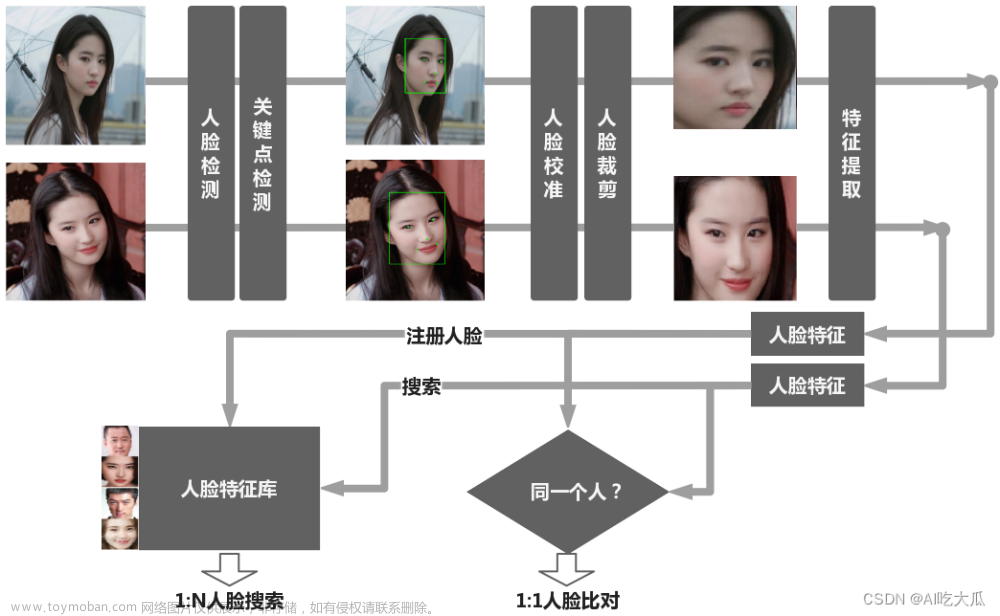
人脸检测和行人检测3:Android实现人脸检测和行人检测检测(含源码,可实时检测)
目录
人脸检测和行人检测3:Android实现人脸检测和行人检测(含源码,可实时检测)
1. 前言
2. 人脸检测和行人检测数据集说明
3. 基于YOLOv5的人脸检测和行人检测模型训练
4.人脸检测和行人检测模型Android部署
(1) 将Pytorch模型转换ONNX模型
(2) 将ONNX模型转换为TNN模型
(3) Android端上部署模型
(4) 一些异常错误解决方法
5. 人脸检测和行人检测效果
6.项目源码下载
1. 前言
这是项目《人脸检测和行人检测》系列之《Android实现人脸检测和行人检测(含源码,可实时检测)》;本篇主要分享将Python训练后的YOLOv5的人脸和行人(人体)检测模型移植到Android平台。我们将开发一个简易的、可实时运行的人脸人体(行人)检测Android Demo。
目前,基于YOLOv5s的人脸和行人(人体)检测精度平均值mAP_0.5=0.98484,mAP_0.5:0.95=0.82777。为了能部署在手机Android平台上,本人对YOLOv5s进行了简单的模型轻量化,并开发了一个轻量级的版本yolov5s05_416和yolov5s05_320模型;轻量化模型在普通Android手机上可以达到实时的检测效果,CPU(4线程)约30ms左右,GPU约25ms左右 ,基本满足业务的性能需求。下表格给出轻量化模型的计算量和参数量以及其检测精度
先展示一下Android Demo人脸和行人(人体)检测的效果


Android人脸和行人(人体)APP Demo体验:https://download.csdn.net/download/guyuealian/87732863
【尊重原创,转载请注明出处】https://blog.csdn.net/guyuealian/article/details/130180240
更多项目《人脸和行人(人体)》系列文章请参考:
- 人脸检测和行人检测1:人脸检测和人体检测数据集(含下载链接):https://blog.csdn.net/guyuealian/article/details/128821763
- 行人检测(人体检测)2:YOLOv5实现人体检测(含人体检测数据集和训练代码):https://blog.csdn.net/guyuealian/article/details/128954588
- 行人检测(人体检测)3:Android实现人体检测(含源码,可实时人体检测):https://blog.csdn.net/guyuealian/article/details/128954615
- 行人检测(人体检测)4:C++实现人体检测(含源码,可实时人体检测):https://blog.csdn.net/guyuealian/article/details/128954638
- 人脸和行人(人体)检测2:YOLOv5实现人脸和行人(人体)检测(含数据集和训练代码):https://blog.csdn.net/guyuealian/article/details/130179987
- 人脸和行人(人体)检测3:Android实现人脸和行人(人体)检测(含源码,可实时检测):https://blog.csdn.net/guyuealian/article/details/130180240
- 人脸和行人(人体)检测4:C++实现人脸和行人(人体)检测(含源码,可实时检测):https://blog.csdn.net/guyuealian/article/details/130180269

