并查集与最小生成树

Java高阶数据结构 & 并查集 & 最小生成树
1. 并查集
1.1 并查集的原理
在一些应用问题中,我们常常会遇到一类问题
一开始是一个人
- 后来新增的人可能与这个人有关系,也可能与这个人无关系。
- 一个人与一个人有关系,这个人与另一个人也有关系,那么三人都有关系。
- 有关系的和没关系的之间是不同的类别。

- 而随着人数增加,有多少类别是不确定的,所以用普通的二维数组是很难描述和存储这种数据结构的。
- 因为即使在不考虑时间复杂度的情况下,我们不知道有多少行,并且出现“三人都有关系”的情况的时候,需要合并等等…
而现在有一种数据结构,就专门去解决这个问题,这就是 “并查集”
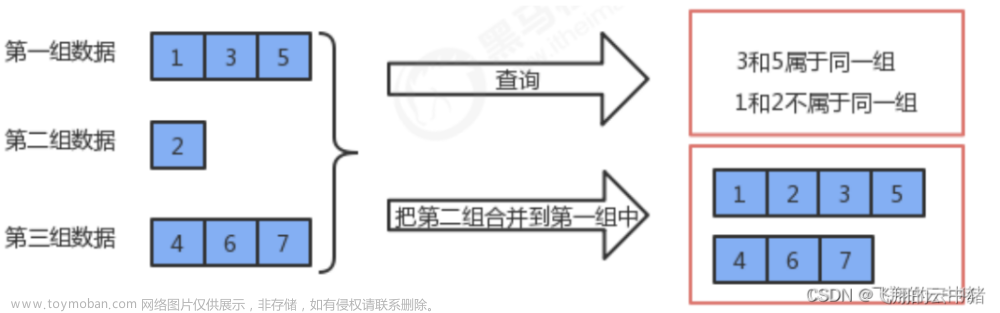
需要将n个不同的元素划分成一些不相交的集合。
开始时,每个元素自成一个单元素集合,然后按一定的规律将归于同一组元素的集合合并。
在此过程中要反复用到查询某一个元素归属于那个集合的运算。适合于描述这类问题的抽象数据类型称为并查集(union-find set)
(先说怎么存储表示的,再说如何构建)
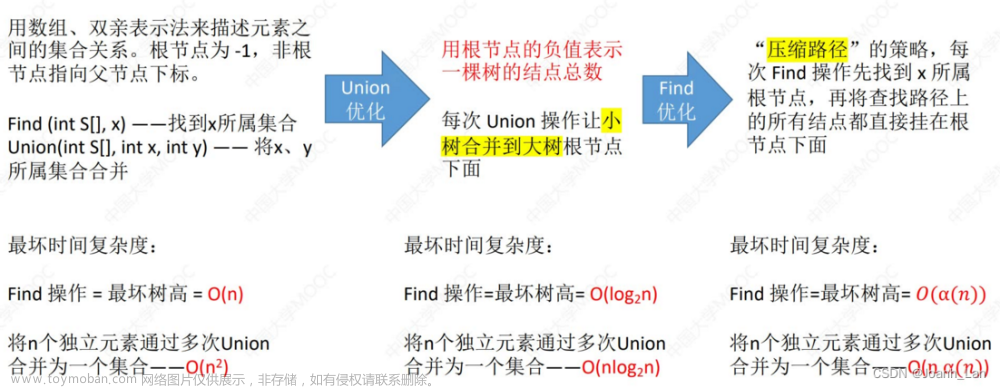
并查集是一个int型的一维数组,而本质就是一维顺序表存储的“森林”
有如下特性:
- 每个节点都有对应的下标,如果有n个节点,那么他们就对应数组的0-n-1
- 森林的不同的树,代表不同的类别
- 每棵树都有一个根节点,这个根节点在数组中的值为负数,绝对值为这棵树节点的个数
- 每棵树的非根节点在数组中的值为其父节点在数组中的下标
1.1.1 例子:
- 现在有十个人,他们分别代表0 - 9
- 他们原本互不相识,但是今天是他们因为缘分出现在同一辆公交车上,这次行程他们都很长,并且在路上网络全无,他们也毫无困意,并且都是社牛。

