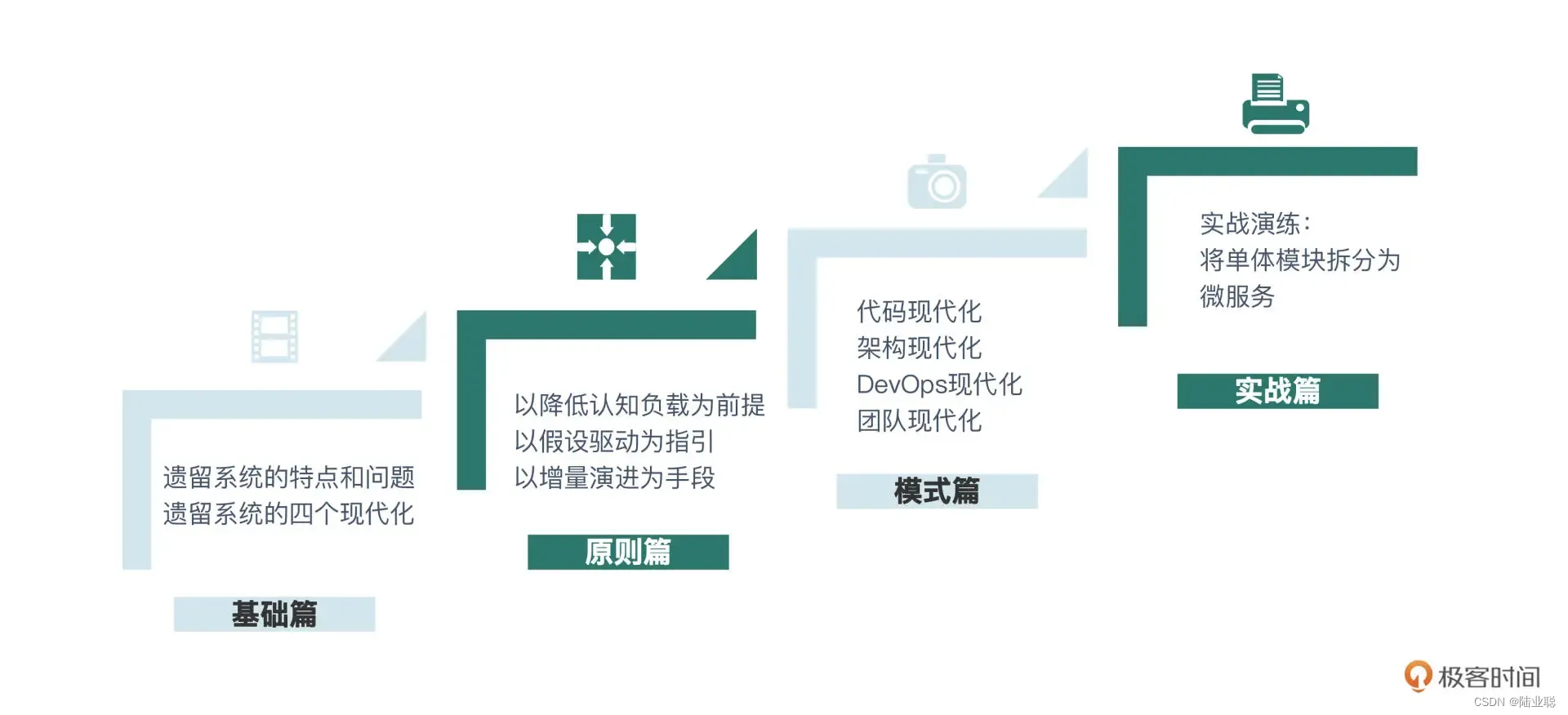
如何拆分数据
Hi,我是阿昌,今天学习记录的是关于如何拆分数据的内容。
如何拆分数据,这个场景在建设新老城区,甚至与其他城市(外部系统)交互时都非常重要。
作为开发人员,理想中的业务数据存储方式是什么样呢?
当然是负责一个业务的数据都在一张或几张名称相关的表中,这样通过名称就可以一目了然,查找起来很方便。
不过很遗憾,现实有时候总是事与愿违,遗留系统中负责处理一个业务的数据,有的放在这张表,有的放在那张表,总是不在一起,名称甚至都没关系;而一张表中也有可能存放几种业务的数据。
一、共享数据库
拆分数据的第一个模式是什么?不要拆分。
不拆分真的可行么?这需要先分析一下拆分的必要性。
遗留系统的数据拆分是个认知负载非常高的工作,不同的数据混杂在一起,具有不同业务含义的数据也往往存放于一张表中,要想彻底拆分干净十分不容易。
如果不需要不停机更新(大多数企业的业务系统其实都不需要)、没有严苛的可用性和弹性需求,或者数据量没有大到无法接受的程度,就没有必要拆分数据库。
这时,共享数据库(Shared Database)也是一个可以接受的选择。在架构现代化-微服务分享了基于服务的分布式架构,就是一种共享数据库的分布式架构。

