前言
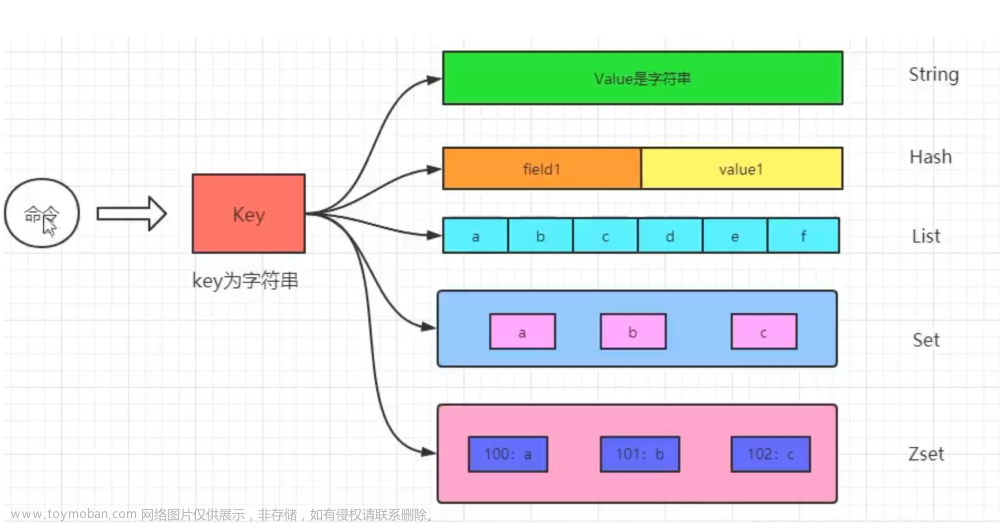
Redis是一种高性能的键值型数据库,它支持多种数据结构,其中一种是set类型。set类型可以存储一个无序的、不重复的字符串集合,类似于Java中的HashSet或Python中的set。set类型的优点是可以对集合进行快速的添加、删除、判断是否存在等操作,以及对多个集合进行交集、并集、差集等操作。
set
概述
在讲解set结构之前,需要先说明一下set结构编码的更替,如下
- 在
Redis7.2之前,set使用的是intset和hashtable - 在
Redis7.2之后,set使用的是intset、listpack、hashtable
intset
intset是一种紧凑的数组结构,它只保存int类型的数据,它将所有的元素按照从小到大的顺序存储在一块连续的内存中。intset会根据传入的数据大小,encoding分为int16_t、int32_t、int64_t

下图为命令所显示的编码结构
127.0.0.1:6379> sadd set 123
(integer) 1
127.0.0.1:6379> object encoding set
"intset"
127.0.0.1:6379> sadd set abcd
(integer) 1
127.0.0.1:6379> object encoding set
"hashtable"
intset 和 hashtable 的转换
在Redis7.2之前,当一个集合满足以下两个条件时,Redis 会选择使用intset编码:
- 集合对象保存的所有元素都是整数值
- 集合对象保存的元素数量小于等于
512个(默认)
intset最大元素数量可在redis.conf配置
set-max-intset-entries 512
为什么加入了listpack
在redis7.2之前,sds类型的数据会直接放入到编码结构式为hashtable的set中。其中,sds其实就是redis中的string类型。
而在redis7.2之后,sds类型的数据,首先会使用listpack结构当 set 达到一定的阈值时,才会自动转换为hashtable。
添加listpack结构是为了提高内存利用率和操作效率,因为 hashtable 的空间开销和碰撞概率都比较高。
hashtable 的空间开销高
hashtable 的空间开销高是因为它需要预先分配一个固定大小的数组来存储键值对,而这个数组的大小通常要大于实际存储的元素个数,以保证较低的装载因子。装载因子是指 hashtable 中已经存储的元素个数和数组大小的比值,它反映了 hashtable 的空间利用率
- 如果装载因子过高,那么 hashtable 的性能会下降,因为碰撞的概率会增加
- 如果装载因子过低,那么 hashtable 的空间利用率会下降,因为数组中会有很多空闲的位置
因此,hashtable 需要在装载因子和空间利用率之间做一个平衡,通常装载因子的推荐值是 0.75
hashtable 的碰撞概率高
hashtable 的碰撞概率高是因为它使用了一个散列函数来将任意长度的键映射到一个有限范围内的整数,作为数组的索引
散列函数的设计很重要,它应该尽可能地保证不同的键能够均匀地分布在数组中,避免出现某些位置过于拥挤,而其他位置过于稀疏的情况。然而,由于散列函数的输出范围是有限的,而键的取值范围是无限的,所以不可能完全避免两个不同的键被散列到同一个位置上,这就产生了碰撞。碰撞会影响 hashtable 的性能,因为它需要额外的处理方式来解决冲突,比如开放寻址法或者链地址法
举例说明,假设有一个大小为8的hashtable,使用取模运算作为散列函数,即h(k) = k mod 8。现在有四个键:5,13,21,29,它们都被散列到索引1处
这就是一个碰撞的例子,因为四个键都映射到了同一个索引。这种情况可能是由于以下原因造成的:
- 散列函数的选择不合适,没有充分利用hashtable的空间。
- 键的分布不均匀,有些区间的键出现的频率更高。
- hashtable的大小太小,不能容纳所有的键。
为了解决碰撞,redis采用了链地址法。就是在每个索引处维护一个链表,存储所有散列到该索引的键。但是,如果链表过长,查找效率会降低。因此,一般建议保持hashtable的负载因子(即键的数量除以hashtable的大小)在一定范围内,比如0.5到0.75之间。如果负载因子过高或过低,可以通过扩容或缩容来调整hashtable的大小
intset 、listpack和hashtable的转换
intset 、listpack和hashtable这三者的转换时根据要添加的数据、当前set的编码和阈值决定的。
-
如果要添加的数据是整型,且当前
set的编码为intset,如果超过阈值由intset直接转为hashtable阈值条件为:
set-max-intset-entries,intset最大元素个数,默认512 -
如果要添加的数据是字符串,分为三种情况
- 当前
set的编码为intset:如果没有超过阈值,转换为listpack;否则,直接转换为hashtable - 当前
set的编码为listpack:如果超过阈值,就转换为hashtable - 当前
set的编码为hashtable:直接插入,编码不会进行转换
阈值条件为:
set-max-listpack-entries:最大元素个数,默认128set_max_listpack_value:最大元素大小,默认64
以上两个条件需要同时满足才能进行编码转换 - 当前
总结
Redis set类型是一种可以存储一个无序的、不重复的字符串集合的数据结构,它有以下特点:文章来源:https://www.toymoban.com/news/detail-437481.html
- 可以对集合进行添加、删除、判断是否存在等操作,时间复杂度都是O (1)
- 可以对多个集合进行交集、并集、差集等操作,时间复杂度和集合元素个数有关
- 可以用作标签、好友关系、共同爱好等场景
系列文章目录
Redis内存优化——String类型介绍及底层原理详解
Redis内存优化——Hash类型介绍及底层原理详解
Redis内存优化——List类型介绍及底层原理详解
Redis内存优化——Set类型介绍及底层原理详解
Redis内存优化——ZSet类型介绍及底层原理详解
Redis内存优化——Stream类型介绍及底层原理详解
Redis内存优化——Hyperloglog、GEO、Bitmap、Bitfield类型详解
Redis的三种持久化策略及选取建议文章来源地址https://www.toymoban.com/news/detail-437481.html
到了这里,关于Redis高可用系列——Set类型底层详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!