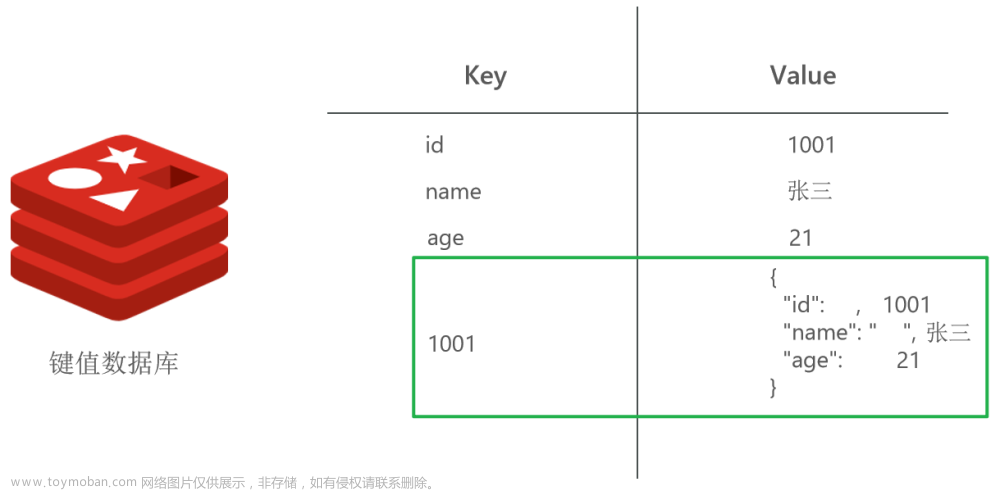
一、字符 string
Redis常用基本类型之一,存入Redis的所有key都是字符类型,常用于保存Session信息
| 命令 | 含义 | 复杂度 |
| set <key> <value> | 设置 key value | o (1) |
| get <key> | 获取 key 对应的 value 值 | o (1) |
| del <key> | 删除 key | o (1) |
| setnx <key> <value> | key 不存在时创建 key | o (1) |
| senxx <key> <value> | key 存在时更新 key 值 | o (1) |
| incr <key> | 计数加操作 | o (1) |
| decr <key> | 计数减操作 | o (1) |
| mset <key> <value> <key> <value> <key> <value> | 批量设置 key value | o (n) |
| mget <key> <key> <key> | 批量获取 key 对应的 value 值 | o (n) |
1、SET 创建字符类型的 key
SET key value [EX seconds] [PX milliseconds] [NX|XX]
可用版本: >= 1.0.0时间复杂度: O(1)将字符串值
value关联到key。如果
key已经持有其他值,SET就覆写旧值, 无视类型。当
SET命令对一个带有生存时间(TTL)的键进行设置之后, 该键原有的 TTL 将被清除。可选参数
从 Redis 2.6.12 版本开始,
SET命令的行为可以通过一系列参数来修改:
EX seconds: 将键的过期时间设置为seconds秒。 执行SET key value EX seconds的效果等同于执行SETEX key seconds value。
PX milliseconds: 将键的过期时间设置为milliseconds毫秒。 执行SET key value PX milliseconds的效果等同于执行PSETEX key milliseconds value。
NX: 只在键不存在时, 才对键进行设置操作。 执行SET key value NX的效果等同于执行SETNX key value。
XX: 只在键已经存在时, 才对键进行设置操作。
127.0.0.1:6379> set key1 value1 #设置key value 值,无论是否存在都执行 OK 127.0.0.1:6379> type key1 #查看key的数据类型 string 127.0.0.1:6379> set key2 value2 ex 3 #设置有效期为3s的key OK 127.0.0.1:6379> set key3 value3 nx #当key值不存在时创建key,相当于新增key OK 127.0.0.1:6379> set key3 value3 nx (nil) 127.0.0.1:6379> set key4 value4 xx #当key值存在时对key的值进行更新,相当于更新key (nil) 127.0.0.1:6379> set key4 value4 nx OK 127.0.0.1:6379> set key4 value_4 xx OK
2、GET 获取一个key的内容
127.0.0.1:6379> get key1 "value1" 127.0.0.1:6379> get key3 "value3"
3、DEL 删除一个和多个key
127.0.0.1:6379> keys * 1) "key3" 2) "key2" 3) "key1" 127.0.0.1:6379> del key1 key2 (integer) 2 127.0.0.1:6379> keys * 1) "key3" 127.0.0.1:6379> del key3 (integer) 1 127.0.0.1:6379> keys * (empty list or set) 127.0.0.1:6379>
4、MSET 批量创建多个key
127.0.0.1:6379> mset key1 value1 key2 value2 key3 value3 OK
5、MGET 批量获取多个key
127.0.0.1:6379> mget key1 key2 key3 #获取多个key对应的value值 1) "value1" 2) "value2" 3) "value3" 127.0.0.1:6379> keys ke* #获取ke开头的所有key 1) "key3" 2) "key2" 3) "key1" 127.0.0.1:6379> keys * #获取所有key 1) "key3" 2) "key2" 3) "key1"
6、APPEND 追加内容
127.0.0.1:6379> append key1 " this is append" (integer) 21 127.0.0.1:6379> get key1 "value1 this is append" 127.0.0.1:6379>
7、GETSET 设置新值并返回旧值
127.0.0.1:6379> set key4 value4 OK 127.0.0.1:6379> getset key4 newdata4 "value4" 127.0.0.1:6379> get key4 "newdata4"
8、STRLEN 返回字符串key对应的字符数
127.0.0.1:6379> set name janzen.qiu OK 127.0.0.1:6379> get name "janzen.qiu" 127.0.0.1:6379> strlen name (integer) 10 127.0.0.1:6379> set addr 深圳市¸ OK 127.0.0.1:6379> get addr "\xe6\xb7\xb1\xe5\x9c\xb3\xe5\xb8\x82\xb8\x82" 127.0.0.1:6379> strlen addr (integer) 11
9、EXISTS 判断key是否存在
127.0.0.1:6379> keys * 1) "key3" 2) "key4" 3) "name" 4) "addr" 5) "key2" 6) "key1" 127.0.0.1:6379> exists key (integer) 0 127.0.0.1:6379> exists key1 key2 (integer) 2
10、TTL 查看key值过期时间
#TTL <key> 可以查看key剩余有效期单位为s,过期后的key会被自动删除 #-1:表示永不过期,默认key的有效期都为永不过期 #-2:表示指定key不存在
127.0.0.1:6379> ttl keytemp (integer) 54 127.0.0.1:6379> ttl keytemp (integer) 52 127.0.0.1:6379> ttl keytemp (integer) 51 127.0.0.1:6379> ttl key1 (integer) -1 127.0.0.1:6379> ttl key (integer) -2 127.0.0.1:6379>
11、EXPIRE 重新设置key过期时间
127.0.0.1:6379> ttl keytemp (integer) 196 127.0.0.1:6379> expire keytemp 800 #expire 命令结果为重置过期时间 (integer) 1 127.0.0.1:6379> ttl keytemp (integer) 799 127.0.0.1:6379> ttl keytemp (integer) 793 127.0.0.1:6379> expire keytemp 400 (integer) 1 127.0.0.1:6379> ttl keytemp (integer) 399 127.0.0.1:6379>
12、PERSIST 取消key值过期时间
127.0.0.1:6379> ttl keytemp (integer) 333 127.0.0.1:6379> persist keytemp (integer) 1 127.0.0.1:6379> ttl keytemp (integer) -1
13、INCR 数值加计算
可利用INCR命令簇(INCR、INCRBY、INCRBYFLOAT)对可转化为数值的字符类型进行加计算
INCR <key> :对可转化为整形的字符进行递增加1(效果等同于 INCRBY KEY 1),如果key不存在则初始化key为0后进行处理
INCRBY <key> <int>:对可转化为整形的字符进行增加 int ,如果key不存在则初始化key为0后进行处理
INCRBYFLOAT <key> <float>:对可转化为 整形或浮点数 的字符进行增加 float ,如果key不存在则初始化key为0后进行处理
127.0.0.1:6379> set num 100 OK
#递增+1 127.0.0.1:6379> incr num (integer) 101 127.0.0.1:6379> incr num (integer) 102
#初始化key之后递增+1 127.0.0.1:6379> incr num1 (integer) 1
#数值加计算 127.0.0.1:6379> incrby num 20 (integer) 122 127.0.0.1:6379> incrby num -15 (integer) 107
#初始化key后,进行加计算
127.0.0.1:6379> incrby num2 24 (integer) 24
#初始化key,进行浮点数加计算 127.0.0.1:6379> incrbyfloat numf 20.1 "20.1"
#浮点数加计算 127.0.0.1:6379> incrbyfloat numf 2.8 "22.9" 127.0.0.1:6379> incrbyfloat numf -3.4 "19.5" 127.0.0.1:6379> incrbyfloat numf -10 "9.5" 127.0.0.1:6379> incrbyfloat numf 20 "29.5"
14、DECR 数值减计算
可利用DECR命令簇(DECR、DECRBY)对可转化为整形的字符类型进行加计算(不可处理浮点型内容)
DECR <key> :对可转化为整形的字符进行递减1(效果等同于 DECRBY KEY 1),如果key不存在则初始化key为0后进行处理
DECRBY <key> <int>:对可转化为整形的字符减 int ,如果key不存在则初始化key为0后进行处理
#初始化key,进行递减-1 127.0.0.1:6379> decr num3 (integer) -1
#递减-1 127.0.0.1:6379> decr num3 (integer) -2
#初始化key,进行减计算 127.0.0.1:6379> decrby num4 20 (integer) -20 #减计算 127.0.0.1:6379> decrby num3 10 (integer) -12 127.0.0.1:6379> decrby num3 -20 (integer) 8 #不可处理浮点型内容 127.0.0.1:6379> get numf "29.5" 127.0.0.1:6379> decr numf (error) ERR value is not an integer or out of range 127.0.0.1:6379> decrby numf 10 (error) ERR value is not an integer or out of range
二、列表 list

