1. 普通哈希算法
1.1 简介Hash
哈希算法即散列算法,是一种从任意文件中创造小的数字「指纹」的方法。与指纹一样,散列算法就是一种以较短的信息来保证文件唯一性的标志,这种标志与文件的每一个字节都相关,而且难以找到逆向规律。因此,当原有文件发生改变时,其标志值也会发生改变,从而告诉文件使用者当前的文件已经不是你所需求的文件。
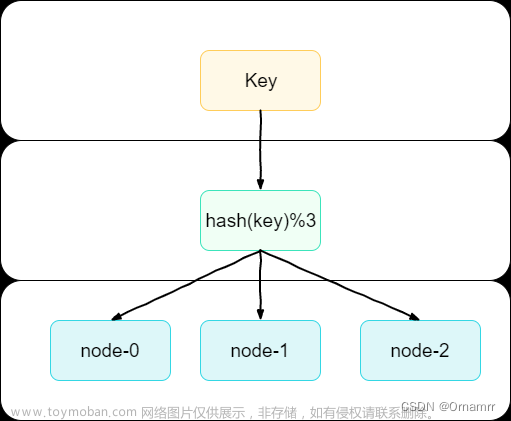
简单hash算法在实现上为:目标 target = hash(key)% 质数
1.2 普通Hash算法缺陷
举个例子:现在有一个数据库m1,要对一个user表进行水平拆分为user_0,user_1,user_2 三张表,如何进行合理的数据映射?
使用普通的hash算法的策略:
根据user的id进行hash运算,从而映射到对应的表,这时候 target = hash(key) % 3,即user_0 放的user的id都是 3的整数,同理user_1,user_2存放的user的id分别为 3余1,3余2…
如果随着业务的增加,user表要从原来的三个增为五个user表,上述表达式变为 target = hash(key) % 5, 这时所有记录的映射关系都会发生改变,导致我们需要对所有数据重新规整,放到对应的表中,这个任务量显然是巨大的…
2. 一致性哈希算法
一致性hash算法就是为了解决普通hash算法带来的痛点。
2.1 一致性hash算法原理
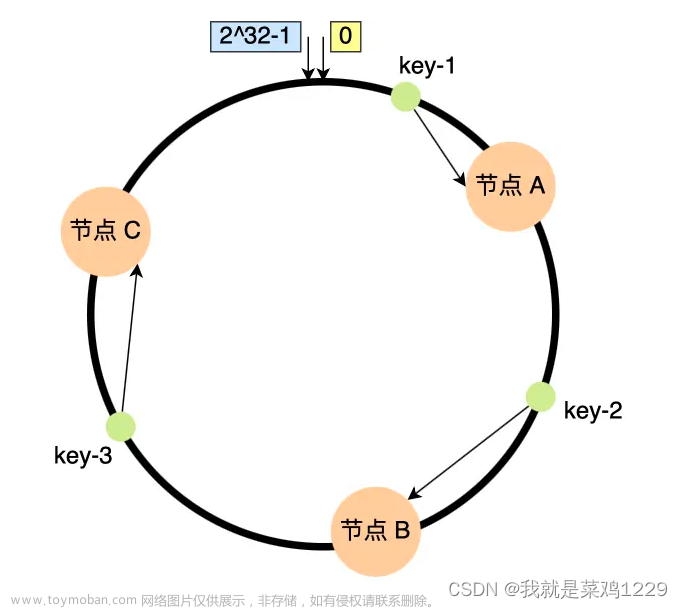
- 一致性Hash算法也是使用取模的方法,只是,刚才描述的取模法是对服务器的数量进行取模,而一致性Hash算法是对2^32取模,一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环,将各个服务器使用Hash进行计算,具体可以根据关键字进行哈希,这样每个记录就能确定其在哈希环上的位置。
可参考 https://blog.csdn.net/a745233700/article/details/120814088文章来源:https://www.toymoban.com/news/detail-436911.html
2.2 一致性hash算法的代码实现
具体的项目实践,可参考这篇博客 : Sharding-JDBC 一致性hash算法数据库分片实践文章来源地址https://www.toymoban.com/news/detail-436911.html
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.util.ArrayList;
import java.util.Collection;
import java.util.SortedMap;
import java.util.TreeMap;
public class ConsistentHashing {
// 一致性哈希算法中使用的哈希函数,默认使用FNV1_32_HASH
private HashFunction hashFunction;
// 虚拟节点个数
private int numberOfReplicas;
// 使用TreeMap来存储虚拟节点的哈希值和物理节点的映射关系
private SortedMap<Integer, String> circle = new TreeMap<>();
/**
* 构造函数,初始化哈希函数和虚拟节点个数
* @param hashFunction 哈希函数
* @param numberOfReplicas 虚拟节点个数
*/
public ConsistentHashing(HashFunction hashFunction, int numberOfReplicas) {
this.hashFunction = hashFunction;
this.numberOfReplicas = numberOfReplicas;
}
/**
* 添加物理节点
* @param node 物理节点名称
*/
public void addNode(String node) {
for (int i = 0; i < numberOfReplicas; i++) {
// 对于每个物理节点,根据其名称和编号生成一个虚拟节点,并将其添加到虚拟节点环中
int hashValue = hashFunction.getHash(node + i);
circle.put(hashValue, node);
}
}
/**
* 删除物理节点
* @param node 物理节点名称
*/
public void removeNode(String node) {
for (int i = 0; i < numberOfReplicas; i++) {
// 对于每个物理节点,根据其名称和编号生成一个虚拟节点,并将其从虚拟节点环中删除
int hashValue = hashFunction.getHash(node + i);
circle.remove(hashValue);
}
}
/**
* 根据给定的key选择一个物理节点
* @param key key
* @return 物理节点名称
*/
public String getNode(String key) {
if (circle.isEmpty()) {
return null;
}
int hashValue = hashFunction.getHash(key);
// 如果环中不存在大于该hash值的节点,则直接返回环中最小的节点
if (!circle.containsKey(hashValue)) {
SortedMap<Integer, String> tailMap = circle.tailMap(hashValue);
hashValue = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey();
}
return circle.get(hashValue);
}
/**
* 返回所有的物理节点
* @return
*/
public Collection<String> getAllNodes() {
return new ArrayList<>(circle.values());
}
/**
* 哈希函数接口
*/
public interface HashFunction {
int getHash(String key);
}
/**
* FNV1_32_HASH算法,使用32位的FNV做hash,对于相同的字符串,不同的种子会产生不同的hash值
*/
public static class FNV1_32_HASH implements HashFunction {
public int getHash(String key) {
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < key.length(); i++) {
hash = (hash ^ key.charAt(i)) * p;
}
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
return hash;
}
}
}
到了这里,关于一致性哈希算法优势在哪?如何实现?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!