软件:VM Ware
iso镜像:CentOS7
Hadoop版本:Hadoop-3.3.3
目录
一、创建虚拟机并安装CentOS系统
二、静态网络配置
三、安装Hadoop
1.下载Hadoop安装包
2.下载JDK安装包
3. 安装过程
4.克隆虚拟机
5.配置hoats文件和免密登录
6.Hadoop集群节点配置
7.格式化并启动节点
【好了之后一定要快照!!!避免重新安装!!】
【一起从0开始学Hadoop!!!】
一、创建虚拟机并安装CentOS系统
# 切换成root用户
su
# 检查网络是否连通
ping www.baidu.com
# centOS换源
https://blog.csdn.net/qq_35261940/article/details/122019530# 安装net-tools
yum upgrade
yum install net-tools- yum upgrade
需要输入y,确保继续运行

- yum install net-tools
【这种情况是已经存在了,所以什么都不用做,如果没有,等待安装完成就行】

二、静态网络配置
# 查看防火墙状态
systemctl status firewalld.service
# 关闭防火墙
systemctl stop firewalld.service
# 查看ip地址和Mac地址(ens33 的 enter 后面)
ifconfig
# 这里我的ip地址是192.168.50.160
# Mac地址是00:0c:29:e5:8a:93
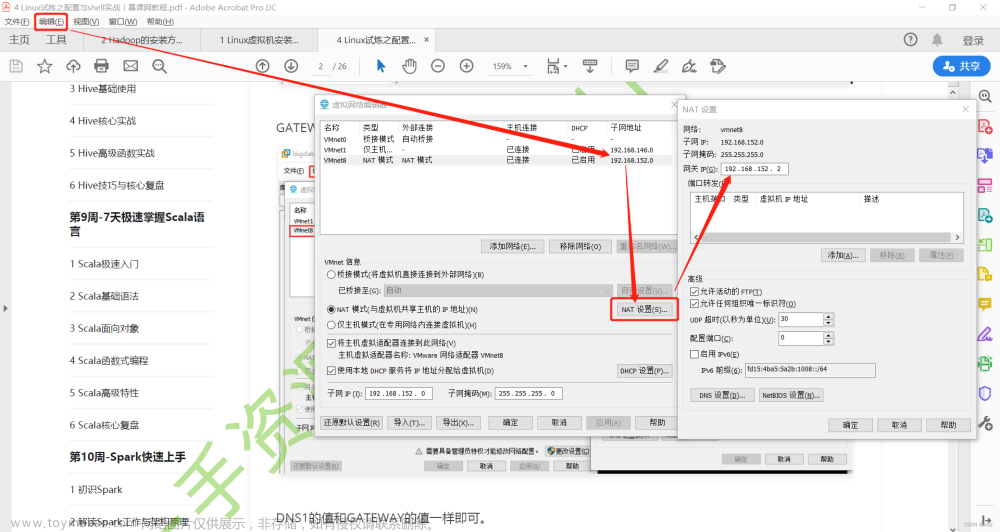
# 配置网络文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33
【使用 i 进入编辑模式,依次按下 esc : 输入wq 后按回车键,进行保存并退出】
BOOTPROTO的值设置为static
ONBOOT的值设置为yes
子网掩码默认设置为255.255.255.0
网关的值为将ip地址中最后一段的值改为2
DNS使用谷歌提供的免费dns1:8.8.8.8

# 重启网络服务,检查是否配置成功
systemctl restart network
ping www.baidu.com

# 重启虚拟机,检查是否在ip没有改变的情况下仍然能连通网络
reboot
ifconfig
ping www.baidu.com
三、安装Hadoop
# 新建目录
mkdir -p /export/data
mkdir -p /export/servers
mkdir -p /export/software1.下载Hadoop安装包
- 方法一:通过Filezilla传至虚拟机
Index of /dist/hadoop/common/hadoop-3.1.3
- 方法二:通过wget下载
wget https://mirrors.ustc.edu.cn/apache/hadoop/common/hadoop-3.3.3/hadoop-3.3.3.tar.gz

2.下载JDK安装包
# 官网下载JDK版本
https://www.oracle.com/java/technologies/javase-downloads.html
# 上传至 /export/software 文件夹下
使用 Filezilla 进行上传

3. 安装过程
# 解压压缩包
tar -zxvf jdk-8u361-linux-x64.tar.gz -C /export/servers/
tar -zxvf hadoop-3.3.3.tar.gz -C /export/servers/
# ls 查看一下解压缩后的内容

# 配置java环境
vi /etc/profile # 编辑profile配置文件
# 添加以下内容
export JAVA_HOME=/export/servers/jdk1.8.0_361
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
# 保存文件
esc
:wq 
# 更新配置文件
source /etc/profile
# 查看 java 版本
java -version
javac
# 配置Hadoop
vi /etc/profile
# 在文件末尾添加以下内容
export HADOOP_HOME=/export/servers/hadoop-3.3.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 保存文件
esc :wq
# 更新文件
source /etc/profile
# 查看是否配置成功
hadoop version
4.克隆虚拟机
先去下面配置完集群再克隆,就不用最后一个问题解决了。
如果按先克隆,最后在格式化之前,将server01,server02的配置文件修改完再格式化也不会出问题。
# 修改虚拟机主机名
# 查看现在的名字
hostname
# 修改第一台为master
hostnamectl1 set-hoatname master
# hostname再次查看一下,是否修改成功
hostname
# 克隆两台虚拟机
# 关机后,右键相应虚拟机->管理->克隆选择创建完整克隆