列表类型本质上是一个可双向读写的的管道,头部为左侧,尾部为右侧。一个列表最多可包含 2^32-1(4294967295)个元素,0为初始下标表示第一个元素,也可使用-1 表示最后一个元素的下标,元素值可以重复。
常用于日志和队列场景。
列表特点:
- 有序性
- 元素可重复
- 左右双向可操作
1、LPUSH RPUSH 生成列表并插入数据
LPUSH key value [value …]
可用版本: >= 1.0.0
时间复杂度: O(1)
将一个或多个值
value插入到列表key的表头如果有多个
value值,那么各个value值按从左到右的顺序依次插入到表头: 比如说,对空列表mylist执行命令LPUSH mylist a b c,列表的值将是c b a,这等同于原子性地执行LPUSH mylist a、LPUSH mylist b和LPUSH mylist c三个命令。如果
key不存在,一个空列表会被创建并执行 LPUSH 操作,当key存在但不是列表类型时,返回一个错误。LPUSHX key value
可用版本: >= 2.2.0
时间复杂度: O(1)
将值
value插入到列表key的表头,当且仅当key存在并且是一个列表。和 LPUSH key value [value …] 命令相反,当
key不存在时, LPUSHX 命令什么也不做。

RPUSH key value [value …]
可用版本: >= 1.0.0时间复杂度: O(1)将一个或多个值value插入到列表key的表尾(最右边)。如果有多个value值,那么各个value值按从左到右的顺序依次插入到表尾:比如对一个空列表mylist执行RPUSH mylist a b c,得出的结果列表为a b c,等同于执行命令RPUSH mylist a、RPUSH mylist b、RPUSH mylist c。如果key不存在,一个空列表会被创建并执行 RPUSH 操作。当key存在但不是列表类型时,返回一个错误。RPUSHX key value
可用版本: >= 2.2.0时间复杂度: O(1)将值value插入到列表key的表尾,当且仅当key存在并且是一个列表。和 RPUSH key value [value …] 命令相反,当key不存在时, RPUSHX 命令什么也不做。

127.0.0.1:6379> lpush list1 a b c d e (integer) 5 127.0.0.1:6379> rpush list2 a b c d e (integer) 5
2、LPUSH RPUSH 向列表追加数据
127.0.0.1:6379> lpush list1 f (integer) 6
#从右边添加元素,其余元素将向左移动 127.0.0.1:6379> rpush list2 f (integer) 6
3、获取列表长度
LLEN key
可用版本: >= 1.0.0时间复杂度: O(1)返回列表
key的长度。如果
key不存在,则key被解释为一个空列表,返回0.如果
key不是列表类型,返回一个错误。
127.0.0.1:6379> llen list1 (integer) 6 127.0.0.1:6379> llen list2 (integer) 6
4、获取列表指定位置数据
LRANGE key start stop
可用版本: >= 1.0.0时间复杂度: O(S+N),S为偏移量start,N为指定区间内元素的数量。返回列表
key中指定区间内的元素,区间以偏移量start和stop指定。下标(index)参数
start和stop都以0为底,也就是说,以0表示列表的第一个元素,以1表示列表的第二个元素,以此类推。你也可以使用负数下标,以
-1表示列表的最后一个元素,-2表示列表的倒数第二个元素,以此类推。
LINDEX key index
可用版本: >= 1.0.0时间复杂度:O(N),N为到达下标index过程中经过的元素数量。因此,对列表的头元素和尾元素执行 LINDEX 命令,复杂度为O(1)。返回列表
key中,下标为index的元素。下标(index)参数
start和stop都以0为底,也就是说,以0表示列表的第一个元素,以1表示列表的第二个元素,以此类推。你也可以使用负数下标,以
-1表示列表的最后一个元素,-2表示列表的倒数第二个元素,以此类推。如果
key不是列表类型,返回一个错误。


127.0.0.1:6379> rpush list a b c d e (integer) 5
#查看单个指定位置的元素 127.0.0.1:6379> lindex list 0 "a" 127.0.0.1:6379> lindex list 1 "b" 127.0.0.1:6379> lindex list 2 "c" 127.0.0.1:6379> lindex list 3 "d" 127.0.0.1:6379> lindex list 4 "e"
#查看指定范围的元素 127.0.0.1:6379> lrange list 0 4 1) "a" 2) "b" 3) "c" 4) "d" 5) "e" 127.0.0.1:6379> lrange list 2 4 1) "c" 2) "d" 3) "e" 127.0.0.1:6379> lrange list 0 -1 #未知列表长度时,查看所有元素 1) "a" 2) "b" 3) "c" 4) "d" 5) "e"
#起始下标位置必须位于结束下标左侧 127.0.0.1:6379> lrange list -1 0 (empty list or set) 127.0.0.1:6379> lrange list -1 2 (empty list or set) 127.0.0.1:6379> lrange list 2 -5 (empty list or set)
5、修改列表指定索引值的元素
LSET key index value
可用版本: >= 1.0.0时间复杂度:对头元素或尾元素进行 LSET 操作,复杂度为 O(1)。其他情况下,为 O(N),N为列表的长度。将列表
key下标为index的元素的值设置为value。当
index参数超出范围,或对一个空列表(key不存在)进行 LSET 时,返回一个错误。

