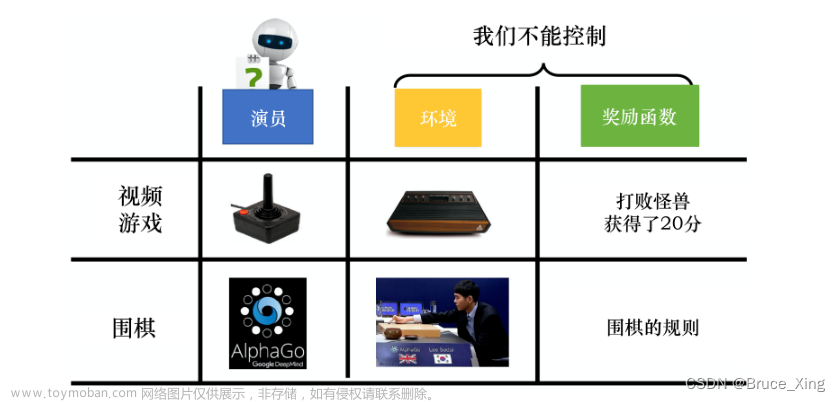
Proximal Policy Optimization (PPO)
一、Motivation
避免较多的策略更新。
- 根据经验,训练期间较小的策略更新更有可能收敛到最优解决方案。
- 在策略更新中,太大的一步可能会导致“掉下悬崖”(得到一个糟糕的策略),并且有很长时间甚至没有可能恢复。
![[论文笔记] chatgpt系列 1.1 PPO算法(Proximal Policy Optimization)](https://imgs.yssmx.com/Uploads/2023/05/438457-1.png) 文章来源:https://www.toymoban.com/news/detail-438457.html
文章来源:https://www.toymoban.com/news/detail-438457.html
所以在PPO中,我们保守地更新策略。为此,我们需要使用当前policy和前policy之间的比率计算来衡量当前政策与前政策相比发生了多少变化。我们把比率控制在[1-e,1+e],意味着我们移除当前policy与前policy太远的激励(因此称为近端政策术语)。文章来源地址https://www.toymoban.com/news/detail-438457.html
二、推导
2.1 策略目标函数(The Policy Objective Function):
到了这里,关于[论文笔记] chatgpt系列 1.1 PPO算法(Proximal Policy Optimization)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!