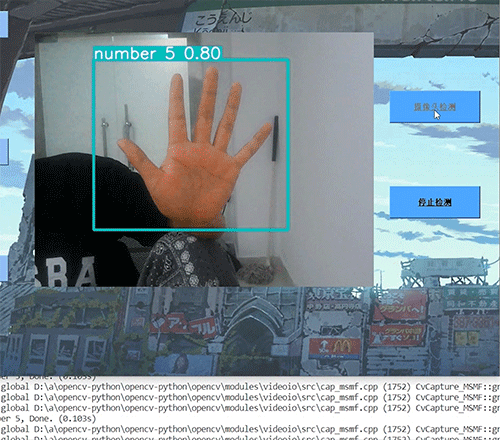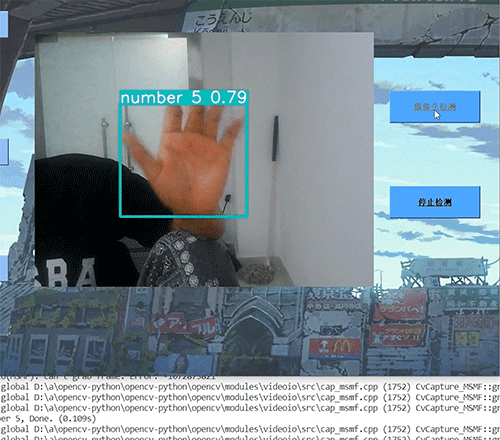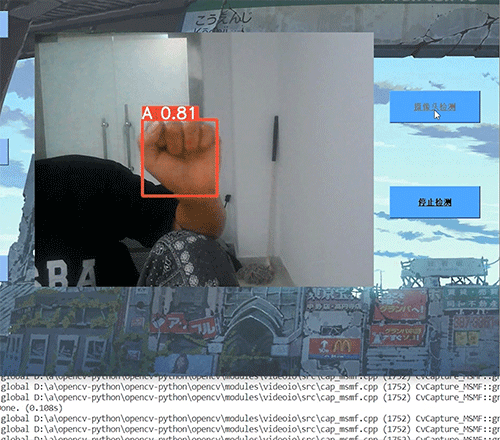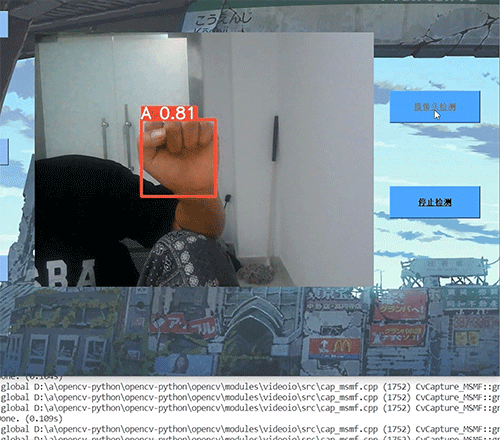
基于计算机视觉手势识别控制系统YoloGesture (利用YOLO实现)

Streamlit在线服务器体验网址: https://kedreamix-yologesture.streamlit.app/
HuggingFace在线服务器体验网址:https://huggingface.co/spaces/Kedreamix/YoloGesture
为了解答大家的问题,我录了个视频,大家也可以看看,https://www.bilibili.com/video/BV1LV4y1d7pg/,如果有问题可以在github上给我发issue进行探讨,也欢迎大家给我提PR
1. 项目已完成的部分
- 数据集的构建
- 代码的基本运行和训练
- 增加数据集 800 -> 1600
- 利用Mosaic数据增强,但是结果不好,之后训练不会采用,除非数据足够多
- 增加yaml文件,利用yaml配置所有参数
- 提高图片的输入shape,从256x256 -> 416x416
- 由于结果不理想,使用部分自制数据集替换,数据集总数不变
- 添加yolov4 tiny 轻量化模型
- 增加注意力机制,可以比轻量化模型得到更不错的结果
- 使用MobileNet作为backbone,轻量化模型
- 使用yolov5 或者 yolox 改进方法
2. 部分尝试结果
- 使用Mosaic 结果较差
- 在运行过程中结果十分差,原因是数据集标注出现错误,会重新修改数据集
- 用SGD的结果没有Adam好
- front的数据集需要重新修改才能得到更好的结果
- 使用tiny模型速度更快,结果虽然差一点,但是只是一个速度与精度的trade off
3. 项目整体框架
1、 了解项目研究的背景以及其意义,学习其中的创新点和科研价值。
2、 使用python语言对项目中的代码进行编写。研究项目源代码,理解项目工程的代码结构、原理及其功能。
3、 学习深度学习算法。理解卷积神经网络的相关概念,包括神经元系统、局部感受野、权值共享和卷积神经网络总体结构;了解目前常见的目标检测方法和YOLOv4算法框架,以及基于YOLOv4的手势识别算法。
4、 设计并制作针对本项目手势控制数据集,并使用数据增广的方式对数据集进行扩充,同时使用图像处理的方法包括中值滤波、阈值分割等对数据进行预处理。
5、 训练模型,对目标检测性能进行测试。了解实验环境以及评价标准,测试本项目研究的手势识别算法的实验结果,然后通过采用控制变量方法对手势识别算法进行多组实验,以评估其在不同环境下的识别效果,使用验证集对手势识别算法的精度和速度进行性能测试。
6、 总结本项目的研究工作,对基于无人机的手势识别演剧提供创新点与发展建议。
3.1. 数据集构建
- 设计并制作针对本项目手势控制数据集,对数据集进行分类。

- 使用Labelimg标注工具设计针对本项目的手势数据集,对数据集进行标注。

3.2. 模型选择
在前期的模型选择中,简单的选择了YOLOv4的模型进行训练和测试
YOLOv4 = CSPDarknet53(主干) + SPP 附加模块(颈 ) + PANet 路径聚合(颈 ) + YOLOv3(头部)

3.3. 代码实现
- 主干特征提取网络:DarkNet53 => CSPDarkNet53
- 特征金字塔:SPP,PAN
- 训练用到的小技巧:Mosaic数据增强、Label Smoothing平滑、CIOU、学习率余弦退火衰减
- 激活函数:使用Mish激活函数
- 增加yaml配置文件,只需要修改配置文件即可
- 添加detect.py,利用此进行半自动标注,可以方便标注其他类似于对应👋的数据集
- 修改成命令行运行的快速模式,很方便,快速运行和理解
- 利用streamlit部署到服务器上,可以随时使用,在线demo https://kedreamix-yologesture.streamlit.app/
- …
4. 实验结果详情
| 训练数据集 | 权值文件名称 | 迭代次数 | Batch-size | 图片shape | 平均准确率 | mAP 0.5 | fps |