127.0.0.1:6379> lrange list 0 -1 1) "a" 2) "b" 3) "c" 4) "d" 5) "e" 127.0.0.1:6379> lset list 2 n OK 127.0.0.1:6379> lrange list 0 -1 1) "a" 2) "b" 3) "n" 4) "d" 5) "e"
6、移除列表数据
LPOP key
可用版本: >= 1.0.0
时间复杂度: O(1)移除并返回列表
key的头元素。
RPOP key
可用版本: >= 1.0.0
时间复杂度: O(1)
移除并返回列表
key的尾元素。


127.0.0.1:6379> rpush list a b c d e (integer) 5 #删除列表头元素 127.0.0.1:6379> lrange list 0 -1 1) "a" 2) "b" 3) "c" 4) "d" 5) "e" 127.0.0.1:6379> lpop list "a" 127.0.0.1:6379> lrange list 0 -1 1) "b" 2) "c" 3) "d" 4) "e" #删除列表尾元素 127.0.0.1:6379> lrange list 0 -1 1) "a" 2) "b" 3) "c" 4) "d" 5) "e" 127.0.0.1:6379> rpop list "e" 127.0.0.1:6379> lrange list 0 -1 1) "a" 2) "b" 3) "c" 4) "d"
LREM key count value
可用版本: >= 1.0.0时间复杂度: O(N),N为列表的长度。根据参数
count的值,移除列表中与参数value相等的元素。
count的值可以是以下几种:
count > 0: 从表头开始向表尾搜索,移除与value相等的元素,数量为count。
count < 0: 从表尾开始向表头搜索,移除与value相等的元素,数量为count的绝对值。
count = 0: 移除表中所有与value相等的值。



127.0.0.1:6379> lrange list 0 -1 1) "a" 2) "b" 3) "c" 4) "c" 5) "a" 6) "d" 7) "e" 8) "a" 9) "b" 10) "a" 11) "e" 12) "c" 13) "c" 14) "c" 15) "b" 127.0.0.1:6379> lrem list -3 c #从列表尾部开始删除3个为 c 的元素 (integer) 3 127.0.0.1:6379> lrange list 0 -1 1) "a" 2) "b" 3) "c" 4) "c" 5) "a" 6) "d" 7) "e" 8) "a" 9) "b" 10) "a" 11) "e" 12) "b" 127.0.0.1:6379> lrange list 0 -1 1) "a" 2) "b" 3) "c" 4) "c" 5) "a" 6) "d" 7) "e" 8) "a" 9) "b" 10) "a" 11) "e" 12) "b" 127.0.0.1:6379> lrem list 2 a #从列表头部开始删除2个为 a 的元素 (integer) 2 127.0.0.1:6379> lrange list 0 -1 1) "b" 2) "c" 3) "c" 4) "d" 5) "e" 6) "a" 7) "b" 8) "a" 9) "e" 10) "b" 127.0.0.1:6379> lrange list 0 -1 1) "b" 2) "c" 3) "c" 4) "d" 5) "e" 6) "a" 7) "b" 8) "a" 9) "e" 10) "b" 127.0.0.1:6379> lrem list 0 b #删除列表中所有为 b 的元素 (integer) 3 127.0.0.1:6379> lrange list 0 -1 1) "c" 2) "c" 3) "d" 4) "e" 5) "a" 6) "a" 7) "e"
RPOPLPUSH source destination
可用版本: >= 1.2.0时间复杂度: O(1)命令 RPOPLPUSH 在一个原子时间内,执行以下两个动作:
将列表
source中的最后一个元素(尾元素)弹出,并返回给客户端。将
source弹出的元素插入到列表destination,作为destination列表的的头元素。举个例子,你有两个列表
source和destination,source列表有元素a, b, c,destination列表有元素x, y, z,执行RPOPLPUSH source destination之后,source列表包含元素a, b,destination列表包含元素c, x, y, z,并且元素c会被返回给客户端。如果
source不存在,值nil被返回,并且不执行其他动作。如果
source和destination相同,则列表中的表尾元素被移动到表头,并返回该元素,可以把这种特殊情况视作列表的旋转(rotation)操作。


# source destination 为两个不同的列表
127.0.0.1:6379> lrange list1 0 -1 1) "a" 2) "b" 3) "c" 4) "d" 5) "e" 127.0.0.1:6379> lrange list2 0 -1 1) "a" 2) "b" 3) "c" 4) "d" 5) "e" 127.0.0.1:6379> rpoplpush list1 list2 "e" 127.0.0.1:6379> lrange list1 0 -1 1) "a" 2) "b" 3) "c" 4) "d" 127.0.0.1:6379> lrange list2 0 -1 1) "e" 2) "a" 3) "b" 4) "c" 5) "d" 6) "e"
#source destination 为同一个列表 127.0.0.1:6379> rpush list1 a b c d e (integer) 5 127.0.0.1:6379> lrange list1 0 -1 1) "a" 2) "b" 3) "c" 4) "d" 5) "e" 127.0.0.1:6379> rpoplpush list1 list1 "e" 127.0.0.1:6379> lrange list1 0 -1 1) "e" 2) "a" 3) "b" 4) "c" 5) "d"
#destination 列表不存在 127.0.0.1:6379> lrange list2 0 -1 1) "e" 2) "a" 3) "b" 4) "c" 5) "d" 6) "e" 127.0.0.1:6379> EXISTS list3 (integer) 0 127.0.0.1:6379> rpoplpush list2 list3 "e" 127.0.0.1:6379> lrange list2 0 -1 1) "e" 2) "a" 3) "b" 4) "c" 5) "d" 127.0.0.1:6379> lrange list3 0 -1 1) "e"
LTRIM key start stop
可用版本: >= 1.0.0时间复杂度: O(N),N为被移除的元素的数量。对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。
举个例子,执行命令
LTRIM list 0 2,表示只保留列表list的前三个元素,其余元素全部删除。下标(index)参数
start和stop都以0为底,也就是说,以0表示列表的第一个元素,以1表示列表的第二个元素,以此类推。你也可以使用负数下标,以
-1表示列表的最后一个元素,-2表示列表的倒数第二个元素,以此类推。当
key不是列表类型时,返回一个错误。LTRIM 命令通常和 LPUSH key value [value …] 命令或 RPUSH key value [value …] 命令配合使用,举个例子:
LPUSH log newest_log LTRIM log 0 99这个例子模拟了一个日志程序,每次将最新日志
newest_log放到log列表中,并且只保留最新的100项。注意当这样使用LTRIM命令时,时间复杂度是O(1),因为平均情况下,每次只有一个元素被移除。
超出范围的下标
超出范围的下标值不会引起错误。
如果
start下标比列表的最大下标end(LLEN list减去1)还要大,或者start>stop, LTRIM 返回一个空列表(因为 LTRIM 已经将整个列表清空)。如果
stop下标比end下标还要大,Redis将stop的值设置为end

