文章首发及后续更新:https://mwhls.top/4500.html,无图/无目录/格式错误/更多相关请至首发页查看。
新的更新内容请到mwhls.top查看。
欢迎提出任何疑问及批评,非常感谢!
服务部署汇总
本来这篇是为了打比赛写的,写着写着发现两个问题,AI部署连续几篇,等我比赛打完再发模型都不知道更新到哪个版本了。所以就直接发了。题图随便放个,我之后部属个文生图让它生成个。嘻嘻,蹭个热度
有问题推荐去 GitHub Issue,当然评论问我也行。2023/05/06更新:增加 API 调用及
ChatGLM
清华开源大模型-ChatGLM-2023/04/29
- ChatGLM_GitHub:THUDM/GLM: GLM (General Language Model)
- ChatGLM-6B_GitHub:THUDM/ChatGLM-6B: ChatGLM-6B: An Open Bilingual Dialogue Language Model | 开源双语对话语言模型
- 联系作者或可商用:关于ChatGLM模型的商用 · Issue #799 · THUDM/ChatGLM-6B
ChatGLM-6B 环境配置及启动-2023/04/29
- GitHub 官方教程
- 创建虚拟环境:
conda create --name ChatGLM python=3.8 - 进入虚拟环境:
conda activate ChatGLM - 下载源码:https://github.com/THUDM/ChatGLM-6B/archive/refs/heads/main.zip
- 进入该目录,安装依赖:
pip install -r requirements.txt - 安装 Torch:
conda install pytorch==1.12.0 torchvision==0.13.0 torchaudio==0.12.0 cudatoolkit=11.3 -c pytorch
- 这是我环境可以用的,不会的可以百度 PyTorch 安装。
- 下载模型
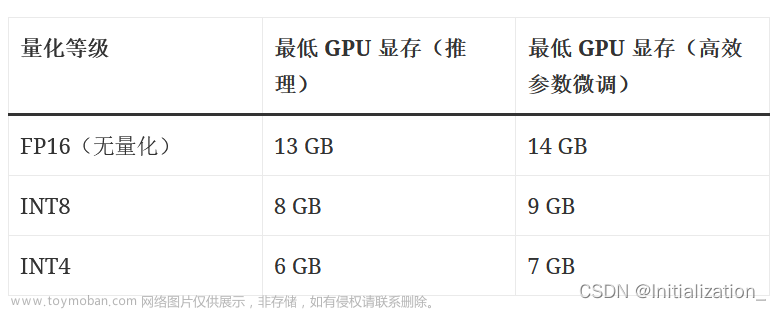
- 注:我下载的是int8量化的。
-
清华云
- 这里会缺少文件,下载后还要在HuggingFace里下载除了最大文件以外的所有文件(有一个重复,无需下载)。
- HuggingFace
- 文件修改:修改 web_demo.py 文件的开头几行如下,
pretrain_path指的是模型文件夹的绝对路径。 - 运行 web_demo.py,成功
pretrain_path = r"F:\0_DATA\1_DATA\CODE\PYTHON\202304_RJB_C4\ChatGLM\chatglm-6b-int8"
tokenizer = AutoTokenizer.from_pretrained(pretrain_path, trust_remote_code=True)
model = AutoModel.from_pretrained(pretrain_path, trust_remote_code=True).half().cuda()
ChatGLM Web demo 源码阅读-2023/04/30
- 涉及猜想,因为可以试错,所以有的地方可能不准确。
- 小加了两个模式,一个精准一个创造性,类似New Bing。
from transformers import AutoModel, AutoTokenizer
import gradio as gr
import mdtex2html
import os
pretrain_path = "chatglm-6b-int8"
pretrain_path = os.path.abspath(pretrain_path)
tokenizer = AutoTokenizer.from_pretrained(pretrain_path, trust_remote_code=True)
model = AutoModel.from_pretrained(pretrain_path, trust_remote_code=True).half().cuda()
model = model.eval()
"""Override Chatbot.postprocess"""
# 原来self还可以这样用,学习了
def postprocess(self, y):
if y is None:
return []
for i, (message, response) in enumerate(y):
y[i] = (
None if message is None else mdtex2html.convert((message)),
None if response is None else mdtex2html.convert(response),
)
return y
gr.Chatbot.postprocess = postprocess
def parse_text(text):
# markdown代码转html,我猜我博客的插件也是这样
"""copy from https://github.com/GaiZhenbiao/ChuanhuChatGPT/"""
lines = text.split("\n")
lines = [line for line in lines if line != ""]
count = 0
for i, line in enumerate(lines):
if "```" in line:
count += 1
items = line.split('`')
if count % 2 == 1:
lines[i] = f'<pre><code class="language-{items[-1]}">'
else:
lines[i] = f'<br></code></pre>'
else:
if i > 0:
if count % 2 == 1:
line = line.replace("`", "\`")
line = line.replace("<", "<")
line = line.replace(">", ">")
line = line.replace(" ", " ")
line = line.replace("*", "*")
line = line.replace("_", "_")
line = line.replace("-", "-")
line = line.replace(".", ".")
line = line.replace("!", "!")