|---|---|---|---|---|---|---|---|
| Gesture v1 | yolo4_gesture_weights.pth | 150 | 4->8 | 256x256 | 61.65 | 51.66 | |
| Gesture v2 | yolo4tiny_gesture_SE.pth | 100 | 64->32 | 416x416 | 83.6 | 95.18 | 76.08 |
| Gesture v2 | yolo4tiny_gesture_CBAM.pth | 100 | 64->32 | 416x416 | 89.35 | 98.85 | 70.01 |
| Gesture v2 | yolo4tiny_gesture_ECA.pth | 100 | 64->32 | 416x416 | 88.37 | 96.26 | 77.19 |
| Gesture v2 | yolo4tiny_gesture.pth | 100 | 64->32 | 416x416 | 87.01 | 95.86 | 81.81 |
| Gesture v2 | yolo4_gesture_weightsv2.pth | 100 | 4->8 | 256x256 | 84.51 | 90.77 | 24.21 |
| Gesture v3 | yolov4_tiny.pth | 150 | 64->32 | 416x416 | 75.05 | 91.30 | |
| Gesture v3 | yolov4_SE.pth | 150 | 64->32 | 416x416 | 78.06 | 90.13 | |
| Gesture v3 | yolov4_CBAM.pth | 150 | 64->32 | 416x416 | 91.09 | 94.97 | |
| Gesture v3 | yolov4_ECA.pth | 150 | 64->32 | 416x416 | 94.58 | 83.24 | |
| Gesture v3 | yolov4_weights_ep150_416.pth | 150 | 64->32 | 416x416 | 95.145 | 98.35 | |
| Gesture v3 | yolov4_weights_ep150_608.pth | 150 | 64->32 | 608x608 | 93.64 | 97.23 |
Gesture v1中存在数据集问题,所以模型结构不好
Gesture v2中重新修改数据集
Gesture v3中修改front数据集
Batch-Size 64->32是指在进行训练的时候,前半段冻结的时候使用的bs为64,在后续不冻结训练使用bs=32
4.1. 训练权重文件下载
训练所需的yolo4_weights.pth有两种方式下载。(release包含所有过程的权重,百度网盘和奶牛只记录最新的权重)
-
可以从我的release下载权重
-
也可以百度网盘下载
链接:https://pan.baidu.com/s/1Pt11VHMaHqSsPjb50W5IeQ
提取码:6666 -
由于百度网盘下载速度较慢,这里也给一个不限速的链接 (永久有效)
传输链接:https://cowtransfer.com/s/dc5e0f7f43a940 或 打开【奶牛快传】cowtransfer.com 使用传输口令:ftyvu0 提取;
4.2. 数据集概况
- Gesture v1 只有800张图片,数量较少
- Gesture v2 增加了800张图片,数量增多,一共1600张图片
在运行过程中结果十分差,原因是数据集标注出现错误,会重新修改数据集
- Gesture v3 中修改了front的手势,使得front结果大大提升,平均准确率增大
上述展示图是关于Gesture v1的手势,后续数据进行了修改
整体数据集一共含有1600张,8个类别的手势,我的Gesture v3最后就是8个类别,大概1600张的数据集,类别分别是
- up
- down
- left
- right
- front
- back
- clockwise
- anticlockwise
数据已经放在release中了,可以下载自用
之后我也做了类似的手势识别的任务,里面的数据集有18个类别 HaGRID手势识别数据集,里面的手势结果更多,并且也更大,总共有716G,建议可以缩小以后进行训练增强,如果有机会,我可以拿一个多类别的我也来训练一下