127.0.0.1:6379> lrange list 0 -1 1) "a" 2) "b" 3) "c" 4) "d" 5) "e" 127.0.0.1:6379> ltrim list 1 3 OK 127.0.0.1:6379> lrange list 0 -1 1) "b" 2) "c" 3) "d"
#起始下标大于end 127.0.0.1:6379> lrange list 0 -1 1) "b" 2) "c" 3) "d" 4) "a" 5) "b" 6) "c" 7) "d" 8) "e" 127.0.0.1:6379> ltrim list 8 10 OK 127.0.0.1:6379> lrange list 0 -1 (empty list or set) #终止下标大于起始下标 127.0.0.1:6379> lrange list 0 -1 1) "a" 2) "b" 3) "c" 4) "d" 5) "e" 127.0.0.1:6379> ltrim list 3 0 OK 127.0.0.1:6379> lrange list 0 -1 (empty list or set)
使用DEL命令直接删除key
127.0.0.1:6379> rpush list a b c d e (integer) 5 127.0.0.1:6379> rpush list2 a b c d e (integer) 5 127.0.0.1:6379> keys * 1) "list" 2) "list2" 127.0.0.1:6379> del list (integer) 1 127.0.0.1:6379> del lisst2 (integer) 0 127.0.0.1:6379>
7、指定元素前后插入新元素
LINSERT key BEFORE|AFTER pivot value
可用版本: >= 2.2.0时间复杂度: O(N),N为寻找pivot过程中经过的元素数量。将值
value插入到列表key当中,位于值pivot之前或之后。当
pivot不存在于列表key时,不执行任何操作。当
key不存在时,key被视为空列表,不执行任何操作。


127.0.0.1:6379> rpush list a b c d e (integer) 5 127.0.0.1:6379> LRANGE list 0 -1 1) "a" 2) "b" 3) "c" 4) "d" 5) "e" 127.0.0.1:6379> linsert list before d test (integer) 6 127.0.0.1:6379> LRANGE list 0 -1 1) "a" 2) "b" 3) "c" 4) "test" 5) "d" 6) "e" 127.0.0.1:6379> rpush list1 a b c d e (integer) 5 127.0.0.1:6379> LRANGE list1 0 -1 1) "a" 2) "b" 3) "c" 4) "d" 5) "e" 127.0.0.1:6379> linsert list after c test (integer) 7 127.0.0.1:6379> LRANGE list1 0 -1 1) "a" 2) "b" 3) "c" 4) "test" 5) "d" 6) "e" 127.0.0.1:6379>
三、集合 set

集合Set 是字符String的无序集合,集合中的成员具有唯一性,可以在两个不同的集合中进行比较取值,常用于取值判断、统计、交集等场景,
集合特点:
- 无序性
- 元素唯一性
- 多集合处理
1、生成集合key
SADD key member [member …]
可用版本: >= 1.0.0时间复杂度: O(N),N是被添加的元素的数量。将一个或多个
member元素加入到集合key当中,已经存在于集合的member元素将被忽略。假如
key不存在,则创建一个只包含member元素作成员的集合
127.0.0.1:6379> sadd set1 item1 item2 item3 (integer) 3 127.0.0.1:6379> type set1 set
2、集合追加元素
#追加集合内容是只能追加集合中不存在的元素,已存在的元素将被忽略 127.0.0.1:6379> sadd set1 item3 item4 item5 (integer) 2
3、查看集合元素
SMEMBERS key
可用版本: >= 1.0.0时间复杂度: O(N),N为集合的基数。返回集合
key中的所有成员。
127.0.0.1:6379> smembers set1 1) "item3" 2) "item2" 3) "item4" 4) "item1" 5) "item5"
SISMEMBER key member
可用版本: >= 1.0.0时间复杂度: O(1)判断
member元素是否集合key的成员。返回值
如果
member元素是集合的成员,返回1。 如果member元素不是集合的成员,或key不存在,返回0。
127.0.0.1:6379> smembers set1 1) "item2" 2) "item5" 3) "item1" 4) "item3" 5) "item4"
#item2元素存在于列表set1 127.0.0.1:6379> sismember set1 item2 (integer) 1
#item9元素不存在与列表set1 127.0.0.1:6379> sismember set1 item9 (integer) 0
SRANDMEMBER key [count]
可用版本: >= 1.0.0时间复杂度: 只提供key参数时为 O(1) 。如果提供了count参数,那么为 O(N) ,N 为返回数组的元素个数。如果命令执行时,只提供了
key参数,那么返回集合中的一个随机元素。从 Redis 2.6 版本开始, SRANDMEMBER 命令接受可选的
count参数:
如果
count为正数,且小于集合基数,那么命令返回一个包含count个元素的数组,数组中的元素各不相同。如果count大于等于集合基数,那么返回整个集合。如果
count为负数,那么命令返回一个数组,数组中的元素可能会重复出现多次,而数组的长度为count的绝对值。该操作和 SPOP key 相似,但 SPOP key 将随机元素从集合中移除并返回,而 SRANDMEMBER 则仅仅返回随机元素,而不对集合进行任何改动。
返回值
只提供
key参数时,返回一个元素;如果集合为空,返回nil。 如果提供了count参数,那么返回一个数组;如果集合为空,返回空数组。
127.0.0.1:6379> smembers set1 1) "item2" 2) "item5" 3) "item1" 4) "item3" 5) "item4"
#未输入count值,默认随机返回1个元素 127.0.0.1:6379> srandmember set1 "item4"
#count<0,返回3个元素,允许出现重复值 127.0.0.1:6379> srandmember set1 -3 1) "item4" 2) "item3" 3) "item4"
#count>0,返回3个元素,结果允许出现重复值 127.0.0.1:6379> srandmember set1 3 1) "item2" 2) "item5" 3) "item3"
#count 大于列表中的元素个数,返回当前列表 127.0.0.1:6379> srandmember set1 9 1) "item3" 2) "item2" 3) "item5" 4) "item1" 5) "item4"
SCARD key
可用版本: >= 1.0.0时间复杂度: O(1)返回集合
key的基数(集合中元素的数量)。返回值
集合的基数。 当
key不存在时,返回0
127.0.0.1:6379> smembers set1 1) "item2" 2) "item5" 3) "item1" 4) "item3" 5) "item4" 127.0.0.1:6379> smembers set2 1) "item2" 2) "item9" 3) "item7" 4) "item1" 5) "item6" 6) "item4" 127.0.0.1:6379> scard set1 (integer) 5 127.0.0.1:6379> scard set2 (integer) 6
SSCAN cursor [MATCH pattern] [COUNT count]
可用版本: >= 2.8.0时间复杂度:增量式迭代命令每次执行的复杂度为 O(1) , 对数据集进行一次完整迭代的复杂度为 O(N) , 其中 N 为数据集中的元素数量。
SCAN命令及其相关的SSCAN命令、HSCAN命令和ZSCAN命令都用于增量地迭代(incrementally iterate)一集元素(a collection of elements)
127.0.0.1:6379> smembers set1 1) "item5" 2) "item1" 3) "item231" 4) "item132" 5) "item3" 6) "item13" 7) "item4" 8) "item2" 9) "item121" 10) "item81" #使用sscan筛选集合内元素 127.0.0.1:6379> sscan set1 0 match item?? 1) "7" 2) 1) "item81" 2) "item13" 127.0.0.1:6379> sscan set1 0 match item??? 1) "7" 2) 1) "item231" 2) "item132" 3) "item121" 127.0.0.1:6379> sscan set1 0 match item??1 1) "7" 2) 1) "item231" 2) "item121" 127.0.0.1:6379> sscan set1 0 match item*1 1) "7" 2) 1) "item231" 2) "item121" 3) "item81" 4) "item1"
4、删除集合中的元素
SREM key member [member …]
可用版本: >= 1.0.0时间复杂度: O(N),N为给定member元素的数量。移除集合
key中的一个或多个member元素,不存在的member元素会被忽略。
127.0.0.1:6379> smembers set1 1) "item3" 2) "item2" 3) "item4" 4) "item1" 5) "item5" 127.0.0.1:6379> srem set1 item1 item2 (integer) 2 127.0.0.1:6379> smembers set1 1) "item5" 2) "item3" 3) "item4" #删除不存在的元素,错误的元素会被忽略 127.0.0.1:6379> srem set1 item3 item6 item7 (integer) 1 127.0.0.1:6379> smembers set1 1) "item5" 2) "item4"
SPOP key
可用版本: >= 1.0.0时间复杂度: O(1)移除并返回集合中的一个随机元素。
如果只想获取一个随机元素,但不想该元素从集合中被移除的话,可以使用 SRANDMEMBER key [count] 命令。
返回值
被移除的随机元素。 当
key不存在或key是空集时,返回nil。
127.0.0.1:6379> smembers set2 1) "item2" 2) "item9" 3) "item7" 4) "item1" 5) "item6" 6) "item4" 127.0.0.1:6379> spop set2 "item4" 127.0.0.1:6379> smembers set2 1) "item2" 2) "item9" 3) "item7" 4) "item1" 5) "item6" 127.0.0.1:6379> spop set2 "item6" 127.0.0.1:6379> smembers set2 1) "item2" 2) "item9" 3) "item7" 4) "item1"
SMOVE source destination member
可用版本: >= 1.0.0时间复杂度: O(1)将
member元素从source集合移动到destination集合。SMOVE 是原子性操作。
如果
source集合不存在或不包含指定的member元素,则 SMOVE 命令不执行任何操作,仅返回0。否则,member元素从source集合中被移除,并添加到destination集合中去。当
destination集合已经包含member元素时, SMOVE 命令只是简单地将source集合中的member元素删除。当
source或destination不是集合类型时,返回一个错误。返回值
如果
member元素被成功移除,返回1。 如果member元素不是source集合的成员,并且没有任何操作对destination集合执行,那么返回0