- 他们开始与周围的车友交谈,可能因为各种原因,如兴趣爱好和地域性,他们互相交换了微信。如果两个人同时与一个人交换微信,那么这两个人也会获得对方的微信。
- 最终下电梯,他们的朋友圈是这样的:

而并查集将变成这样:

1.1.2 这样存储有什么好处呢?
如果有n个节点,那么一开始分为n个类别
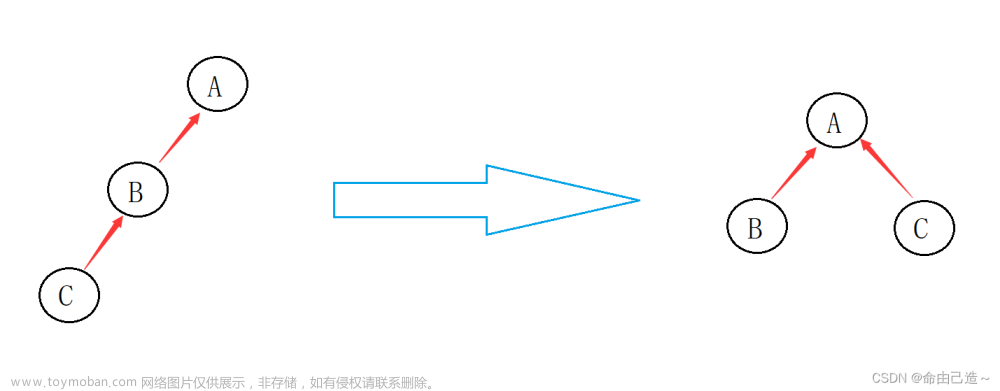
如果a0与a1有关系,那么只需要让a0和a1其中一棵树根节点接到另一棵树的根节点即可
- 一棵树的根节点的值对于新的树的节点数的负数
- 另一棵树的根节点变为“新树的非根节点”,其值为根节点的下标
通过这个机制,最终会很好的分好类别,不需要分好组让把他们放进去,而是他们自己分好了
- 因为同一棵树的根节点都一样,所以负数值的元素有多少个,就说明有多少组
- 当然所有非根节点都可以压缩其值为其所在数的根节点对应下标
而判断两个节点有没有关系,就只需要判断他们根节点是否相同即可
1.2 并查集的代码实现
了解完机制之后,并查集的代码实现并不复杂!
1.2.1 类的定义与属性
public class UnionFindSet {
private int[] elem;
}
这就是并查集的主体
1.2.2 构造方法
public UnionFindSet(int n) {
this.elem = new int[n];
Arrays.fill(this.elem, -1);
}
- 根据n构造数组,并且利用fill充满数组为-1
1.2.3 获取下标的方法
//根据需求得到下标
public int getIndexByX(int x) {
return x;
}
- 这个需要根据实际需求
- 一般x与i是一致的
- 或者是x = ki + b(k属于整数)
- 对于其他特殊情况,你需要给每个节点安排下标
- 这一点只需要在传参的时候转化为下标即可
下面的代码都是认为传参的就是下标
1.2.4 获得根节点
public int findRoot(int x) {
if(x < 0) {
throw new IndexOutOfBoundsException("下标为负数");
}
while(elem[x] >= 0) {
x = elem[x];
}
return x;
}
- 如果是压缩后的并查集,直接返回elem[x]即可
- 如果不是,这需要溯源到根节点

1.2.5 两个节点建立联系
- 只要两个节点来自不同的树,那么就可以建立联系,即两个集合合并
- 如果来自同一棵树,什么也不做
注意:这里你可以选择x1合并x2,或者x2合并x1
//合并x1和x2
//设x1任然是根节点,x2连接到x1下
public void union(int x1, int x2) {
int index1 = findRoot(x1);
int index2 = findRoot(x2);
if(index1 == index2) {
return;//同一棵树
}else {
elem[index1] += elem[index2];
elem[index2] = index1;
}
}
例子:

1.2.6 判断两个节点是否在一个集合内
//判断是否在一个集合内
public boolean isSameSet(int x1, int x2) {
return findRoot(x1) == findRoot(x2);
}
1.2.7 计算集合的个数
//计算集合的个数
public int getSetCount() {
int count = 0;
for(int x : elem) {
if(x < 0) {
count++;
}
}
return count;
}
1.2.8 打印并查集
public void display() {
for(int x : elem) {
System.out.print(x + " ");
}
System.out.println();
}
1.3 并查集的应用
1.3.1 省份的数量
力扣547

是不是一模一样,^ v ^
分析:

代码:
//获得省份数量
public int findCircleNum(int[][] isConnected) {
int n = isConnected.length;
UnionFindSet unionFindSet = new UnionFindSet(n);
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
if(isConnected[i][j] == 1) {
unionFindSet.union(i, j);
}
}
}
return unionFindSet.getSetCount();
}

1.3.2 等式方程的可满足性
力扣990

分析:
思路:
- 区分不同的字符串种类(等于号类和不等号类)
- 通过等号类构建并查集
- 通过不等号类去检查是否合理
//下标转化方法(这道题节点最多26个,因为只能是不重复的小写字母)
public int getIndexByX(char x) {
return x - 'a';
}
//等式方程可满足性
public boolean equationsPossible(String[] equations) {
UnionFindSet unionFindSet = new UnionFindSet(26);
for(String str : equations) {
if(str.charAt(1) == '=') {
char ch1 = str.charAt(0);
char ch2 = str.charAt(3);
unionFindSet.union(getIndexByX(ch1), getIndexByX(ch2));
}
}
for(String str : equations) {
if(str.charAt(1) == '!') {
char ch1 = str.charAt(0);
char ch2 = str.charAt(3);
if(unionFindSet.isSameSet(getIndexByX(ch1), getIndexByX(ch2))) {
return false;
}
}
}
return true;
}

1.3.3 Kruskal算法获取图的最小生成树
这也是接下来要讲的
2. 图的最小生成树问题
对于图的基本知识,请参考博客:Java高阶数据结构 & 图 & 图的表示与遍历_s:103的博客-CSDN博客
下面不作赘述~
2.1 生成树是什么
连通图中的每一棵生成树,都是原图的一个极大无环子图,即:从其中删去任何一条边,生成树 就不在连 通;反之,在其中引入任何一条新边,都会形成一条回路。
若连通图由n个顶点组成,则其生成树必含n个顶点和n-1条边。因此构造最小生成树的准则有五 条:
- 只能由图中的边来构造最小生成树
- 只能使用恰好n-1条边来连接图中的n个顶点
- 选用的n-1条边不能构成回路
- 当然,都满足第2条,就一定不会构成回路
- n-1条边的权和最小
- 是连通图
- 只有连通无向图存在生成树
当然,最小生成树,可能不止一棵
2.2 获取最小生成树算法
贪心算法: 是指在问题求解时,总是做出当前看起来最好的选择。也就是说贪心算法做出的不是整体 最优的 的选择,而是某种意义上的局部最优解。贪心算法不是对所有的问题都能得到整体最优解。
以下两种算法的本质都是贪心算法,虽然数学上不严谨,却能很好的解决这个问题~
- 不需要纠结,用就是了
2.2.1 Kruskal算法
- 克鲁斯卡尔算法是全局的贪心算法
步骤:
- 选取全局中最短的边,并标记两个顶点
-
选取全局中未被标记的边(两个端点都未被标记)
- 如果几个一样小的,没关系,用哪个都ok
- 这也是为什么最小生成树可能不唯一的原因
- 以此类推…
- 在标价前要判断标记后是否成环,如果是,取消此次选择
- 直到选出n-1条边,此时计算结束
例子:
- 求一棵如下图的最小生成树

步骤如下:

2.2.2 Prime算法
- 普利姆算法的本质是局部的贪心算法
步骤:
- 确定并标记一个起始节点,后续树的生长以此为基础
- 生长:在此节点能直接连通的所有节点中,选择一条权最小的边,并标记该节点
-
继续生长:在树的所有节点能直接连通的所有节点中,选择一条权最小的边,并标记该节点
- 不能连通被标记的节点
- 无向连通图不会出现选不出来的情况
-
直到所有节点都被标记则结束,已生长成最小生成树
- 或者是获得了n-1条边,不成环则一定有n个节点
例子:
- 求一棵如下图以a的起始节点的最小生成树