以下是HaGRID的手势识别的类别,支持更多的手势识别的结果,这是官方下载地址:https://github.com/hukenovs/hagrid

5. 环境配置
我用的是torch1.8.1 torchvision0.9.1
代码在更高的版本也是适配的,我觉得可能去>=1.7的应该都是可以的
相对应的库可以直接利用以下代码在当前路径进行运行,利用清华源进行换源
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
6. 快速运行代码
以下可以在命令行中运行,在命令行运行可能会更好一点
Installgit clone https://github.com/Kedreamix/YoloGesture.git
cd YoloGesture
pip install -r requirements.txt # -i https://pypi.tuna.tsinghua.edu.cn/simple/ # install 可以加上清华源
python voc_annotation.py
python kmeans_for_anchors.py

我们可以在里面设置所需要的参数,phi代表着不同的注意力机制,weights代表着权重,其他的是我们的一些参数的设置,都是可调的,参数的部分解释都可以从python train.py --help看到
usage: train.py [-h] [--init INIT] [--epochs EPOCHS] [--weights WEIGHTS]
[--freeze] [--freeze-epochs FREEZE_EPOCHS]
[--freeze-size FREEZE_SIZE] [--batch-size BATCH_SIZE]
[--optimizer {sgd,adam,adamw}] [--num_workers NUM_WORKERS]
[--lr LR] [--tiny] [--phi PHI] [--weight-decay WEIGHT_DECAY]
[--momentum MOMENTUM] [--save-period SAVE_PERIOD] [--cuda]
[--shape SHAPE] [--fp16] [--mosaic]
[--lr_decay_type {cos,step}] [--distributed]
optional arguments:
-h, --help show this help message and exit
--init INIT 从init epoch开始训练
--epochs EPOCHS epochs for training
--weights WEIGHTS initial weights path 初始权重的路径
--freeze 表示是否冻结训练
--freeze-epochs FREEZE_EPOCHS
epochs for feeze 冻结训练的迭代次数
--freeze-size FREEZE_SIZE
total batch size for Freezeing
--batch-size BATCH_SIZE
total batch size for all GPUs
--optimizer {sgd,adam,adamw}
训练使用的optimizer
--num_workers NUM_WORKERS
用于设置是否使用多线程读取数据
--lr LR Learning Rate 学习率的初始值
--tiny 使用yolov4-tiny模型
--phi PHI yolov4-tiny所使用的注意力机制的类型
--weight-decay WEIGHT_DECAY
权值衰减,可防止过拟合
--momentum MOMENTUM 优化器中的参数
--save-period SAVE_PERIOD
多少个epochs保存一次权重
--cuda 表示是否使用GPU
--shape SHAPE 输入图像的shape,一定要是32的倍数
--fp16 是否使用混合精度训练
--mosaic Yolov4的tricks应用 马赛克数据增强
--lr_decay_type {cos,step}
cos
--distributed 是否使用多卡运行
这里对一些常用参数进行解释
-
fp16
由于训练神经网络,有时候得到的权重的精度都是64位或者32位的,保存和训练的时候都占了很多显存,但是有时候这些是不必要的,所以可以利用fp16将精度设为16位,这样大概可以减少一半的显存