line = line.replace("(", "(")
line = line.replace(")", ")")
line = line.replace("$", "$")
lines[i] = "<br>"+line
text = "".join(lines)
return text
# def set_mode(temperatrue_value, top_p_value):
# return gr.Slider.update(value=temperatrue_value), gr.update(value=top_p_value)
def set_mode(radio_mode):
# 不理解,为什么点击按钮就不能传过去,用这玩意就可以传
mode = {"创造性": [0.95, 0.7],
"精准": [0.01, 0.01]}
return gr.Slider.update(value=mode[radio_mode][0]), gr.update(value=mode[radio_mode][1])
def predict(input, chatbot, max_length, top_p, temperature, history):
# 新增一项
chatbot.append((parse_text(input), ""))
for response, history in model.stream_chat(tokenizer, input, history, max_length=max_length, top_p=top_p,
temperature=temperature):
# 新增的那项修改为推理结果
chatbot[-1] = (parse_text(input), parse_text(response))
yield chatbot, history
def reset_user_input():
return gr.update(value='')
def reset_state():
return [], []
with gr.Blocks() as demo:
gr.HTML("""<h1 align="center">ChatGLM</h1>""")
# 聊天记录器
chatbot = gr.Chatbot()
# 同一行内,第一行
with gr.Row():
# 第一列
with gr.Column(scale=4):
# 第一列第一行,输入框
with gr.Column(scale=12):
user_input = gr.Textbox(show_label=False, placeholder="Input...", lines=10).style(
container=False)
# 第一列第二行,提交按钮
with gr.Column(min_width=32, scale=1):
submitBtn = gr.Button("Submit", variant="primary")
# 第二列
with gr.Column(scale=1):
with gr.Row():
# with gr.Column():
# button_accuracy_mode = gr.Button("精准")
# with gr.Column():
# button_creative_mode = gr.Button("创造性")
radio_mode = gr.Radio(label="对话模式", choices=["精准", "创造性"], show_label=False)
# 靠右的四个输入
emptyBtn = gr.Button("清除历史")
max_length = gr.Slider(0, 4096, value=2048, step=1.0, label="Maximum length", interactive=True)
top_p = gr.Slider(0, 1, value=0.7, step=0.01, label="Top P", interactive=True)
temperature = gr.Slider(0, 1, value=0.95, step=0.01, label="Temperature", interactive=True)
# 历史记录
history = gr.State([])
# 按钮点击后,执行predict,并将第二个参数[...]传给predict,将predict结果传给第三个参数[...]
submitBtn.click(predict, [user_input, chatbot, max_length, top_p, temperature, history], [chatbot, history], show_progress=True)
submitBtn.click(reset_user_input, [], [user_input])
# 将reset_state的结果传给outputs
emptyBtn.click(reset_state, outputs=[chatbot, history], show_progress=True)
radio_mode.change(set_mode, radio_mode, [temperature, top_p])
# button_accuracy_mode.click(set_mode, [0.95, 0.7], outputs=[temperature, top_p])
# button_creative_mode.click(set_mode, [0.01, 0.01], outputs=[temperature, top_p])
# 这玩意debug不会用啊
demo.queue().launch(share=False, inbrowser=False)
ChatGLM API 调用-2023/05/05
- 官方文档:THUDM/ChatGLM-6B: ChatGLM-6B: An Open Bilingual Dialogue Language Model | 开源双语对话语言模型
- 修改 ChatGLM/api.py :
- 模型存储位置。
- 主机地址。
- 最后一行
host='0.0.0.0'为host='localhost'。 - 即
uvicorn.run(app, host='localhost', port=8000, workers=1)
- 最后一行
if __name__ == '__main__':
pretrain_path = "chatglm-6b-int8"
pretrain_path = os.path.abspath(pretrain_path)
tokenizer = AutoTokenizer.from_pretrained(pretrain_path, trust_remote_code=True)
model = AutoModel.from_pretrained(pretrain_path, trust_remote_code=True).half().cuda()
model.eval()
uvicorn.run(app, host='localhost', port=8000, workers=1)
- 使用 python requests 包的调用示例
import requests
url = "http://localhost:8000"
data = {"prompt": "你好", "history": []}
headers = {'Content-Type': 'application/json'}
response = requests.post(url, json=data, headers=headers)
print(response.text)
- 实际上我还写了一个专门的类,不过还没开源到 GitHub 上,可能过几天会更新:asd123pwj/asdTools: Simple tools for simple goals
闻达
- 不会用,下面可以不用看。
介绍-2023/05/02
- l15y/wenda: 闻达:一个LLM调用平台。为小模型外挂知识库查找和设计自动执行动作,实现不亚于于大模型的生成能力
- 昨晚看视频的时候发现 GPT 读取本地文档的,发现了 fess 的方案,进而发现了这个闻达库,NB。
懒人包-2023/05/02
- 作者有提供懒人包,B站也有人做教程,我没用过,没流量,流量全用来下游戏删游戏下游戏删游戏下游戏删游戏下游戏删游戏了。
部署-2023/05/02
- 考虑到作者都搞懒人包了,手动部署的应该都是自己会的,我就简单说下我的部署操作。
- 复制example.config.xml作为config.xml,并对应修改。
- 修改envirment.bat,注释掉懒人包路径,修改自己的python路径,如下,注释掉的我就不放出来了
chcp 65001
title 闻达
set "PYTHON=F:\0_DATA\2_CODE\Anaconda\envs\ChatGLM\python.exe "
:end
我是废物,改用懒人包-2023/05/02
- 不知道怎么用本地文档搜索和网络搜索,搞不懂搞不懂,又去下了懒人包。
- 可是为什么还是没有哇。
fess安装-2023/05/02
-
闻达要安装 fess,但是懒人包好像没有?
-
codelibs/fess: Fess is very powerful and easily deployable Enterprise Search Server. - https://github.com/codelibs/fess - https://github.com/codelibs/fess/releases/tag/fess-14.7.0 - https://github.com/codelibs/fess文章来源:https://www.toymoban.com/news/detail-437393.html
-
安装:Elasticsearch文章来源地址https://www.toymoban.com/news/detail-437393.html
- 这玩意好像商用要收费,算了,咱不用闻达了,看看它源码怎么写的算了。心好累。我是废物。
到了这里,关于AI模型部署记录(一)-ChatGLM:清华开源本地部署(2023/05/06更新)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!