步骤:

可见,不同算法求出来的最小生成树不同
2.3 获取最小生成树代码实现
通过刚才的算法讲解,其实思路不难,现在要解决的主要是算法转化为代码~
2.3.1 Kruskal算法代码实现(邻接矩阵)
待处理的问题:
- 怎么获得全场最短的边?
- 怎么保证不会成环
解决:
-
优先级队列 去存储所有的边,每次都取小根堆堆顶,这样可以高效的获取最小边
- 由于是全局的,所以不存在 “局部最小问题”
- 并查集 去整理节点之间的关系,如果一条边的两个节点是有关系(已在同一个图)的,就不能取
代码实现:
- Edge类的定义
static class Edge {
int src;
int dest;
int weight;
public Edge(int src, int dest, int weight) {
this.src = src;
this.dest = dest;
this.weight = weight;
}
}
- 导入并查集这个类(刚才实现的)

- 技巧:把代码复制直接粘贴就行了
- 这样会自动根据public类构建java文件

- 库鲁斯卡尔算法对应方法
/**
*
* @param minTree 最小生成树放在图 minTree中
* @return 最小生成树的权和
*/
public int kruskal(GraphByMatrix minTree) {
//1. 优先级序列存放所有边
PriorityQueue<Edge> minHeap = new PriorityQueue<Edge>(
(o1, o2) -> {
return o1.weight - o2.weight;
}
);
int n = matrix.length;
//无向图只需要一条即可
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
minHeap.offer(new Edge(i, j, matrix[i][j]));
}
}
//最终的权值和
int retWeight = 0;
//定义并查集
UnionFindSet unionFindSet = new UnionFindSet(n);
int size = 0;//已选边的条数
//选取n-1条边,如果不成环,必然选中n个节点,
// 如果队列都空了,都没有n-1条边,则不是无向连通图
while(size < n - 1 && !minHeap.isEmpty()) {
Edge minEdge = minHeap.poll();
int src = minEdge.src;
int dest = minEdge.dest;
//如果src与dest师出同门,不能添加
if(!unionFindSet.isSameSet(src, dest)) {
System.out.println(arrayV[src] +"--- "
+arrayV[dest]+" : "+matrix[src][dest]);
//这两个节点建立关系
unionFindSet.union(src, dest);
//存放在minTree图中,最小生成树返回到这里面
minTree.addEdge(arrayV[src], arrayV[dest], minEdge.weight);
//权值和
retWeight += minEdge.weight;
//被选中的边的条数加一
size++;
}
}
return size == n - 1 ? retWeight : Integer.MAX_VALUE;
}
测试:
- 建立图对象(跟上面的图解一致)
- 打印最小生成树权和以及最小生成树的邻接矩阵
public static void testGraphMinTree1() {
String str = "abcdefghi";
char[] array =str.toCharArray();
GraphByMatrix g = new GraphByMatrix(str.length(),false);
g.initArrayV(array);
g.addEdge('a', 'b', 4);
g.addEdge('a', 'h', 8);
//g.addEdge('a', 'h', 9);
g.addEdge('b', 'c', 8);
g.addEdge('b', 'h', 11);
g.addEdge('c', 'i', 2);
g.addEdge('c', 'f', 4);
g.addEdge('c', 'd', 7);
g.addEdge('d', 'f', 14);
g.addEdge('d', 'e', 9);
g.addEdge('e', 'f', 10);
g.addEdge('f', 'g', 2);
g.addEdge('g', 'h', 1);
g.addEdge('g', 'i', 6);
g.addEdge('h', 'i', 7);
GraphByMatrix kminTree = new GraphByMatrix(str.length(),false);
kminTree.initArrayV(array);
System.out.println(g.kruskal(kminTree));
kminTree.printGraph();
}
public static void main(String[] args) {
testGraphMinTree1();
}

