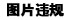安装tensorflow的三种方法
1.在cmd命令行中输入pip install tensorflow,默认安装最新版
2.其他旧版本的安装,去pypi.org官网
可以点击release history选择想要的版本进行安装
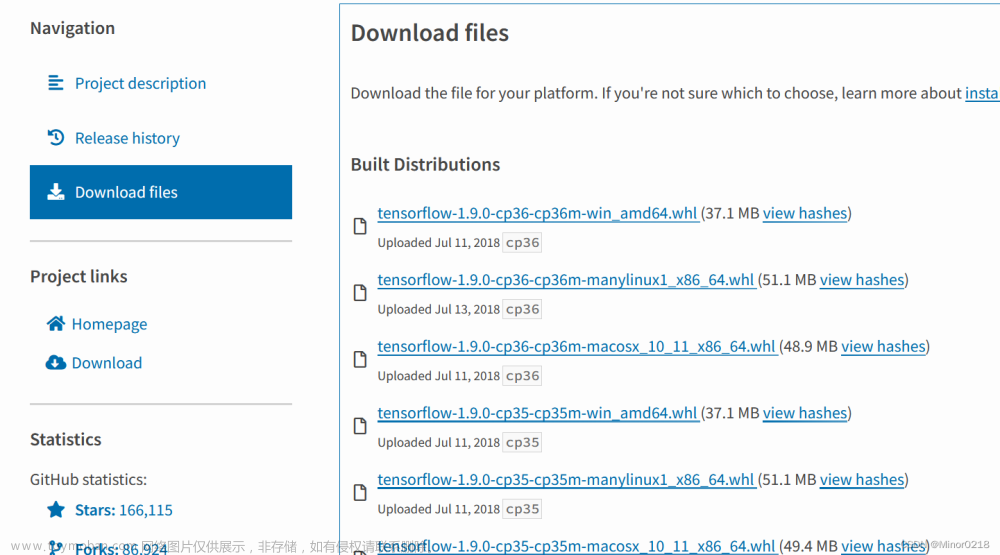
3.安装包安装,找到download files,选择与自己系统匹配的文件进行下载
下载完成后,在cmd命令行中输入 pip install 把下载好的安装包拖进来即可
安装tensorflow出现的问题
我自己选择了第一种方法的安装,安装结束后去pycharm导入模块之后报错,提示没有tensorflow,在网上查找解决方法后发现是没有安装到相应位置。
解决方法:
在cmd命令行中输入activate zjj(这是我之前用anaconda创建的名为zjj的python3.6环境)进入之前创建好的环境
再次输入pip install tensorflow进行安装
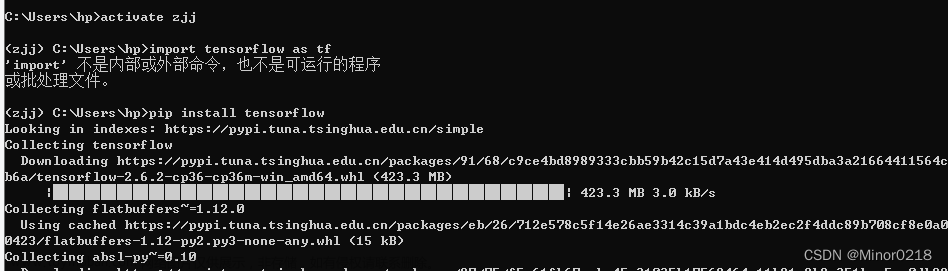
之后就提示安装成功tensorflow以及相应的依赖包了,再次进入pycharm导入模块就成功了(注意pycharm里面的环境要选择刚才安装tensorflow的环境)
请根据给定的100个样本数据找出合适的a,b,c 使得
1.导入100个样本数据
2.构造一个线性模型
3.定义损失函数
4.定义训练函数
5.启动图
6.初始化变量
7. 开始训练
完整代码如下:
import numpy as np #数据类型默认为64位
import tensorflow as tf #数据类型默认为32位
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
#数据类型改为32位
data = np.float32(np.load('line_fit_data.npy')) # 导入100个样本数据
x_data = data[:, :2] # 样本自变量
y_data = data[:, 2:] # 样本实际值
'''
定义计算(计算图)
'''
w = tf.Variable(tf.zeros([2, 1])) #构建变量两行一列a和b
bias = tf.Variable(tf.zeros([1])) #构建c
y = tf.matmul(x_data, w) + bias # 构造一个线性模型,矩阵乘法操作,数据和w相乘加上c
loss = tf.reduce_mean(tf.square(y_data - y)) # 定义损失函数,越低越好(均方误差)
tf.compat.v1.disable_eager_execution()
optimizer = tf.compat.v1.train.GradientDescentOptimizer(0.5) # 构建梯度下降法优化器
train = optimizer.minimize(loss) # 定义训练函数
'''
执行计算(会话中)
'''
# 启动会话
sess = tf.Session()
sess.run(tf.global_variables_initializer()) # 初始化所有变量
# sess.run(y)
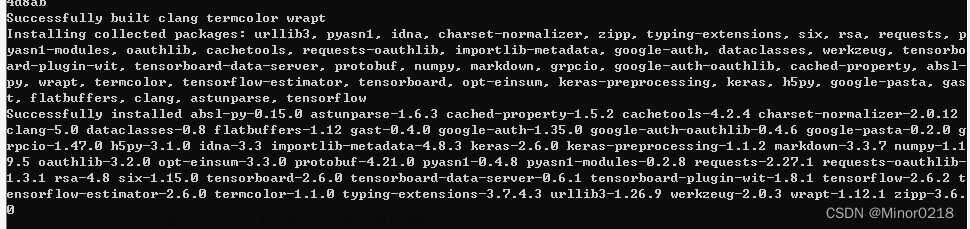
for i in range(100):
print('第', i, '轮训练后的模型损失值:', sess.run(loss))
sess.run(train) # 开始训练
print(sess.run([w, bias]) ) # y = 0.1*x1 + 0.2*x2 + 0.3
sess.close()
运行结果:
可以看到经过100轮的训练,损失函数的值为 2.7425253e-11,a为0.0999,b为0.1999,c为0.300,而这100个样本点就是通过生成的,可以看出训练后的结果与实际值是很接近的