共享的数据分成两种情况。
- 第一种是不同的服务访问同一数据库的不同 Schema
- 第二种是不同的服务访问同一数据库的同一 Schema。
第一种情况相当理想,因为不同业务领域的数据在逻辑上是隔离的,数据的所有权非常清晰。一个服务如果想访问其他服务的数据,在发现 Schema 不同后,一般不会跨 Schema 去读表,而是通过代码依赖或者数据库视图来访问。
第二种情况要差一些,所有模块都可以随意访问任意的表,操作这些数据的业务逻辑散落在各个服务中,很难知道一张表到底归谁所有。
一个服务,不管是粗粒度的领域服务还是微服务,都可以看成是行为和状态的组合,它封装了一个或多个状态机。这些状态其实就是数据,如果改变这些数据的行为分散在系统的不同位置,你其实很难正确实现这个状态机。
对于第二种情况,应该尽量避免,或者只是作为一个过渡阶段,最终仍然要按逻辑或者物理的方式来隔离不同的数据。
二、数据库视图
外部系统需要连接数据库来读写它所需要的数据,这里要要绝对避免共享数据库。
因为在这种情况下,数据的所有权将不再仅属于当前系统,不同的团队都能随意修改数据,很快就会变得混乱不堪,不同系统间的集成也会成为大问题。
这时可以采取的一种方式是,为不同的外部系统创建不同的 Schema,在 Schema 中提供数据库视图(Database View),这些视图访问主 Schema 中的表。
外部系统就能以只读的方式访问你的数据了。由于视图提供的是全部数据的一个有限的子集,外部系统只能访问想让它访问的数据,比如部分表以及表中的部分字段,其他数据得以隐藏。
这样就能最大程度地避免数据所有权的模糊。

三、数据库包装服务
可以访问数据库视图的,不仅仅是外部系统,还可以包括气泡上下文中的基于防腐层的仓库。
但视图的方式只能提供只读数据,如果外部系统希望写入数据,应该如何处理呢?
可以对数据库进行一层薄薄的封装,形成一个服务,将数据库的细节隐藏在这个**数据库包装服务(Database Wrapping Service)**之后,将数据库依赖转换成服务依赖。
通过在数据库外放置一个明确的包装层,可以很清楚地知道哪些数据是属于你的,哪些数据是别人的。

如果系统是基于 Web 的,甚至可以在原系统之中去开发这个包装服务。
最好把它当做一个气泡上下文,去开发一个全新的服务,不要让本就混乱的遗留系统雪上加霜。
如果遗留系统不是基于 Web 的,那就更推荐使用这种模式了。
数据库包装服务除了可以提供写能力外,在读能力上也比数据库视图更灵活。
提供的并不局限于一张表或表中的部分字段,还可以提供更加复杂的数据映射。
这种包装服务看似很薄,但它也可以作为一个中间步骤,为后续更深入的数据拆分打下基础。
四、报表数据库
如果外部系统或气泡上下文是一个报表系统或服务,需要读取大量的数据,数据库包装服务的方法就不太适用了。
因为这个包装服务的所有权是你的,而不是外部系统的,它们无法灵活地定制查询。而数据库视图也有点力不从心,因为业务数据和报表的流量都压在一个数据库上,这显然不是你想看到的。
更好的方式是使用报表数据库(Reporting Database)模式,它会为报表这类只读的服务单独构建一个数据库。这个数据库可以是业务数据库的远程复本,也可以是一个完全不同的、更适合报表的数据结构(如大宽表),并通过某种方式来做数据的转换和映射。
对于后一种实现,可以使用与业务数据库完全异构的数据库,这样更加灵活。
但它也带来了一定的开销,就是需要自己去实现一个数据映射的工具。

