前言
机器翻译(Machine Translation, MT)是一类将某种语言(源语言,source language)的句子 x x x翻译成另一种语言(目标语言,target language)的句子 y y y 的任务。机器翻译的相关研究早在上世纪50年代美苏冷战时期就开始了,当时的机器翻译系统是基于规则的,利用两种语言的单词、短语对应关系将俄语翻译成英语。
在早期的机器翻译主要是依靠统计学模型,使用一种叫统计机器翻译(Statistical Machine Translation, SMT)的方法,在1990年至2010年间是较为主流的方法,也取得了不错的效果。统计机器翻译方法的核心思想是从数据中统计出概率模型。假设需要构建一个将法语翻译成英语的模型,我们可以将任务描述为给定法语句子
x
x
x ,找到最有可能是
x
x
x 的翻译的英语句子
y
y
y,即
a
r
g
m
a
x
y
P
(
y
∣
x
)
=
a
r
g
m
a
x
y
P
(
x
∣
y
)
P
(
y
)
argmax_y P(y|x) = argmax_y P(x|y)P(y)
argmaxyP(y∣x)=argmaxyP(x∣y)P(y)
上式中的贝叶斯公式可分为两部分,其中
P
(
x
∣
y
)
P(x|y)
P(x∣y)可以看作翻译模型,保证翻译的正确性;
P
(
y
)
P(y)
P(y)则是语言模型,保证翻译结果语言流畅。在当时的技术条件下,这样拆分后两个任务相对独立,分开学习会更容易一些。
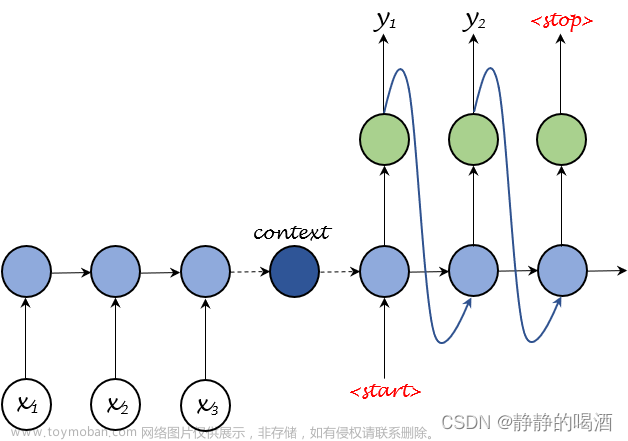
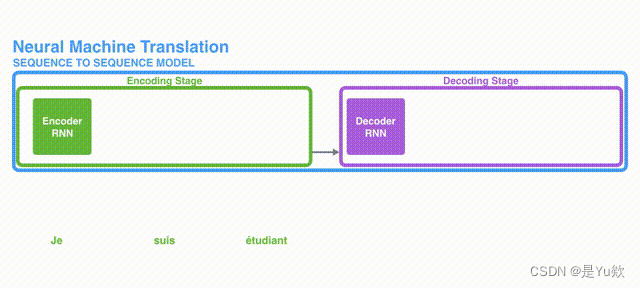
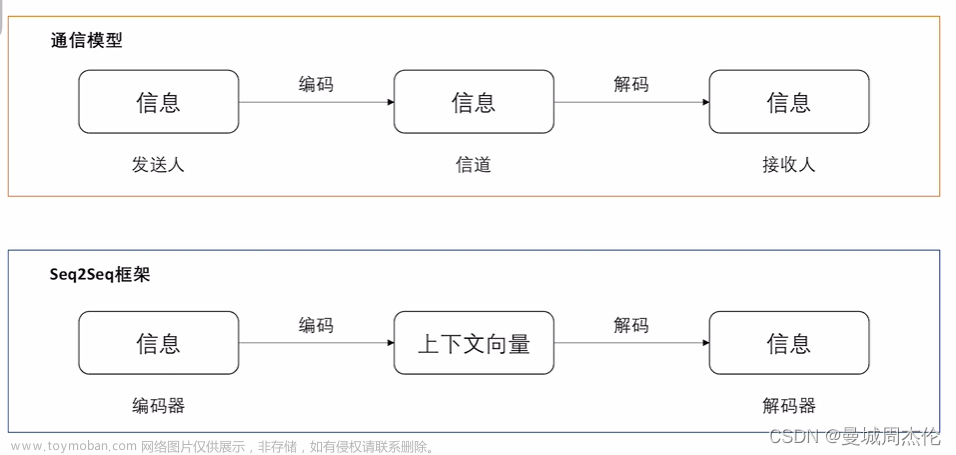
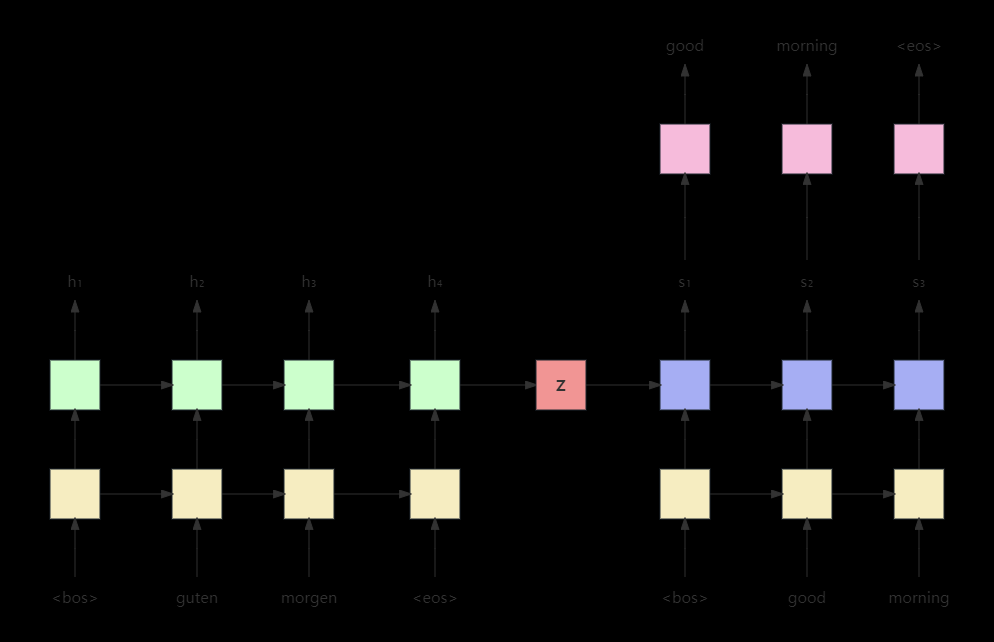
在2014年,机器翻译研究迎来了重大的突破——神经机器翻译(Neural Machine Translation, NMT)。最简单的NMT系统使用单个神经网络就可以完成机器翻译任务,这个神经网络结构就是Seq2Seq(sequence-to-sequence,序列到序列),它由两个RNN组成,其中一个作为Encoder(编码器),另一个则是Decoder(解码器),Encoder的输入为源语言的语句,经过RNN处理并在最后一步得到输出,这个输出就可以看作输入句子的向量编码。
本篇文章中用于机器翻译的网络结构仍然是Seq2Seq网络结构,但是与两个RNN或者RNN+attention方法不同,经过简单的修改的transformer会是这个序列模型的主要结构。
transformer这个模型,大家都比较熟悉了,由论文《Attention is All You Need》提出,主要是可以实现并行化的训练,网络结构主要由全连接层、注意力机制和normalization层组成。关于transformer的结构在这里就不详细介绍了,大家感兴趣的可以去看看别的博主的文章,这里主要介绍如何将transformer用于机器翻译的模型训练。
代码
数据处理
数据主要使用的是torchtext中含英语和德语句子对的知名数据集Multi30k dataset,其包含大约30,000个英语和德语的句子对(平均长度约为13)。下面代码是数据处理部分和相关依赖库导入:
import torch
import torch.nn as nn
import torch.optim as optim
import torchtext
from torchtext.datasets import Multi30k
#from torchtext.legacy.data import Field, BucketIterator # pytorch1.9+ torchtext==0.10.0
from torchtext.data import Field, TabularDataset, BucketIterator, Iterator ## torchtext==0.6.0 torch==1.7
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import numpy as np
import random
import math
import time
SEED = 1234
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
def tokenize_de(text):
"""
Tokenizes German text from a string into a list of strings
"""
return [w for w in text.split() if w]
def tokenize_en(text):
"""
Tokenizes English text from a string into a list of strings
"""
return [w for w in text.split() if w]
SRC = Field(tokenize=tokenize_de,
init_token='<sos>',
eos_token='<eos>',
lower=True,
batch_first=True)
TRG = Field(tokenize=tokenize_en,
init_token='<sos>',
eos_token='<eos>',
lower=True,
batch_first=True)
#train_data, valid_data, test_data = Multi30k() # pytorch1.9+ torchtext==0.10.0
train_data, valid_data, test_data = Multi30k.splits(exts = ('.de', '.en'), ## torchtext==0.6.0 torch==1.7
fields = (SRC, TRG))
SRC.build_vocab(train_data, min_freq = 2)