127.0.0.1:6379> smembers set1 1) "item3" 2) "item2" 3) "item4" 4) "item1" 5) "item5" 127.0.0.1:6379> smembers set2 1) "item4" 2) "item1" 3) "item9" 4) "item2" 5) "item7" 6) "item6" #destination不存在时,自动创建set3集合,并将item5添加至set3 127.0.0.1:6379> smove set1 set3 item5 (integer) 1 127.0.0.1:6379> smembers set1 1) "item4" 2) "item1" 3) "item2" 4) "item3" 127.0.0.1:6379> smembers set3 1) "item5" #item6不存在于source 127.0.0.1:6379> smove set1 set2 item6 (integer) 0 127.0.0.1:6379> smembers set1 1) "item1" 2) "item2" 3) "item5" 4) "item3" 5) "item4" 127.0.0.1:6379> smembers set2 1) "item4" 2) "item1" 3) "item9" 4) "item2" 5) "item7" 6) "item6" #将item5从set1 移动至 set2 127.0.0.1:6379> smove set1 set2 item5 (integer) 1 127.0.0.1:6379> smembers set1 1) "item2" 2) "item1" 3) "item3" 4) "item4" 127.0.0.1:6379> smembers set2 1) "item1" 2) "item9" 3) "item2" 4) "item5" 5) "item7" 6) "item6" 7) "item4" #item1 同时存在于set1 set2时,仅删除 set1 中的 item1 127.0.0.1:6379> smembers set1 1) "item2" 2) "item5" 3) "item1" 4) "item3" 5) "item4" 127.0.0.1:6379> smembers set2 1) "item9" 2) "item2" 3) "item1" 4) "item7" 5) "item6" 6) "item4" 127.0.0.1:6379> smove set1 set2 item1 (integer) 1 127.0.0.1:6379> smembers set1 1) "item2" 2) "item5" 3) "item3" 4) "item4" 127.0.0.1:6379> smembers set2 1) "item9" 2) "item2" 3) "item1" 4) "item7" 5) "item6" 6) "item4"
5、获取集合交集
SINTER key [key …]
可用版本: >= 1.0.0时间复杂度: O(N * M),N为给定集合当中基数最小的集合,M为给定集合的个数。返回一个集合的全部成员,该集合是所有给定集合的交集。
不存在的
key被视为空集。当给定集合当中有一个空集时,结果也为空集(根据集合运算定律)。

127.0.0.1:6379> SMEMBERS set1 1) "item3" 2) "item2" 3) "item4" 4) "item1" 5) "item5" 127.0.0.1:6379> SMEMBERS set2 1) "item2" 2) "item9" 3) "item7" 4) "item1" 5) "item6" 6) "item4" 127.0.0.1:6379> sinter set1 set2 1) "item2" 2) "item4" 3) "item1"
SINTERSTORE destination key [key …]
可用版本: >= 1.0.0时间复杂度: O(N * M),N为给定集合当中基数最小的集合,M为给定集合的个数。这个命令类似于 SINTER key [key …] 命令,但它将结果保存到
destination集合,而不是简单地返回结果集。如果
destination集合已经存在,则将其覆盖。
destination可以是key本身。

127.0.0.1:6379> SMEMBERS set1 1) "item3" 2) "item2" 3) "item4" 4) "item1" 5) "item5" 127.0.0.1:6379> SMEMBERS set2 1) "item2" 2) "item9" 3) "item7" 4) "item1" 5) "item6" 6) "item4" #将set1 与 set2 的交集保存到 sinter_set 127.0.0.1:6379> sinterstore sinter_set set1 set2 (integer) 3 127.0.0.1:6379> SMEMBERS sinter_set 1) "item2" 2) "item4" 3) "item1"
6、获取集合并集
SUNION key [key …]
可用版本: >= 1.0.0时间复杂度: O(N),N是所有给定集合的成员数量之和。返回一个集合的全部成员,该集合是所有给定集合的并集。
不存在的
key被视为空集。

127.0.0.1:6379> SMEMBERS set1 1) "item3" 2) "item2" 3) "item4" 4) "item1" 5) "item5" 127.0.0.1:6379> SMEMBERS set2 1) "item2" 2) "item9" 3) "item7" 4) "item1" 5) "item6" 6) "item4" 127.0.0.1:6379> sunion set1 set2 1) "item9" 2) "item2" 3) "item5" 4) "item7" 5) "item1" 6) "item6" 7) "item3" 8) "item4"
SUNIONSTORE destination key [key …]
可用版本: >= 1.0.0时间复杂度: O(N),N是所有给定集合的成员数量之和。这个命令类似于 SUNION key [key …] 命令,但它将结果保存到
destination集合,而不是简单地返回结果集。如果
destination已经存在,则将其覆盖。
destination可以是key本身