2.3.2 Prime算法代码实现(邻接矩阵)
待处理问题:
- 怎么找到一条当前标记节点指向未标记节点的边
- 这条边怎么保证是最小的
解决:
-
由于这种算法明显分为了两种关系:被标记与未被标记
- 所以直接创建两个集合(HashSet)即可,不需要用到并查集
- 如果指向的顶点属于被标记过,则不能选择它
- 选择后目的顶点被标记,也让这条边不会再次被选中
-
一样可以用 优先级队列
-
每次一个顶点被标记的时候,都需要将这个顶点连接的所有边加入队列中
-
重复的有很多,但是由于刚才的机制,不会出现成环的现象
-
在这里队列是需要动态更新的,每次都为了找到“局部最小”
-
代码实现:
- 普利姆算法对应方法
public int prime(GraphByMatrix minTree, char V) {
//获取顶点的下标
int srcIndex = getIndexOfV(V);
//起始节点集合与目的节点集合
Set<Integer> srcSet = new HashSet<>();
Set<Integer> destSet = new HashSet<>();
//初始化两个集合
srcSet.add(srcIndex);
int n = matrix.length;
for (int i = 0; i < n; i++) {
if(i != srcIndex) {
destSet.add(i);
}
}
//从srcSet到destSet集合的边
//定义优先级队列与初始化优先级队列
PriorityQueue<Edge> minHeap = new PriorityQueue<>(
(o1, o2) -> {
return o1.weight - o2.weight;
//左大于右为正,为升序小根堆
}
);
for (int i = 0; i < n; i++) {
if(matrix[srcIndex][i] != Integer.MAX_VALUE) {
minHeap.offer(new Edge(srcIndex, i, matrix[srcIndex][i]));
}
}
int retWeight = 0;//返回的权值和
int edgeCount = 0;//已选中的边
//核心循环
while(edgeCount < n - 1 && !minHeap.isEmpty()) {
Edge minEdge = minHeap.poll();
int src = minEdge.src;
int dest = minEdge.dest;
//判断dest是否被标记
if(!srcSet.contains(dest)) {
minTree.addEdge(arrayV[src], arrayV[dest], matrix[src][dest]);
System.out.println(arrayV[src] + "---" + arrayV[dest] + " : "
+ matrix[src][dest]);
edgeCount++;
retWeight += matrix[src][dest];
//目的节点被标记:加入srcSet,在destSet除名
srcSet.add(dest);
destSet.remove(dest);
//添加新增起始顶点的所有直接连通的边
for (int i = 0; i < n; i++) {
//多重保证,安心!
if(matrix[dest][i] != Integer.MAX_VALUE && destSet.contains(i)) {
minHeap.offer(new Edge(dest, i, matrix[dest][i]));
}
}
}
}
return edgeCount == n - 1 ? retWeight : Integer.MAX_VALUE;
}
测试:
- 同上,只是把方法换成prime,并给定起始顶点
public static void testGraphMinTree2() {
String str = "abcdefghi";
char[] array =str.toCharArray();
GraphByMatrix g = new GraphByMatrix(str.length(),false);
g.initArrayV(array);
g.addEdge('a', 'b', 4);
g.addEdge('a', 'h', 8);
//g.addEdge('a', 'h', 9);
g.addEdge('b', 'c', 8);
g.addEdge('b', 'h', 11);
g.addEdge('c', 'i', 2);
g.addEdge('c', 'f', 4);
g.addEdge('c', 'd', 7);
g.addEdge('d', 'f', 14);
g.addEdge('d', 'e', 9);
g.addEdge('e', 'f', 10);
g.addEdge('f', 'g', 2);
g.addEdge('g', 'h', 1);
g.addEdge('g', 'i', 6);
g.addEdge('h', 'i', 7);
GraphByMatrix kminTree = new GraphByMatrix(str.length(),false);
kminTree.initArrayV(array);
System.out.println(g.prime(kminTree, 'a'));
kminTree.printGraph();
}
public static void main(String[] args) {
testGraphMinTree2();
}

这两个算法的代码可能比较难理解,你可以结合上面的图片和文字讲解去理解代码!
文章到此结束!谢谢观看
可以叫我 小马,我可能写的不好或者有错误,但是一起加油鸭🦆!文章来源:https://www.toymoban.com/news/detail-436892.html后续更新图的最短路径问题和拓扑排序,敬请期待!文章来源地址https://www.toymoban.com/news/detail-436892.html
到了这里,关于Java高阶数据结构 & 并查集 & 最小生成树的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!