TRG.build_vocab(train_data, min_freq = 2)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print('device:', device)
BATCH_SIZE = 64
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_sizes=(BATCH_SIZE, BATCH_SIZE, BATCH_SIZE),
device=device,
sort_key=lambda x: len(x.src), # 根据源语句的长度
sort_within_batch=False, # 是否需要对批处理的内容进行排序
repeat=False
)
特别说明一下,数据导入,是直接从torchtext.datasets import的,但是torchtext版本不一样,api接口会有所变化,详细看代码里面注释,笔者这里用的torchtext 0.6.0, torch 1.7。
如果由于网络的原因,下载数据失败,可以在手动下载该数据集并放到与代码同级的.data/目录下即可。文章来源:https://www.toymoban.com/news/detail-437297.html
模型定义
class Encoder(nn.Module):
def __init__(self,
input_dim,
hid_dim,
n_layers,
n_heads,
pf_dim,
dropout,
device,
max_length = 100):
super().__init__()
self.device = device
self.tok_embedding = nn.Embedding(input_dim, hid_dim)
self.pos_embedding = nn.Embedding(max_length, hid_dim)
self.layers = nn.ModuleList([EncoderLayer(hid_dim,
n_heads,
pf_dim,
dropout,
device)
for _ in range(n_layers)])
self.dropout = nn.Dropout(dropout)
self.scale = torch.sqrt(torch.FloatTensor([hid_dim])).to(device)
def forward(self, src, src_mask):
#src = [batch size, src len]
#src_mask = [batch size, src len]
batch_size = src.shape[0]
src_len = src.shape[1]
pos = torch.arange(0, src_len).unsqueeze(0).repeat(batch_size, 1).to(self.device)
#pos = [batch size, src len]
src = self.dropout((self.tok_embedding(src) * self.scale) + self.pos_embedding(pos))
#src = [batch size, src len, hid dim]
for layer in self.layers:
src = layer(src, src_mask)
#src = [batch size, src len, hid dim]
return src
class EncoderLayer(nn.Module):
def __init__(self,
hid_dim,
n_heads,
pf_dim,
dropout,
device):
super().__init__()
self.layer_norm = nn.LayerNorm(hid_dim)
self.self_attention = MultiHeadAttentionLayer(hid_dim, n_heads, dropout, device)
self.positionwise_feedforward = PositionwiseFeedforwardLayer(hid_dim,
pf_dim,
dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, src, src_mask):
#src = [batch size, src len, hid dim]
#src_mask = [batch size, src len]
#self attention
_src, _ = self.self_attention(src, src, src, src_mask)
#dropout, residual connection and layer norm
src = self.layer_norm(src + self.dropout(_src))
#src = [batch size, src len, hid dim]
#positionwise feedforward
_src = self.positionwise_feedforward(src)
#dropout, residual and layer norm
src = self.layer_norm(src + self.dropout(_src))
#src = [batch size, src len, hid dim]
return src
class MultiHeadAttentionLayer(nn.Module):
def __init__(self, hid_dim, n_heads, dropout, device):
super().__init__()
assert hid_dim % n_heads == 0
self.hid_dim = hid_dim
self.n_heads = n_heads
self.head_dim = hid_dim // n_heads
self.fc_q = nn.Linear(hid_dim, hid_dim)
self.fc_k = nn.Linear(hid_dim, hid_dim)