报表数据库模式有时也叫做数据库即服务接口(Database-as-a-Service Interface),因为这种思想已经远远不止用于报表这个单一场景了。
随着大数据的兴起,很多数据项目也使用类似的方式,将业务数据映射到数据仓库或数据湖中,再由数据流水线去进行处理。
五、变更数据所有权
四种模式,都是基于一个共享的数据库,并没有涉及到拆分数据库这个真正棘手的问题。
之所以先讲四种共享数据库模式,是想让知道,在不拆分数据库的情况下,也有一些方案可以选择。
如果要拆分数据,最简单的场景就是在基于服务的分布式架构中,不同服务访问单体数据库中的不同 Schema。
因为不同业务领域的数据已经由 Schema 隔离开了,只需要少量改动,就可以将不同 Schema 中的数据迁移到单独的数据库中。
如果不同服务访问的是单体数据库中的相同 Schema,就会麻烦得多,因为数据并没有从逻辑上进行隔离。但简单的情况怎样处理,已经知道了,那稍微复杂一些的情况就好办了,只要把它转换成简单的情况就可以了。
所以只需要把同一 Schema 下的数据,用 Schema 隔离开。
那新的问题就来了,怎么隔离呢?
不同的领域服务访问的表都是交织在一起的,根本不知道哪些表属于哪个领域服务或组件。其实,可以回忆一下架构现代化-微服务的内容,如果组件之间边界不明显,可以使用战术分叉的方式将“拆”变为“删”。
其实数据拆分也是一样的,也可以将整个 Schema 复制一份,在新的 Schema 中删除相应的领域服务没有访问到的表,剩下的就是与领域服务有关的所有表了。