-
phi
这里解释一下,phi = 0代表的是yolov4_tiny,也就是改进的轻量化yolov4,而phi = 1,2,3分别是加了SE,CBAM,ECA三种注意力机制得到的结果。具体对SE,CBAM,ECA注意力机制不懂的,可以看看这篇博文,我觉得写的蛮好的:https://blog.csdn.net/weixin_44791964/article/details/121371986,这里不过多介绍。
-
freeze
除此之外,可以从下面的代码看出,我们可以冻结进行迁移学习,也可以选择不冻结,通过参数freeze来控制,还可以控制冻结次数的冻结时的batch-size,冻结的时候,可以把batch-size调高一点,并且还可以调一下freeze-epochs参数和freeze-size参数
如果对于不同模型训练的不动的,可以看看下面的训练预测细节解释
# 冻结进行迁移学习,利用已有的yolov4_SE.pth的权重进行
python train.py --tiny --phi 1 --epochs 100 \
--weights model_data/yolov4_SE.pth \
--freeze --freeze-epochs 50 --freeze-size 64 \
--batch-size 32 --shape 416 \
--fp16 --cuda
# 快速运行尝试,重新学习
python train.py --tiny --phi 1 --epochs 10 \
--batch-size 4 --shape 416 \
--fp16 --cuda
在后续为了简化操作,不用打那么多的字母,还进行了缩写的修改,把–freeze简化成-f,–weights 简化成 -w, --freeze-epochsj简化成-fe,–freeze-size 简化成fb, --batch-size简化成-bs,这是为了方便运行的时候设置参数
这段代码和上面是等价的
# 冻结进行迁移学习
python train.py --tiny --phi 1 --epochs 100 \
-w model_data/yolov4_SE.pth \
-f -fe 50 -fs 64 \
--bs 32 --shape 416 \
--fp16 --cuda
# 快速运行尝试,重新学习
python train.py --tiny --phi 1 --epochs 10 \
--batch-size 4 --shape 416 \
--fp16 --cuda
predict也有一些参数,比如以什么模式运行,分别有[‘dir_predict’, ‘video’, ‘fps’,‘predict’,‘heatmap’],默认是用predict来推理img文件夹下的所有图片
# python predict.py --mode dir_predict \
# --tiny --phi 1 \
# --weights model_data/yolov4_SE.pth \
# --cuda --shape 416
python predict.py --tiny --cuda
这一部分可以得到召回率和精确率等可视化的图片,可以清晰的看到结果
# 对验证集进行计算
# python get_map.py --mode 0 \
# --tiny --phi 1 \
# --weights model_data/yolov4_SE.pth \
# --cuda --shape 416
# python .\get_map.py --cuda --mode 0 --tiny --phi 3 --weights model_data/yolotv4_ECA.pth
python get_map.py --tiny --cuda
所有的参数都可以通过,通过help看到解释
python train.py -h
python get_map.py -h
python predict.py -h
除此之外,如果有多个GPU,需要设定指定的GPU,在python前加上配置CUDA_VISIBLE_DEVICES=3,表示使用第四块GPU
# 比如使用第4块GPU
CUDA_VISIBLE_DEVICES=3 python train.py ...
或者是多块GPU,比如有0,1两块GPU
# 比如使用第0,1块GPU
CUDA_VISIBLE_DEVICES=0,1 python train.py ...