self.fc_v = nn.Linear(hid_dim, hid_dim)
self.fc_o = nn.Linear(hid_dim, hid_dim)
self.dropout = nn.Dropout(dropout)
self.scale = torch.sqrt(torch.FloatTensor([self.head_dim])).to(device)
def forward(self, query, key, value, mask = None):
batch_size = query.shape[0]
#query = [batch size, query len, hid dim]
#key = [batch size, key len, hid dim]
#value = [batch size, value len, hid dim]
Q = self.fc_q(query)
K = self.fc_k(key)
V = self.fc_v(value)
#Q = [batch size, query len, hid dim]
#K = [batch size, key len, hid dim]
#V = [batch size, value len, hid dim]
Q = Q.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
K = K.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
V = V.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
#Q = [batch size, n heads, query len, head dim]
#K = [batch size, n heads, key len, head dim]
#V = [batch size, n heads, value len, head dim]
energy = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale
#energy = [batch size, n heads, query len, key len]
if mask is not None:
energy = energy.masked_fill(mask == 0, -1e10)
attention = torch.softmax(energy, dim = -1)
#attention = [batch size, n heads, query len, key len]
x = torch.matmul(self.dropout(attention), V)
#x = [batch size, n heads, query len, head dim]
x = x.permute(0, 2, 1, 3).contiguous()
#x = [batch size, query len, n heads, head dim]
x = x.view(batch_size, -1, self.hid_dim)
#x = [batch size, query len, hid dim]
x = self.fc_o(x)
#x = [batch size, query len, hid dim]
return x, attention
class PositionwiseFeedforwardLayer(nn.Module):
def __init__(self, hid_dim, pf_dim, dropout):
super().__init__()
self.fc_1 = nn.Linear(hid_dim, pf_dim)
self.fc_2 = nn.Linear(pf_dim, hid_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
#x = [batch size, seq len, hid dim]
x = self.dropout(torch.relu(self.fc_1(x)))
#x = [batch size, seq len, pf dim]
x = self.fc_2(x)
#x = [batch size, seq len, hid dim]
return x
class Decoder(nn.Module):
def __init__(self,
output_dim,
hid_dim,
n_layers,
n_heads,
pf_dim,
dropout,
device,
max_length = 100):
super().__init__()
self.device = device
self.tok_embedding = nn.Embedding(output_dim, hid_dim)
self.pos_embedding = nn.Embedding(max_length, hid_dim)
self.layers = nn.ModuleList([DecoderLayer(hid_dim,
n_heads,
pf_dim,
dropout,
device)
for _ in range(n_layers)])
self.fc_out = nn.Linear(hid_dim, output_dim)
self.dropout = nn.Dropout(dropout)
self.scale = torch.sqrt(torch.FloatTensor([hid_dim])).to(device)
def forward(self, trg, enc_src, trg_mask, src_mask):
#trg = [batch size, trg len]
#enc_src = [batch size, src len, hid dim]
#trg_mask = [batch size, trg len]
#src_mask = [batch size, src len]
batch_size = trg.shape[0]