代码运行出现的问题
由于我使用的tensorflow版本是2.0以上版本,出现了以下错误

解决方法:
增加这一句
tf.compat.v1.disable_eager_execution()把
optimizer = tf.train.GradientDescentOptimizer(0.5) 改为
optimizer = tf.compat.v1.train.GradientDescentOptimizer(0.5) 又显示报错Attempting to capture an EagerTensor without building a function.原因是tensorflow版本问题

增加以下两句即可
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()手写数字识别
首先导入模块,读取数据,实际值用x_data和y_data来表示。
设置网络,定义损失函数以及优化器
启动会话执行操作
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
mnist = input_data.read_data_sets('MNIST_data', one_hot=True) # 读取数据
x_data = mnist.train.images
y_data = mnist.train.labels
w = tf.Variable(tf.zeros([784, 10])) # 网络权值矩阵
bias = tf.Variable(tf.zeros([10])) # 网络阈值
y = tf.nn.softmax(tf.matmul(x_data, w) + bias) # 网络输出
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_data*tf.log(y), axis=1)) # 交叉熵(损失函数)
optimizer = tf.train.GradientDescentOptimizer(0.03) # 梯度下降法优化器
train = optimizer.minimize(cross_entropy) # 训练节点
acc = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(y, axis=1), tf.argmax(y_data, axis=1)), dtype=tf.float32)) # 模型预测值与样本实际值比较的精度
sess = tf.Session() # 启动会话
sess.run(tf.global_variables_initializer()) # 执行变量初始化操作
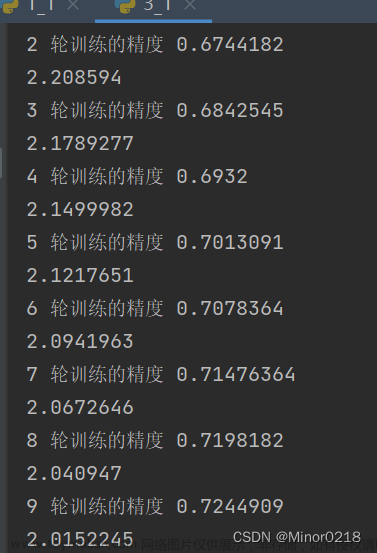
for i in range(10):
print(i, '轮训练的精度', sess.run(acc))
sess.run(train)
print(sess.run(cross_entropy))
sess.close()
运行结果:
可以看到十轮之后的训练精度达到0.72,交叉熵达到2.05,并不是很理想,可以通过增加训练轮数来优化训练结果
上述代码有一个缺点是将所有样本都放到模型里面来训练,这样子计算量很大,尤其是数据集很大的情况下,我们希望每次训练的时候从模型中取出一部分样本来训练。可以把训练样本通过占位符来解决,优化代码如下
把
x_data = mnist.train.images
y_data = mnist.train.labels改为
x_data = tf.placeholder(tf.float32, [None, 784]) # 占位符:样本自变量
y_data = tf.placeholder(tf.float32, [None, 10]) # 占位符:样本目标变量把
for i in range(10):