7. 训练预测细节解释
7.1. 训练配置文件(重点)
这个重中之重,在model_data文件夹下,有一个yaml文件,里面包括部分需要运行的参数
只需要调节里面的参数,然后运行就可以得到我们的结果,完全是ok的,只需要改配置文件,其他参数可以在命令行修改,直接运行也是可以使用的,下面会详细介绍,主要是修改train.py的部分,因为这样可以方便我们训练
#------------------------------detect.py--------------------------------#
# 这一部分是为了半自动标注数据,可以减轻负担,需要提前训练一个权重,以Labelme格式保存
# dir_origin_path 图片存放位置
# dir_save_path Annotation保存位置
# ----------------------------------------------------------------------#
dir_detect_path: ./JPEGImages
detect_save_path: ./Annotation
# ----------------------------- train.py -------------------------------#
nc: 8 # 类别的数量
classes: ["up","down","left","right","front","back","clockwise","anticlockwise"] # 类别
confidence: 0.5 # 置信度
nms_iou: 0.3
letterbox_image: False
lr_decay_type: cos # 使用到的学习率下降方式,可选的有step、cos
# 用于设置是否使用多线程读取数据
# 开启后会加快数据读取速度,但是会占用更多内存
# 内存较小的电脑可以设置为2或者0,win建议设为0
num_workers: 4
7.2. 训练自己数据集
-
数据集的准备
训练前将标签文件放在VOCdevkit文件夹下的VOC2007文件夹下的Annotation中。
训练前将图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages中。 -
数据集的处理
在完成数据集的摆放之后,我们需要利用voc_annotation.py获得训练用的2007_train.txt和2007_val.txt。
修改voc_annotation.py里面的参数。第一次训练可以仅修改classes_path,classes_path用于指向检测类别所对应的txt。然后再前面所说的data.yaml中写清楚自己的类别以及类别的数量
nc: 8 # 类别的数量 classes: ["up","down","left","right","front","back","clockwise","anticlockwise"] # 类别 -
开始网络训练
之后根据快速运行train.py,运行train.py开始训练了,在训练多个epoch后,权值会生成在logs文件夹中,可以自己设迭代次数保存权重,如上述快速运行即可。
这里面我内置了5个模型,分别是最原始的yolov4模型,以及yolov4-tiny,yolov4-SE,yolov4-ECA,yolov4-CBAM四种模型,这四种模型都可以进行训练,其中yolov4-tiny,yolov4-SE,yolov4-ECA,yolov4-CBAM都属于小模型,所以认为是tiny模型,得到的权重也比较小速度也会比较快,这几种方式有不同的参数,我现在简单的介绍,我用tiny和phi的参数对他们进行分开
- phi = 0 yolov4-tiny
- phi = 1 yolov4-SE
- phi = 2 yolov4-CBAM
- phi = 3 yolov4-ECA
# yolov4 模型 python train.py --epochs 10 --shape 416 --cuda --batch-size 4 # yolov4-tiny python train.py --epochs 10 --shape 416 --cuda --batch-size 8 --tiny --phi 0 # yolov4-SE python train.py --epochs 10 --shape 416 --cuda --batch-size 8 --tiny --phi 1 # yolov4-CBAM python train.py --epochs 10 --shape 416 --cuda --batch-size 8 --tiny --phi 2 # yolov4-ECA python train.py --epochs 10 --shape 416 --cuda --batch-size 8 --tiny --phi 3如果还要做其他参数对,也可以看到快速运行代码的训练部分,进行增加一些参数
-
训练结果预测
训练结果预测需要用到两个文件,分别是yolo.py和predict.py。
完成修改后就可以运行predict.py进行检测了。运行后输入图片路径即可检测。 (可以自己设置模式得到结果)
7.3. 使用Tensorboard可视化结果
在我们训练的过程中,我们可以用TensorBoard实时查看训练情况,也可以看到训练的网络模型结构,非常方便
只需要在我们的文件夹的命令行下,运行
tensorboard --logdir='logs/'
之后大概我们的6006端口就可以实时看到我们的结果,即是https://localhost:6006
如果是使用Ubuntu,有可能会出现一些bug,所以需要进行一些操作,因为会显示无法找到命令
这时候首先需要找到TensorBoard在库的哪里
pip show tensorboard这样子就能看到自己tensorboard下载的路径
然后找到TensorBoard的文件夹下,找到main.py文件,就可以进行了,利用绝对路径就可以了
python .../python3.8/site-packages/tensorboard/main.py --logdir='logs/'
7.4. 预测步骤
-
下载完库后解压,在百度网盘后者其他地方下载yolo_gesture_weights.pth,放入model_data,运行predict.py,调整权重路径
在predict.py中事先设置了