127.0.0.1:6379> SMEMBERS set1 1) "item3" 2) "item2" 3) "item4" 4) "item1" 5) "item5" 127.0.0.1:6379> SMEMBERS set2 1) "item2" 2) "item9" 3) "item7" 4) "item1" 5) "item6" 6) "item4" 127.0.0.1:6379> sunionstore sunion_set set1 set2 (integer) 8 127.0.0.1:6379> SMEMBERS sunion_set 1) "item9" 2) "item2" 3) "item5" 4) "item7" 5) "item1" 6) "item6" 7) "item3" 8) "item4"
7、获取集合差集
SDIFF key [key …]
可用版本: >= 1.0.0时间复杂度: O(N),N是所有给定集合的成员数量之和。返回一个集合的全部成员,该集合是所有给定集合之间的差集。
不存在的
key被视为空集。

127.0.0.1:6379> SMEMBERS set2 1) "item2" 2) "item9" 3) "item7" 4) "item1" 5) "item6" 6) "item4" 127.0.0.1:6379> SMEMBERS set1 1) "item3" 2) "item2" 3) "item4" 4) "item1" 5) "item5" #set1 与 set2 的差值 127.0.0.1:6379> sdiff set1 set2 1) "item3" 2) "item5" #set2 与 set1 的差值 127.0.0.1:6379> sdiff set2 set1 1) "item6" 2) "item9" 3) "item7"
SDIFFSTORE destination key [key …]
可用版本: >= 1.0.0时间复杂度: O(N),N是所有给定集合的成员数量之和。这个命令的作用和 SDIFF key [key …] 类似,但它将结果保存到
destination集合,而不是简单地返回结果集。如果
destination集合已经存在,则将其覆盖。
destination可以是key本身

127.0.0.1:6379> SMEMBERS set1 1) "item2" 2) "item5" 3) "item1" 4) "item3" 5) "item4" 127.0.0.1:6379> SMEMBERS set2 1) "item2" 2) "item9" 3) "item7" 4) "item1" 5) "item6" 6) "item4"
#set1 与 set2 的差值结果保存到 sdiff_set1 127.0.0.1:6379> sdiffstore sdiff_set1 set1 set2 (integer) 2 127.0.0.1:6379> SMEMBERS sdiff_set1 1) "item3" 2) "item5"
#set2 与 set1 的差值结果保存到 sdiff_set2 127.0.0.1:6379> sdiffstore sdiff_set2 set2 set1 (integer) 3 127.0.0.1:6379> SMEMBERS sdiff_set2 1) "item6" 2) "item9" 3) "item7"
四、有序集合 sorted set

Sorted Set 有序集合也是一个由String字符类型元素组成的集合,且不允许内部元素value 重复出现。但是与Set集合不同的是,每个value元素都会关联一个double(双精度浮点型)类型的Score分散,Redis正是通过该Score分数为集合中的成员从小到大进行排序,有序集合成员value都是唯一的,但是Score分数允许出现重复情况。集合是通过哈希表实现的,所以添加、删除、查找的复杂度都是O(1),集合中最大成员数为 2^32-1,每个集合可容纳约40亿个成员,常用于实现排行榜或者浏览量统计等场景。
有序集合特点:
- 有序性
- 元素唯一性
- 每个元素通过score进行排序
- value不可以重复,score可以重复
1、生成有序集合
ZADD key score member [[score member] [score member] …]
可用版本: >= 1.2.0时间复杂度: O(M*log(N)),N是有序集的基数,M为成功添加的新成员的数量。将一个或多个
member元素及其score值加入到有序集key当中。如果某个
member已经是有序集的成员,那么更新这个member的score值,并通过重新插入这个member元素,来保证该member在正确的位置上。
score值可以是整数值或双精度浮点数。如果
key不存在,则创建一个空的有序集并执行 ZADD 操作。当
key存在但不是有序集类型时,返回一个错误。
#添加一个元素到有序列表
127.0.0.1:6379> zadd zset1 100 centos (integer) 1
#添加多个元素包含已存在的元素到有序列表 127.0.0.1:6379> zadd zset1 150 centos 160 ubuntu 170 alpine 900 windows10 (integer) 3
#添加多个新元素到有序列表 127.0.0.1:6379> zadd zset1 90 windows7 198 windows11 (integer) 2 127.0.0.1:6379> type zset1 zset
2、有序集合实现排行榜
ZRANGE key start stop [WITHSCORES]
可用版本: >= 1.2.0时间复杂度: O(log(N)+M),N为有序集的基数,而M为结果集的基数。返回有序集
key中,指定区间内的成员。其中成员的位置按
score值递增(从小到大)来排序。具有相同
score值的成员按字典序(lexicographical order )来排列。下标参数
start和stop都以0为底,也就是说,以0表示有序集第一个成员,以1表示有序集第二个成员,以此类推。 你也可以使用负数下标,以-1表示最后一个成员,-2表示倒数第二个成员,以此类推。超出范围的下标并不会引起错误。 比如说,当
start的值比有序集的最大下标还要大,或是start > stop时, ZRANGE 命令只是简单地返回一个空列表。 另一方面,假如stop参数的值比有序集的最大下标还要大,那么 Redis 将stop当作最大下标来处理。可以通过使用
WITHSCORES选项,来让成员和它的score值一并返回,返回列表以value1,score1, ..., valueN,scoreN的格式表示。 客户端库可能会返回一些更复杂的数据类型,比如数组、元组等。

#根据元素score值从小到大递增排序,并展示所有元素
127.0.0.1:6379> zrange zset1 0 -1 1) "windows7" 2) "centos" 3) "ubuntu" 4) "alpine" 5) "windows11" 6) "windows10" #根据元素score从小到大递增排序,并展示从第4位到最后一位的元素 127.0.0.1:6379> zrange zset1 3 -1 1) "alpine" 2) "windows11" 3) "windows10" #根据元素score从小到大递减排序,并展示所有元素及score信息 127.0.0.1:6379> zrange zset1 0 -1 withscores 1) "windows7" 2) "90" 3) "centos" 4) "150" 5) "ubuntu" 6) "160" 7) "alpine" 8) "170" 9) "windows11" 10) "198" 11) "windows10" 12) "900" #根据元素score从小到大递增排序,并展示从第4位到最后一位的元素及score信息 127.0.0.1:6379> zrange zset1 3 -1 withscores 1) "alpine" 2) "170" 3) "windows11" 4) "198" 5) "windows10" 6) "900"
ZREVRANGE key start stop [WITHSCORES]
可用版本: >= 1.2.0时间复杂度: O(log(N)+M),N为有序集的基数,而M为结果集的基数。返回有序集
key中,指定区间内的成员。其中成员的位置按
score值递减(从大到小)来排列。 具有相同score值的成员按字典序的逆序(reverse lexicographical order)排列。