如果需要进行人像分割,实现一键抠图效果,请参考文章:《一键抠图Portrait Matting人像抠图 (C++和Android源码)》
 |
 |
 |
2. 人脸检测和行人检测数据集说明
目前收集VOC,COCO和MPII数据集,总数据量约10W左右,可用于人体(行人)检测模型算法开发。这三个数据集都标注了人体检测框,但没有人脸框,考虑到很多项目业务需求,需要同时检测人脸和人体框;故已经将这三个数据都标注了person和face两个标签,以便深度学习目标检测模型训练。
关于人脸人体检测数据集使用说明和下载,详见另一篇博客说明:请参考《人脸检测和人体检测(行人检测)1:人脸检测和人体检测数据集(含下载链接)》:https://blog.csdn.net/guyuealian/article/details/128821763

3. 基于YOLOv5的人脸检测和行人检测模型训练
官方YOLOv5给出了YOLOv5l,YOLOv5m,YOLOv5s等模型。考虑到手机端CPU/GPU性能比较弱鸡,直接部署yolov5s运行速度十分慢。所以本人在yolov5s基础上进行模型轻量化处理,即将yolov5s的模型的channels通道数全部都减少一半,并且模型输入由原来的640×640降低到416×416或者320×320,该轻量化的模型我称之为yolov5s05。轻量化后的模型yolov5s05比yolov5s计算量减少了16倍,参数量减少了7倍。
下面是yolov5s05和yolov5s的参数量和计算量对比:
| 模型 | input-size | params(M) | GFLOPs |
| yolov5s | 640×640 | 7.2 | 16.5 |
| yolov5s05 | 416×416 | 1.7 | 1.8 |
| yolov5s05 | 320×320 | 1.7 | 1.1 |
yolov5s05和yolov5s训练过程完全一直,仅仅是配置文件不一样而已;碍于篇幅,本篇博客不在赘述,详细训练过程请参考: 人脸检测和行人检测2:YOLOv5实现人脸检测和行人检测(含数据集和训练代码)
4.人脸检测和行人检测模型Android部署
(1) 将Pytorch模型转换ONNX模型
训练好yolov5s05或者yolov5s模型后,你需要将模型转换为ONNX模型,并使用onnx-simplifier简化网络结构
# 转换yolov5s05模型
python export.py --weights "runs/yolov5s05_320/weights/best.pt" --img-size 320 320
# 转换yolov5s模型
python export.py --weights "runs/yolov5s_640/weights/best.pt" --img-size 640 640GitHub: https://github.com/daquexian/onnx-simplifier
Install: pip3 install onnx-simplifier
(2) 将ONNX模型转换为TNN模型
目前CNN模型有多种部署方式,可以采用TNN,MNN,NCNN,以及TensorRT等部署工具,鄙人采用TNN进行Android端上部署:
TNN转换工具:
- (1)将ONNX模型转换为TNN模型,请参考TNN官方说明:TNN/onnx2tnn.md at master · Tencent/TNN · GitHub
- (2)一键转换,懒人必备:一键转换 Caffe, ONNX, TensorFlow 到 NCNN, MNN, Tengine (可能存在版本问题,这个工具转换的TNN模型可能不兼容,建议还是自己build源码进行转换,2022年9约25日测试可用)

(3) Android端上部署模型
项目实现了Android版本的人脸检测和行人检测Demo,部署框架采用TNN,支持多线程CPU和GPU加速推理,在普通手机上可以实时处理。Android源码核心算法YOLOv5部分均采用C++实现,上层通过JNI接口调用
package com.cv.tnn.model;
import android.graphics.Bitmap;
public class Detector {
static {
System.loadLibrary("tnn_wrapper");
}
/***
* 初始化模型
* @param model: TNN *.tnnmodel文件文件名(含后缀名)
* @param root:模型文件的根目录,放在assets文件夹下
* @param model_type:模型类型
* @param num_thread:开启线程数
* @param useGPU:关键点的置信度,小于值的坐标会置-1
*/
public static native void init(String model, String root, int model_type, int num_thread, boolean useGPU);
/***
* 检测
* @param bitmap 图像(bitmap),ARGB_8888格式
* @param score_thresh:置信度阈值
* @param iou_thresh: IOU阈值
* @return
*/
public static native FrameInfo[] detect(Bitmap bitmap, float score_thresh, float iou_thresh);
}
如果你想在这个Android Demo部署你自己训练的YOLOv5模型,你可将训练好的Pytorch模型转换ONNX ,再转换成TNN模型,然后把TNN模型代替你模型即可。

(4) 一些异常错误解决方法
-
TNN推理时出现:Permute param got wrong size
官方YOLOv5: GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
如果你是直接使用官方YOLOv5代码转换TNN模型,部署TNN时会出现这个错误Permute param got wrong size,这是因为TNN最多支持4个维度计算,而YOLOv5在输出时采用了5个维度。你需要修改model/yolo.py文件

export.py文件设置model.model[-1].export = True:
.....
# Exports
if 'torchscript' in include:
export_torchscript(model, img, file, optimize)
if 'onnx' in include:
model.model[-1].export = True # TNN不支持5个维度,修改输出格式
export_onnx(model, img, file, opset, train, dynamic, simplify=simplify)
if 'coreml' in include:
export_coreml(model, img, file)
# Finish
print(f'\nExport complete ({time.time() - t:.2f}s)'
f"\nResults saved to {colorstr('bold', file.parent.resolve())}"
f'\nVisualize with https://netron.app')
.....
- TNN推理时效果很差,检测框一团麻

