1 v2 细节升级概述

2 .网络结构特点
- 使用dropout,杀死部分神经元,使得神经没那么复杂,防止过拟合
- V2 舍弃Dropout,卷积后全部加入Batch Normalization
- Batch Normalization 归一化,让网络收敛,学习速度更快
- conv-BN, 已是目前网络的标配。


- 使用更大的分辨率(V1训练时使用224)
3. 架构细节解读

7.为啥是416416,不是448448,需要经过5次降采样,所以要能被32整除,并且除得的结果是奇数,比如最后是1313,只有一个中心点,如果最后结果是偶数,则有4个中心点,不好处理。
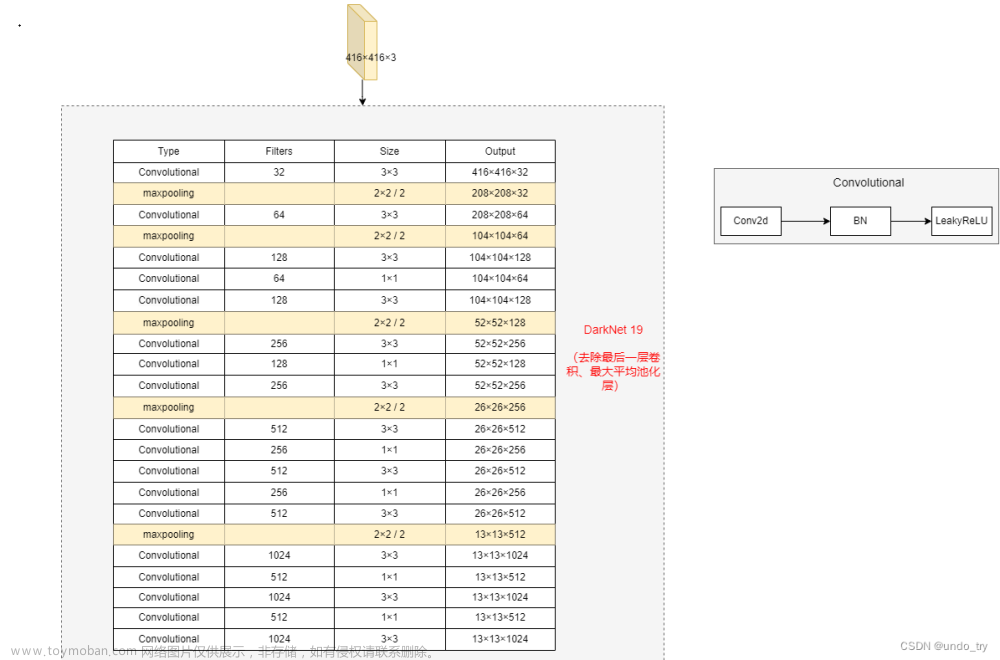
8. DarkNet 19 ,19层卷积层
9.问题: Filter 是什么,为什么数值一直在增加?
9. 网络模型都是卷积,没有全连接层,做起来省事,省参数,比较快,
10. 卷积核33,1*1,比较小,感受野比较大。
4. 基于聚类来选择先验框尺寸

11.Faster RCNN: 9种,按照 1:1,1:2,2:1, 3*3=9种
12. v2: 使用k-means 聚类,将实际打标的框聚类,比如聚成5类,将每类的中心点作为一个框。但是不使用欧式距离,使用 1-IOU作为距离**。(V2的特点)**
13. 如何确认聚类的类数呢? 做了一个折中,k=5时,平均IOU值还不错,再往上的话,IOU提升不明显,所以k=5。
5. 偏移量计算方法

问题:使用先验框前后,mAP值没有提升。原因在于,虽然候选框多了,但是不是所有的候选框都能发生作用。

sigmoid函数,(0-1)之间,
6. 坐标映射与还原
pw ph 为先验框
14. 特征图为降采样以后的,还原到原图的话,*采样倍数(32)
7 感受野
 感受野的大小跟卷积有关。1–>33–>55 。
感受野的大小跟卷积有关。1–>33–>55 。 
15. 为什么要用小的卷积核,不用大的卷积核?卷积核大的话,参数多。并且卷积核小一点,卷积过程越多,特征提取也会越细致。
卷积核的第三个维度要跟输入的第三个维度一样,c个卷积核,再*c
8. 特征融合的改进

16. 最后一层感受野太大了,小目标可能丢失了,需融合之前的特征。
倒数前几层的感受野可能比较小,如19层是大目标的感受野,17层是小目标的感受野
将前一层2626523分为4个 41313512,跟13131024相加后得到 5124+1024=3072 30721313
17. 多尺度, 没有全连接层,只有卷积层,不同大小的图像尺寸均可以。
其他知识点
filter 是什么?
神经网络中的filter (滤波器)与kernel(内核)的概念
kernel: 内核是一个2维矩阵,长 × 宽;
filter:滤波器是一个三维立方体,长× 宽 × 深度, 其中深度便是由 多少张内核构成;
两者之间的关系:可以说 kernel 是filter 的基本元素, 多张kernel 组成一个filter;
那么, 一个filter 中应该包含多少张 kernel 呢?
答:是由输入的通道个数所确定, 即,输入通道是3个特征时,则后续的每一个filter中包含3张kernel ;
filter输入通道是包含128个特征时, 则一个filter中所包含kernel 数是128张。
那么一层中应该有多少个filter 构成呢?
答: 我们想要提取多少个特征,即我们想要输出多少个特征,那么这一层就设置多少个filter;文章来源:https://www.toymoban.com/news/detail-437838.html
一个filter 负责提取某一种特征,N个filter 提取 N 个 特征;文章来源地址https://www.toymoban.com/news/detail-437838.html
到了这里,关于yoloV2细节改进的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!