#根据score从大到小递减排序,并展示所有元素 127.0.0.1:6379> zrevrange zset1 0 -1 1) "windows10" 2) "windows11" 3) "alpine" 4) "ubuntu" 5) "centos" 6) "windows7" #根据score从大到小递减排序,并展示第2位到倒数第2位元素 127.0.0.1:6379> zrevrange zset1 1 -2 1) "windows11" 2) "alpine" 3) "ubuntu" 4) "centos" #根据score从大到小递减排序,并展示所有元素及score信息 127.0.0.1:6379> zrevrange zset1 0 -1 withscores 1) "windows10" 2) "900" 3) "windows11" 4) "198" 5) "alpine" 6) "170" 7) "ubuntu" 8) "160" 9) "centos" 10) "150" 11) "windows7" 12) "90" #根据score从大到小递减排序,并展示第2位到倒数第2位元素及score信息 127.0.0.1:6379> zrevrange zset1 1 -2 withscores 1) "windows11" 2) "198" 3) "alpine" 4) "170" 5) "ubuntu" 6) "160" 7) "centos" 8) "150"
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
可用版本: >= 1.0.5时间复杂度: O(log(N)+M),N为有序集的基数,M为被结果集的基数。返回有序集
key中,所有score值介于min和max之间(包括等于min或max)的成员。有序集成员按score值递增(从小到大)次序排列。具有相同
score值的成员按字典序(lexicographical order)来排列(该属性是有序集提供的,不需要额外的计算)。可选的
LIMIT参数指定返回结果的数量及区间(就像SQL中的SELECT LIMIT offset, count),注意当offset很大时,定位offset的操作可能需要遍历整个有序集,此过程最坏复杂度为 O(N) 时间。可选的
WITHSCORES参数决定结果集是单单返回有序集的成员,还是将有序集成员及其score值一起返回。 该选项自 Redis 2.0 版本起可用。区间及无限
min和max可以是-inf和+inf,这样一来,你就可以在不知道有序集的最低和最高score值的情况下,使用 ZRANGEBYSCORE 这类命令。默认情况下,区间的取值使用闭区间 (小于等于或大于等于),你也可以通过给参数前增加
(符号来使用可选的开区间 (小于或大于)。举个例子:
ZRANGEBYSCORE zset (1 5返回所有符合条件
1 < score <= 5的成员,而ZRANGEBYSCORE zset (5 (10则返回所有符合条件
5 < score < 10的成员。

#将score分数在区间 150 >= score >=198 之间的元素按照从小到大递增次序排列并展示 127.0.0.1:6379> zrangebyscore zset1 150 198 1) "centos" 2) "ubuntu" 3) "alpine" 4) "windows11" #将score分数在区间 150 > score >198 之间的元素及score信息按照从小到大递增次序排列并展示 127.0.0.1:6379> zrangebyscore zset1 (150 (198 withscores 1) "ubuntu" 2) "160" 3) "alpine" 4) "170"
ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]
可用版本: >= 2.2.0时间复杂度: O(log(N)+M),N为有序集的基数,M为结果集的基数。返回有序集
key中,score值介于max和min之间(默认包括等于max或min)的所有的成员。有序集成员按score值递减(从大到小)的次序排列。具有相同
score值的成员按字典序的逆序(reverse lexicographical order )排列。除了成员按
score值递减的次序排列这一点外, ZREVRANGEBYSCORE 命令的其他方面和 ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] 命令一样。

#展示所有score分数低于900的元素,并按照从大到小递增排序 127.0.0.1:6379> zrevrangebyscore zset1 (900 -inf 1) "windows11" 2) "alpine" 3) "ubuntu" 4) "centos" 5) "windows7" #展示所有score分数不低于170的元素及score信息,按照从大到小递增排序 127.0.0.1:6379> zrevrangebyscore zset1 +inf 170 withscores 1) "windows10" 2) "900" 3) "windows11" 4) "198" 5) "alpine" 6) "170"
3、获取集合个数
ZCARD key
可用版本: >= 1.2.0时间复杂度: O(1)返回有序集
key的基数。
127.0.0.1:6379> zrange zset1 0 -1 1) "windows7" 2) "centos" 3) "ubuntu" 4) "alpine" 5) "windows11" 6) "windows10" 127.0.0.1:6379> zcard zset1 (integer) 6
ZCOUNT key min max
可用版本: >= 2.0.0时间复杂度: O(log(N)),N为有序集的基数。返回有序集
key中,score值在min和max之间(默认包括score值等于min或max)的成员的数量。
127.0.0.1:6379> zrange zset1 0 -1 withscores 1) "windows7" 2) "90" 3) "centos" 4) "150" 5) "ubuntu" 6) "160" 7) "alpine" 8) "170" 9) "windows11" 10) "198" 11) "windows10" 12) "900" 127.0.0.1:6379> zcount zset1 100 900 (integer) 5 127.0.0.1:6379> zcount zset1 -inf +inf (integer) 6
4、返回某个数值的索引
ZRANK key member
可用版本: >= 2.0.0时间复杂度: O(log(N))返回有序集
key中成员member的排名。其中有序集成员按score值递增(从小到大)顺序排列。排名以
0为底,也就是说,score值最小的成员排名为0
127.0.0.1:6379> zrank zset1 windows11 (integer) 4 127.0.0.1:6379> zrank zset1 centos (integer) 1
ZREVRANK key member
可用版本: >= 2.0.0时间复杂度: O(log(N))返回有序集
key中成员member的排名。其中有序集成员按score值递减(从大到小)排序。排名以
0为底,也就是说,score值最大的成员排名为0。
127.0.0.1:6379> zrevrank zset1 centos (integer) 4 127.0.0.1:6379> zrevrank zset1 windows11 (integer) 1
5、获取分数
ZSCORE key member
可用版本: >= 1.2.0时间复杂度: O(1)返回有序集
key中,成员member的score值。
127.0.0.1:6379> zscore zset1 centos "150" 127.0.0.1:6379> zscore zset1 windows10 "900"
6、增加指定元素的分数值
ZINCRBY key increment member
可用版本: >= 1.2.0时间复杂度: O(log(N))为有序集
key的成员member的score值加上增量increment。可以通过传递一个负数值
increment,让score减去相应的值,比如ZINCRBY key -5 member,就是让member的score值减去5。当
key不存在,或member不是key的成员时,ZINCRBY key increment member等同于ZADD key increment member
#对指定元素的分数加 127.0.0.1:6379> zscore zset1 centos "300" 127.0.0.1:6379> zincrby zset1 32 centos "332" 127.0.0.1:6379> zscore zset1 centos "332" #对指定元素的分数减 127.0.0.1:6379> zscore zset1 centos "332" 127.0.0.1:6379> zincrby zset1 -87 centos "245" 127.0.0.1:6379> zscore zset1 centos "245" #对不存在的元素进行score分数增 127.0.0.1:6379> zrange zset1 0 -1 1) "windows7" 2) "ubuntu" 3) "alpine" 4) "windows11" 5) "centos" 6) "windows10" 127.0.0.1:6379> zincrby zset1 324 unix "324" 127.0.0.1:6379> zrange zset1 0 -1 1) "windows7" 2) "ubuntu" 3) "alpine" 4) "windows11" 5) "centos" 6) "unix" 7) "windows10"
7、删除元素
ZREM key member [member …]
可用版本: >= 1.2.0时间复杂度: O(M*log(N)),N为有序集的基数,M为被成功移除的成员的数量。移除有序集
key中的一个或多个成员,不存在的成员将被忽略。
127.0.0.1:6379> zrange zset1 0 -1 withscores 1) "windows7" 2) "90" 3) "ubuntu" 4) "160" 5) "alpine" 6) "170" 7) "windows11" 8) "198" 9) "centos" 10) "245" 11) "unix" 12) "324" 13) "windows10" 14) "900" 127.0.0.1:6379> zrem zset1 unix ios (integer) 1 127.0.0.1:6379> zrange zset1 0 -1 withscores 1) "windows7" 2) "90" 3) "ubuntu" 4) "160" 5) "alpine" 6) "170" 7) "windows11" 8) "198" 9) "centos" 10) "245" 11) "windows10" 12) "900"
ZREMRANGEBYRANK key start stop
可用版本: >= 2.0.0时间复杂度: O(log(N)+M),N为有序集的基数,而M为被移除成员的数量。移除有序集
key中,指定排名(rank)区间内的所有成员。区间分别以下标参数
start和stop指出,包含start和stop在内。下标参数
start和stop都以0为底,也就是说,以0表示有序集第一个成员,以1表示有序集第二个成员,以此类推。 你也可以使用负数下标,以-1表示最后一个成员,-2表示倒数第二个成员,以此类推。
127.0.0.1:6379> zrange zset1 0 -1 withscores 1) "windows7" 2) "90" 3) "ubuntu" 4) "160" 5) "alpine" 6) "170" 7) "windows11" 8) "198" 9) "centos" 10) "245" 11) "windows10" 12) "900" 127.0.0.1:6379> zremrangebyrank zset1 0 2 (integer) 3 127.0.0.1:6379> zrange zset1 0 -1 withscores 1) "windows11" 2) "198" 3) "centos" 4) "245" 5) "windows10" 6) "900"
ZREMRANGEBYSCORE key min max
可用版本: >= 1.2.0时间复杂度: O(log(N)+M),N为有序集的基数,而M为被移除成员的数量。移除有序集
key中,所有score值介于min和max之间(包括等于min或max)的成员。
127.0.0.1:6379> zrange zset1 0 -1 withscores 1) "windows11" 2) "198" 3) "centos" 4) "245" 5) "windows10" 6) "900" 127.0.0.1:6379> zremrangebyscore zset1 -inf 300 (integer) 2 127.0.0.1:6379> zrange zset1 0 -1 withscores 1) "windows10" 2) "900"
使用DEL删除有序集合key
127.0.0.1:6379> del zset1 (integer) 1
五、哈希 hash