这个问题,大部分是模型参数设置错误,需要根据自己的模型,修改C++推理代码YOLOv5Param模型参数。
struct YOLOv5Param {
ModelType model_type; // 模型类型,MODEL_TYPE_TNN,MODEL_TYPE_NCNN等
int input_width; // 模型输入宽度,单位:像素
int input_height; // 模型输入高度,单位:像素
bool use_rgb; // 是否使用RGB作为模型输入(PS:接口固定输入BGR,use_rgb=ture时,预处理将BGR转换为RGB)
bool padding;
int num_landmarks; // 关键点个数
NetNodes InputNodes; // 输入节点名称
NetNodes OutputNodes; // 输出节点名称
vector<YOLOAnchor> anchors;
vector<string> class_names; // 类别集合
};
input_width和input_height是模型的输入大小;vector<YOLOAnchor> anchors需要对应上,注意Python版本的yolov5s的原始anchor是
anchors:
- [ 10,13, 16,30, 33,23 ] # P3/8
- [ 30,61, 62,45, 59,119 ] # P4/16
- [ 116,90, 156,198, 373,326 ] # P5/32而yolov5s05由于input size由原来640变成320,anchor也需要做对应调整:
anchors:
- [ 5, 6, 8, 15, 16, 12 ] # P3/8
- [ 15, 30, 31, 22, 30, 60 ] # P4/16
- [ 58, 45, 78, 99, 186, 163 ] # P5/32因此C++版本的yolov5s和yolov5s05的模型参数YOLOv5Param如下设置
//YOLOv5s模型参数
static YOLOv5Param YOLOv5s_640 = {MODEL_TYPE_TNN,
640,
640,
true,
true,
0,
{{{"images", nullptr}}}, //InputNodes
{{{"boxes", nullptr}, //OutputNodes
{"scores", nullptr}}},
{
{"434", 32, {{116, 90}, {156, 198}, {373, 326}}},
{"415", 16, {{30, 61}, {62, 45}, {59, 119}}},
{"output", 8, {{10, 13}, {16, 30}, {33, 23}}},
},
CLASS_NAME
};
//YOLOv5s05模型参数
static YOLOv5Param YOLOv5s05_ANCHOR_416 = {MODEL_TYPE_TNN,
416,
416,
true,
true,
0,
{{{"images", nullptr}}}, //InputNodes
{{{"boxes", nullptr}, //OutputNodes
{"scores", nullptr}}},
{
{"434", 32,{{75, 58}, {101, 129}, {242, 212}}},
{"415", 16, {{20, 40}, {40, 29}, {38, 77}}},
{"output", 8, {{6, 8}, {10, 20}, {21, 15}}}, //
},
CLASS_NAME
};
//YOLOv5s05模型参数
static YOLOv5Param YOLOv5s05_ANCHOR_320 = {MODEL_TYPE_TNN,
320,
320,
true,
true,
0,
{{{"images", nullptr}}}, //InputNodes
{{{"boxes", nullptr}, //OutputNodes
{"scores", nullptr}}},
{
{"434", 32, {{58, 45}, {78, 99}, {186, 163}}},
{"415", 16, {{15, 30}, {31, 22}, {30, 60}}},
{"output", 8, {{5, 6}, {8, 15}, {16, 12}}}, //
},
CLASS_NAME
};- 运行APP闪退:dlopen failed: library "libomp.so" not found
参考解决方法:解决dlopen failed: library “libomp.so“ not found_PKing666666的博客-CSDN博客_dlopen failed
5. 人脸检测和行人检测效果
【Android APP体验】https://download.csdn.net/download/guyuealian/87732863
APP在普通Android手机上可以达到实时的人脸检测和行人检测效果,CPU(4线程)约30ms左右,GPU约25ms左右 ,基本满足业务的性能需求。
6.项目源码下载
【Android APP体验】https://download.csdn.net/download/guyuealian/87732863
【项目源码下载】 人脸检测和行人检测3:Android实现人脸检测和行人检测检测(含源码,可实时检测)文章来源:https://www.toymoban.com/news/detail-436035.html
整套Android项目源码内容包含:文章来源地址https://www.toymoban.com/news/detail-436035.html
- 提供快速版轻量化版本的模型:yolov5s05_416和yolov5s05_320人脸检测和行人检测模型,在普通手机可实时检测识别,CPU(4线程)约30ms左右,GPU约25ms左右
- 提供高精度版本yolov5s人脸检测和行人检测模型,CPU(4线程)约250ms左右,GPU约100ms左右
- Android Demo支持图片,视频,摄像头测试
- 所有依赖库都已经配置好,可直接build运行,若运行出现闪退,请参考dlopen failed: library “libomp.so“ not found 解决。
到了这里,关于人脸检测和行人检测3:Android实现人脸检测和行人检测检测(含源码,可实时检测)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!