再对访问的表做个分组处理。需要依据的原则是,谁写数据谁就拥有这张表。
因此,可以把执行写操作的表,当作是真正归属于当前领域服务的,保持不动即可;而只读的表应该归其他领域服务,所以可以把这些表调整成视图。
如果目标是拆分 Schema,到这一步就差不多结束了。但如果目标是独立的数据库,还要在独立的数据库中将这些视图转换为表,将原数据库中的数据冗余到新库中,并通过 CDC 和事件拦截等方式同步数据。
如果不想冗余数据,你还可以将连表查询转换为 API 调用。
具体来说就是,拆分新库和老库中不同表的连表查询,提取出新库的查询,在单体或其他领域服务中把老库的表封装成 API。
然后在独立出来的领域服务中,把新库的数据和调用 API 得到的数据组装起来。
在封装老库的 API 时,可以使用数据库包装服务模式,也可以使用更加开放的聚合 API 模式。
后者不像前者那样只提供基础的 CRUD 服务,而是将一个聚合的所有操作都暴露为 API。
比如在订单服务中,下完一个订单后,会连带着对库存表进行操作。用数据库包装服务的话,库存服务就会封装一个修改库存表的 API,而聚合 API 则会提供一个减库存的 API。
两者乍看上去似乎差别不大,但其实体现出了完全不同的封装策略。
这种将混杂在一起的数据拆分出来,各自归属各自服务的过程,叫做变更数据所有权(Change Data Ownership)。
在这个过程中,有的时候是在 A 中先查出数据,然后调用 B 得到 B 的数据,然后在 A 中进行组合;
有的时候是在 A 中查出部分数据,根据这些数据去调用 B,得到最终结果。
到底怎么调用其实不重要,只要数据的所有权划分清楚了就好。
六、在应用中同步数据
在拆分数据的时候,出发点可能并不是解耦,而是想换一个更加合适的数据库,来解决特定的问题。
比如社交领域中的好友关系,可能想用图数据库来替换关系型数据库,来得到更好的查询性能。
建议先拆再换,而不要想着一次性连拆带换。
做遗留系统现代化这种高认知负载的任务,尤其要记住的一点就是,一次只做一件事,将认知负载降到最低。
那么当数据库拆分出来之后,如何切换到异构数据库呢?
一个比较稳妥的办法——在应用中同步数据。
来看看它的增量演进方案,一共分四步。
- 第一步,
批量地复制数据。如果老库在业务上是允许停机的,可以直接停机导数据。如果不允许停机,在复制数据的过程中会产生新的数据。这就需要通过CDC等方式来保证这部分变动也能同步到新库中。 - 第二步,
同时写入新旧两个库,但只从旧库中读数据。由于新库刚刚部署不久,很可能会出问题,所以要在应用程序中“双写”新旧两个库,以确保两个库中都有同样的业务数据。一旦新库出现问题,业务也不至于受影响。 - 第三步,
同时写入新旧两个库,但只从新库中读数据。当对新库的基础设施有了信心之后,就可以把读操作也转移到新库中。这时我们仍然双写数据,因此出现任何问题都可以回退。 - 第四步,当新旧两库同时运行一段时间后,对新库的方方面面都有了十足的信心,此时就可以
删掉旧库(或 Schema),彻底迁移到新库中了。除了做异构数据库的迁移,这种方式也同样适用于拆分微服务时的数据解耦。为了保证拆分数据的正确性,在增量演进的时候,也必然需要保证新旧两个库的数据同步。
在同步时,由于有开关的存在,因此需要在新旧系统中都实现数据的双写。
除此之外,该模式也可以用于先拆数据再拆服务的情况。
拆分服务的时候,有时会先拆代码,再拆数据库,有时则反之,先拆数据库再拆代码。
七、先拆代码还是先拆数据库?
目标是微服务架构,那么只有代码和数据库都拆分出来且独立部署了,整个任务才算结束。因此拆分工作,就有三种顺序可选:
- 先拆数据库
- 先拆代码或同时拆分。
拆分数据库(包括拆分成单独的库或拆分出新的 Schema),意味着以前的事务性操作会变成非事务的,你需要访问新旧两个库,然后在代码中对数据进行集成。这会造成新旧两个库的不一致。
虽然早晚都会遇到这样的问题,但我仍然建议你先拆分代码,因为拆分代码的认知负载相对低一些,采用战术分叉的方式拆分,也会更简单。这能让你快速得到一些短期收益,比如代码的解耦、服务的独立部署。而且从单体到基于服务的分布式架构这条演进路线,也是十分清晰和成熟的。
可以随时停止,随时重启。而数据库拆分则要困难得多,一旦先拆数据库,又发现很长时间看不到收益,团队的士气会严重受挫。不过无论如何,都不建议同时拆分。
一次只做一件事,是原则。有些架构师可能还希望在拆分数据库的同时重新设计数据库,增加或修改一些表,通常都建议不要贪心,保持克制,尽量先拆再改。
一次做多件事,任务的范围会越来越发散,导致最终迷失方向,忘了初心。
遗留系统本身就是认知负载非常高的系统,不要再人为地增加认知负载了。
八、小结
拆分遗留系统的数据时,可以选用的一系列模式,第一张表是在拆分数据库时,可用于数据同步的几种模式:

第二张表是在拆分服务时,可用于数据共享的几种模式:

数据库的解耦,是无论如何都会面对的问题,也是架构现代化中最困难最复杂的部分。文章来源:https://www.toymoban.com/news/detail-435870.html
很多时候,代码的拆分其实就相当于数据的拆分。文章来源地址https://www.toymoban.com/news/detail-435870.html
到了这里,关于Day963.如何拆分数据 -遗留系统现代化实战的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!