Hash哈希是一个字符类型String(field)与 值(value)的映射表,Redis中的每个哈希Hash可以存储 2^32-1 键值对,类似于字典作用,特别适用于存储对象场景。
1、生成hash key
HSET hash field value
可用版本: >= 2.0.0时间复杂度: O(1)将哈希表
hash中域field的值设置为value。如果给定的哈希表并不存在, 那么一个新的哈希表将被创建并执行
HSET操作。如果域
field已经存在于哈希表中, 那么它的旧值将被新值value覆盖。
127.0.0.1:6379> hset hash1 id 1 name janzen age 18 sex man number 159159 (integer) 5 127.0.0.1:6379> type hash1 hash
HSETNX hash field value
可用版本: >= 2.0.0时间复杂度: O(1)当且仅当域
field尚未存在于哈希表的情况下, 将它的值设置为value。如果给定域已经存在于哈希表当中, 那么命令将放弃执行设置操作。
如果哈希表
hash不存在, 那么一个新的哈希表将被创建并执行HSETNX命令。返回值
HSETNX命令在设置成功时返回1, 在给定域已经存在而放弃执行设置操作时返回0
127.0.0.1:6379> exists hash2 (integer) 0 #hash 不存在 127.0.0.1:6379> hsetnx hash2 id 2 (integer) 1 #同时修改多个参数 127.0.0.1:6379> hsetnx hash2 id 2 name qiu (error) ERR wrong number of arguments for 'hsetnx' command
#field 不存在 127.0.0.1:6379> hsetnx hash2 name qiu (integer) 1 #field已存在 127.0.0.1:6379> hsetnx hash2 id 3 (integer) 0 127.0.0.1:6379>
2、获取hash key 对应字段的值
HGET hash field
可用版本: >= 2.0.0时间复杂度: O(1)返回哈希表中给定域的值。
127.0.0.1:6379> hget hash1 id "1" 127.0.0.1:6379> hget hash1 name "janzen" 127.0.0.1:6379> hget hash1 age "18" 127.0.0.1:6379> hget hash2 id "2" 127.0.0.1:6379> hget hash2 name "qiu"
3、删除一个hash key的对应字段
HDEL key field [field …]
删除哈希表
key中的一个或多个指定域,不存在的域将被忽略。
127.0.0.1:6379> hdel hash2 id (integer) 1 127.0.0.1:6379> hdel hash2 id name (integer) 1
4、批量设置hash key 的多个filed和value
HMSET key field value [field value …]
同时将多个
field-value(域-值)对设置到哈希表key中。此命令会覆盖哈希表中已存在的域。
如果
key不存在,一个空哈希表被创建并执行 HMSET 操作
127.0.0.1:6379> hmset hash2 id 2 name qiu age 20 sex man number 970203 OK
5、获取hash中指定字段的值
HMGET key field [field …]
返回哈希表
key中,一个或多个给定域的值。如果给定的域不存在于哈希表,那么返回一个
nil值。因为不存在的
key被当作一个空哈希表来处理,所以对一个不存在的key进行 HMGET 操作将返回一个只带有nil值的表。
127.0.0.1:6379> hmget hash2 id name number 1) "2" 2) "qiu" 3) "970203" 127.0.0.1:6379> hmget hash1 id name number 1) "1" 2) "janzen" 3) "159159"
6、获取hash中的所有字段名field
HKEYS key
返回哈希表
key中的所有field
127.0.0.1:6379> hkeys hash1 1) "id" 2) "name" 3) "age" 4) "sex" 5) "number" 127.0.0.1:6379> hkeys hash2 1) "id" 2) "name" 3) "age" 4) "sex" 5) "number"
7、获取指定hash所有的value
HVALS key
返回哈希表
key中所有field的值。
127.0.0.1:6379> hvals hash1 1) "1" 2) "janzen" 3) "18" 4) "man" 5) "159159" 127.0.0.1:6379> hvals hash2 1) "2" 2) "qiu" 3) "20" 4) "man" 5) "970203"
8、获取指定hash的所有field和value值
HGETALL key
返回哈希表
key中,所有的域和值。
127.0.0.1:6379> hgetall hash1 1) "id" 2) "1" 3) "name" 4) "janzen" 5) "age" 6) "18" 7) "sex" 8) "man" 9) "number" 10) "159159" 127.0.0.1:6379> hgetall hash2 1) "id" 2) "2" 3) "name" 4) "qiu" 5) "age" 6) "20" 7) "sex" 8) "man" 9) "number" 10) "970203"
9、删除hash
HDEL key field [field …]
删除哈希表
key中的一个或多个指定域,不存在的域将被忽略。
127.0.0.1:6379> hgetall hash2 1) "id" 2) "2" 3) "name" 4) "qiu" 5) "age" 6) "20" 7) "sex" 8) "man" 9) "number" 10) "970203" 127.0.0.1:6379> hdel hash2 id (integer) 1 127.0.0.1:6379> hgetall hash2 1) "name" 2) "qiu" 3) "age" 4) "20" 5) "sex" 6) "man" 7) "number" 8) "970203" 127.0.0.1:6379> hdel hash2 name age addr (integer) 2 127.0.0.1:6379> hgetall hash2 1) "sex" 2) "man" 3) "number" 4) "970203"
文章来源:https://www.toymoban.com/news/detail-437587.html
使用DEL删除hash key
127.0.0.1:6379> hgetall hash2 1) "sex" 2) "man" 3) "number" 4) "970203" 127.0.0.1:6379> del hash2 (integer) 1 127.0.0.1:6379> hgetall hash2 (empty list or set) 127.0.0.1:6379> exists hash2 (integer) 0 127.0.0.1:6379>
文章来源地址https://www.toymoban.com/news/detail-437587.html
到了这里,关于【Redis】数据类型介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!