dir_predict表示遍历文件夹进行检测并保存。默认遍历img文件夹,保存img_out文件夹,这样就可以在img_out中得到文件有很多种模式,可以通过mode来调节,这一部分还可以设置参数,我们都可以从help里看到
predict.py -h usage: predict.py [-h] [--weights WEIGHTS] [--tiny] [--phi PHI] [--mode {dir_predict,video,fps,predict,heatmap,export_onnx}] [--cuda] [--shape SHAPE] [--video VIDEO] [--save-video SAVE_VIDEO] [--confidence CONFIDENCE] [--nms_iou NMS_IOU] optional arguments: -h, --help show this help message and exit --weights WEIGHTS initial weights path --tiny 使用yolotiny模型 --phi PHI yolov4tiny注意力机制类型 --mode {dir_predict,video,fps,predict,heatmap,export_onnx} 预测的模式 --cuda 表示是否使用GPU --shape SHAPE 输入图像的shape --video VIDEO 需要检测的视频文件 --save-video SAVE_VIDEO 保存视频的位置 --confidence CONFIDENCE 只有得分大于置信度的预测框会被保留下来 --nms_iou NMS_IOU 非极大抑制所用到的nms_iou大小如果下载了权重于路径model_data/yolov4_tiny.pth,默认是文件夹中的图片模式运行,我们就可以直接运行得到结果
python predict.py --tiny --phi 0 --weights model_data/yolov4_tiny.pth -
在predict.py里面进行设置可以进行fps测试和video视频检测。 (这一部分可以自己尝试)
这一部分只要设置一下路径和视频即可,分别有多种模式
7.5. 评估步骤
-
本文使用VOC格式进行评估。
-
如果在训练前已经运行过voc_annotation.py文件,代码会自动将数据集划分成训练集、验证集和测试集。如果想要修改测试集的比例,可以修改voc_annotation.py文件下的trainval_percent。trainval_percent用于指定(训练集+验证集)与测试集的比例,默认情况下 (训练集+验证集):测试集 = 9:1。train_percent用于指定(训练集+验证集)中训练集与验证集的比例,默认情况下 训练集:验证集 = 9:1。
-
利用voc_annotation.py划分测试集
-
运行get_map.py即可获得评估结果,评估结果会保存在map_out文件夹中。
8. Streamlit 项目部署
经过上述学习过程,最后我利用streamlit进行了项目部署,可以在本地部署,也可以在云端部署,代码已经上传的了,并且我最后部署到了streamlit的服务器中,大家都可以在线体验 https://kedreamix-yologesture.streamlit.app/,然后选择“Run the app”即可,不需要过多的操作,云端服务器会会自动从我的release中下载模型,所以这个不用担心。
关于streamlit的一些方法,可以看一下我另一篇博客,也有对应的github链接,那个简单一点https://redamancy.blog.csdn.net/article/details/121788919

8.1. 本地运行
打开命令行运行以下代码,记住,首先进行pip install streamlit
streamlit run gesture.streamlit.py
运行之后,打开的 https://localhost:8501 就可以看到自己的streamlit的界面了

8.2. 检测方法
在这个部署界面中,我一共设了几种方式,分别是
| 测试模型方式 | 测试方式描述 |
|---|---|
| Example | 已有一部分数据在服务器的文件夹里,可以读取进行检测 |
| Image | 可以自主上传对应的图片进行检测
|
| Camera | 利用电脑摄像头进行检测,对摄像头进行拍照,然后可以检测fps,heatmap
|
| FPS | 上传一张图片进行FPS |
| Heatmap | 进行一个热力图的检测,可以看到模型关注哪一部分
|
| Real Time | 实时检测,可能这一部分在云服务器有点bug,可能要在自己电脑下才能正常运行,云端不可用 |
| Video | 传入视频进行检测
|
8.3. 选择模型以及参数
并且在下面的部分,也设置了几个参数,首先是使用的模型,根据前面所说的,一共有五种模型,并且可以调节传入的shape,这里注意一下,如果选择tiny模型,要勾选☑️使用tiny模型,要不默认全是yolov4模型,然后tiny模型的shape统一只有416,只有yolov4模型有一个608和416,可以根据自己的情况选择。
除此之外,还可以调节一下confidence和nms的参数,默认分别是0.5和0.3,这个是可以通过滑动杆来修改的

9. 参考Reference
- https://github.com/bubbliiiing/yolov4-pytorch
- https://github.com/qqwweee/keras-yolo3/
- https://github.com/Ma-Dan/keras-yolo4
10. 代码权重可复现,已开源(求🌟🌟🌟)
所有的上述代码权重全部可复现,已经全部开源,有需要可以自取https://github.com/Kedreamix/YoloGesture文章来源:https://www.toymoban.com/news/detail-439054.html
有问题欢迎在issue中讨论,最后创作不易,给我个星星吧哈哈哈star一下,🌟🌟🌟文章来源地址https://www.toymoban.com/news/detail-439054.html
到了这里,关于基于计算机视觉手势识别控制系统YoloGesture (利用YOLO实现) 有详细代码+部署+在线服务器尝试+开源可复现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!