print(i, '轮训练的精度', sess.run(acc))
sess.run(train)
print(sess.run(cross_entropy))
sess.close()
改为
for i in range(200):
x_s, y_s = mnist.train.next_batch(100) #随机取100个样本
if i%30 == 0: #每隔30轮打印一次精度
acc_tr = sess.run(acc, feed_dict={x_data: x_s, y_data: y_s})
print(i, '轮训练的精度', acc_tr)
sess.run(train, feed_dict={x_data:x_s, y_data:y_s}) # 模型训练
sess.close()可以查看训练200次之后的精度,为了便于观察,我们每隔30次进行一次打印精度操作
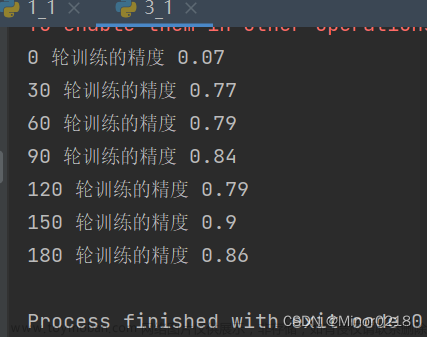
最终训练200轮之后,训练精度达到了0.85左右,但是模型的好坏最终我们要通过测试集来评估。在sess.close()前面加上如下代码,即可用测试集来测试模型的准确率
acc_te = sess.run(acc, feed_dict={x_data:mnist.test.images, y_data:mnist.test.labels}) # 测试集精度
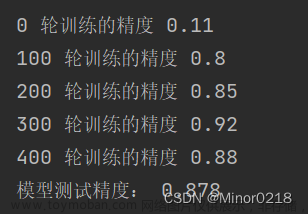
print('模型测试精度:', acc_te)把训练次数调整为500次,每隔100次打印一下精度,可以看到通过500轮的训练,使用测试集测试模型,准确率达到0.87
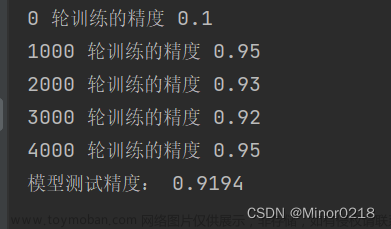
优化模型:可以通过增加训练轮数,改变梯度下降法优化器参数来优化模型,不过由于网络结构的限制,最终模型准确率智能达到0.91左右。
手写数字识别运行代码出现的问题
第一个:

原因:是tensorflow中没有examples,首先找到对应tensorflow的文件。
解决方法:
不知道自己tensorflow的安装位置,进入cmd,我的tensorflow是在anacond的zjj环境中安装的
1.输入conda activate zjj激活环境
2.输入python
3.输入import tensorflow as tf
4.输入tf.__path__查看安装路径(一定要注意path前后都是两个下划线!!!!!)
进入tensorflow文件夹,发现没有examples文件夹。可以从github上下载完整的文件,然后复制到自己tensorflow的安装目录下。
参考文章:https://blog.csdn.net/qq_42632840/article/details/123963041
重新运行,没有报错


第二个:
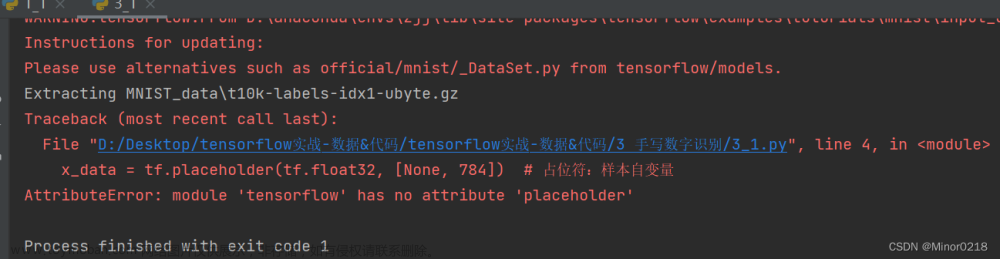
原因:tensorflow 2.0版本去掉了placeholder,而tensorflow 1.几版本才有。
在控制台输入pip freeze,查看当前版本
 解决:将
解决:将
import tensorflow as tf改为文章来源:https://www.toymoban.com/news/detail-436443.html
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()以上实验所需数据放在:http://链接:https://pan.baidu.com/s/1UptIodLkBVTqYEZxVJgRPw?pwd=qblu 提取码:qblu文章来源地址https://www.toymoban.com/news/detail-436443.html
到了这里,关于【tensorflow】tensorflow的安装及应用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!