一个起名字server01,另一个起名字server02

5.配置hoats文件和免密登录
# 分别修改主机名
hostnamectl set-hostname server01
hostnamectl set-hostname server02# 分别修改网络配置
# 查看Mac地址
ifconfig
# 进入root用户
su
# 配置ip地址,保证三台虚拟机在同一个网段
vi /etc/sysconfig/network-scripts/ifcfg-ens33
# server01的配置为192.168.50.161
# server02的配置为192.168.50.162

部分文件内容修改如下

# 重启网络,检查是否连通
systemctl restart network
ping www.baidu.com
此时用ifconfig检查ip,发现已经修改成功

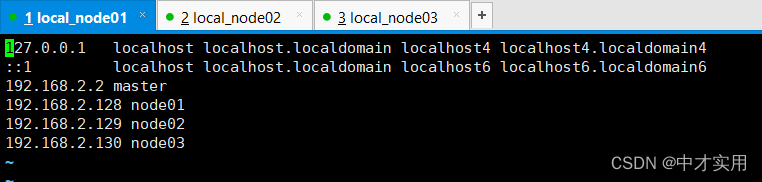
修改hosts文件
vi /etc/hosts
# 添加以下内容
192.168.50.160 master
192.168.50.161 server01
192.168.50.162 server02
# 保存并退出
# 检查节点是否配置成功
ping master
# ping slave1
# ping slave2
配置免密登录
# master主机上生成密钥文件(四次回车)
ssh-keygen -t rsa 
# 本机密钥复制到另外的机器(三台主机都执行)
ssh-copy-id master
ssh-copy-id server01
ssh-copy-id server02

# 检查是否成功免密登录,
# master执行
ssh server01
# server01执行
ssh server02

6.Hadoop集群节点配置
# 进入主节点配置目录
cd /export/servers/hadoop-3.3.3/etc/hadoop/

# 修改配置文件(三台机器都配置)
vi hadoop-env.sh
# 修改JAVEHOME(找到这句话,等号后面输入这个)
export JAVA_HOME=/export/servers/jdk
export HADOOP_CLASSPATH=$JAVA_HOME/lib/tools.jar
# 保存并退出

# 修改core-site.xml文件
vi core-site.xml添加以下内容:
<configuration>
<!--用于设置Hadoop的文件系统,由URI指定-->
<property>
<name>fs.defaultFS</name>
<!--用于指定namenode地址在hadoop01机器上-->
<value>hdfs://hadoop01:9000</value>
</property>
<!--配置Hadoop的临时目录,默认/tem/hadoop-${user.name}-->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-2.7.4/tmp</value>
</property>
</configuration>

# 修改hdfs-site.xml文件
vi hdfs-site.xml添加以下内容:
<configuration>
<!--指定HDFS的数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--secondary namenode 所在主机的IP和端口-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>server01:50090</value>
</property>
</configuration>
# 进行文件备份
cp mapred-site.xml.template mapred-site.xml**
# 修改mapred-site.xml文件
vi mapred-site.xml
添加以下内容:
<configuration> <!--指定MapReduce运行时的框架,这里指定在YARN上,默认在local--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/export/servers/hadoop-3.3.3</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/export/servers/hadoop-3.3.3</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/export/servers/hadoop-3.3.3</value> </property> </configuration>
# 编辑文件
vi yarn-site.xml
添加以下内容
<configuration>
<!--指定YARN集群的管理者(ResourceManager)的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
# 修改slaves文件
# 将文件中的localhost删除,添加主节点和子节点的主机名称
# 主节点master,子节点server01,server02
vi workers # hadoop3.x不使用slaves了

7.格式化并启动节点
# master上格式化节点
hdfs namenode -format
报错,发现没有设置用户

编辑资源文件
# 编辑资源文件
vi ~/.bash_profile
添加以下内容
export HADOOP_HOME=/export/servers/hadoop-3.3.3
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
保存后更新资源文件

# 查看启动情况
jps


问题解决:
【发现子节点没有datanode】
# 停止所有集群
stop-all.sh【重新格式化集群】
# 删除$HADOOP_HOME下的tmp目录下的所有文件
# 删除logs下的所有文件
【三台机器,只有master有tmp目录】再次格式化就行
8.Linux里查看
在web中检查
【虚拟机中使用火狐浏览器】
在浏览器地址栏中输入http://master:9870/,检查NameNode和DataNode是否正常;【3.0.0之前使用50070端口】
在浏览器地址栏中输入http://master:8088/,检查YARN是否正常
10.windows里查看
去C:\Windows\System32\drivers\etc
管理员方式打开hosts文件
添加
192.168.50.160 master
192.168.50.161 server01
192.168.50.162 server02
然后在浏览器中输入上面的网址
11.运行实例检查
cd hadoop-3.3.3/share/hadoop/mapreduce/
hadoop jar hadoop-mapreduce-examples-3.3.3.jar pi 10 10 文章来源:https://www.toymoban.com/news/detail-436658.html
文章来源:https://www.toymoban.com/news/detail-436658.html
 文章来源地址https://www.toymoban.com/news/detail-436658.html
文章来源地址https://www.toymoban.com/news/detail-436658.html
【好了之后一定要快照!!!避免重新安装!!】
到了这里,关于Hadoop学习(一)——环境配置(特别顺利版!!!已经排坑了)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!