trg_len = trg.shape[1]
pos = torch.arange(0, trg_len).unsqueeze(0).repeat(batch_size, 1).to(self.device)
#pos = [batch size, trg len]
trg = self.dropout((self.tok_embedding(trg) * self.scale) + self.pos_embedding(pos))
#trg = [batch size, trg len, hid dim]
for layer in self.layers:
trg, attention = layer(trg, enc_src, trg_mask, src_mask)
#trg = [batch size, trg len, hid dim]
#attention = [batch size, n heads, trg len, src len]
output = self.fc_out(trg)
#output = [batch size, trg len, output dim]
return output, attention
class DecoderLayer(nn.Module):
def __init__(self,
hid_dim,
n_heads,
pf_dim,
dropout,
device):
super().__init__()
self.layer_norm = nn.LayerNorm(hid_dim)
self.self_attention = MultiHeadAttentionLayer(hid_dim, n_heads, dropout, device)
self.encoder_attention = MultiHeadAttentionLayer(hid_dim, n_heads, dropout, device)
self.positionwise_feedforward = PositionwiseFeedforwardLayer(hid_dim,
pf_dim,
dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, trg, enc_src, trg_mask, src_mask):
#trg = [batch size, trg len, hid dim]
#enc_src = [batch size, src len, hid dim]
#trg_mask = [batch size, trg len]
#src_mask = [batch size, src len]
#self attention
_trg, _ = self.self_attention(trg, trg, trg, trg_mask)
#dropout, residual connection and layer norm
trg = self.layer_norm(trg + self.dropout(_trg))
#trg = [batch size, trg len, hid dim]
#encoder attention
_trg, attention = self.encoder_attention(trg, enc_src, enc_src, src_mask)
#dropout, residual connection and layer norm
trg = self.layer_norm(trg + self.dropout(_trg))
#trg = [batch size, trg len, hid dim]
#positionwise feedforward
_trg = self.positionwise_feedforward(trg)
#dropout, residual and layer norm
trg = self.layer_norm(trg + self.dropout(_trg))
#trg = [batch size, trg len, hid dim]
#attention = [batch size, n heads, trg len, src len]
return trg, attention
class Seq2Seq(nn.Module):
def __init__(self,
encoder,
decoder,
src_pad_idx,
trg_pad_idx,
device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.src_pad_idx = src_pad_idx
self.trg_pad_idx = trg_pad_idx
self.device = device
def make_src_mask(self, src):
#src = [batch size, src len]
src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2)
#src_mask = [batch size, 1, 1, src len]
return src_mask
def make_trg_mask(self, trg):
#trg = [batch size, trg len]
trg_pad_mask = (trg != self.trg_pad_idx).unsqueeze(1).unsqueeze(2)
#trg_pad_mask = [batch size, 1, 1, trg len]
trg_len = trg.shape[1]
trg_sub_mask = torch.tril(torch.ones((trg_len, trg_len), device = self.device)).bool()
#trg_sub_mask = [trg len, trg len]
trg_mask = trg_pad_mask & trg_sub_mask
#trg_mask = [batch size, 1, trg len, trg len]
return trg_mask
def forward(self, src, trg):
#src = [batch size, src len]
#trg = [batch size, trg len]
src_mask = self.make_src_mask(src)
trg_mask = self.make_trg_mask(trg)
#src_mask = [batch size, 1, 1, src len]
#trg_mask = [batch size, 1, trg len, trg len]
enc_src = self.encoder(src, src_mask)
#enc_src = [batch size, src len, hid dim]
output, attention = self.decoder(trg, enc_src, trg_mask, src_mask)
#output = [batch size, trg len, output dim]
#attention = [batch size, n heads, trg len, src len]
return output, attention
模型训练
INPUT_DIM = len(SRC.vocab)
OUTPUT_DIM = len(TRG.vocab)
HID_DIM = 256
ENC_LAYERS = 3
DEC_LAYERS = 3
ENC_HEADS = 8
DEC_HEADS = 8
ENC_PF_DIM = 512
DEC_PF_DIM = 512
ENC_DROPOUT = 0.1
DEC_DROPOUT = 0.1
enc = Encoder(INPUT_DIM,
HID_DIM,
ENC_LAYERS,
ENC_HEADS,
ENC_PF_DIM,
ENC_DROPOUT,
device)
dec = Decoder(OUTPUT_DIM,
HID_DIM,
DEC_LAYERS,
DEC_HEADS,
DEC_PF_DIM,
DEC_DROPOUT,
device)
SRC_PAD_IDX = SRC.vocab.stoi[SRC.pad_token]
TRG_PAD_IDX = TRG.vocab.stoi[TRG.pad_token]
model = Seq2Seq(enc, dec, SRC_PAD_IDX, TRG_PAD_IDX, device).to(device)
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
def initialize_weights(m):
if hasattr(m, 'weight') and m.weight.dim() > 1:
nn.init.xavier_uniform_(m.weight.data)
model.apply(initialize_weights)
LEARNING_RATE = 0.0005
optimizer = torch.optim.Adam(model.parameters(), lr = LEARNING_RATE)
criterion = nn.CrossEntropyLoss(ignore_index = TRG_PAD_IDX)
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.zero_grad()
output, _ = model(src, trg[:,:-1])
#output = [batch size, trg len - 1, output dim]
#trg = [batch size, trg len]
output_dim = output.shape[-1]
output = output.contiguous().view(-1, output_dim)
trg = trg[:,1:].contiguous().view(-1)
#output = [batch size * trg len - 1, output dim]
#trg = [batch size * trg len - 1]
loss = criterion(output, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
output, _ = model(src, trg[:,:-1])
#output = [batch size, trg len - 1, output dim]
#trg = [batch size, trg len]
output_dim = output.shape[-1]
output = output.contiguous().view(-1, output_dim)
trg = trg[:,1:].contiguous().view(-1)
#output = [batch size * trg len - 1, output dim]
#trg = [batch size * trg len - 1]
loss = criterion(output, trg)
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
N_EPOCHS = 10
CLIP = 1
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
valid_loss = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut6-model.pt')
print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')
最后训练输出: 文章来源地址https://www.toymoban.com/news/detail-437297.html
文章来源地址https://www.toymoban.com/news/detail-437297.html
到了这里,关于基于transformer的Seq2Seq机器翻译模型训练、预测教程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!