题目可见文章:(20条消息) 如何治理“网络暴力” 在人类文明不断发展向前的进程中,大数据时代应运而来。 数学建模,90%成品论文,附附件、原题、代码 注,水平有限,非广告,仅供交流参考,欢迎朋友们指出问题~_区分a市网民的价值观念群体_feiwu小天才的博客-CSDN博客
摘要
随着互联网的普及,广大网络用户获得了更方便,更广泛的表达渠道。但由于互联网的匿名性,使得网络社区也出现了无序的情绪宣泄和肆意的网络暴力。表达有边界,流量有底线。尽管如此,互联网也并非法外之地。2022 年初,中央网信办开展了“清朗·2022 年春节网络环境整治”专项行动,重点整治的五个方面任务中“网络暴力、散播谣言等问题”首当其冲。
某社交平台在A市试点抽样统计了近一个月内匿名网民在社交平台上公开发表的言论,并对常用词条出现的次数进行统计。另外,在同一个月内,该平台还对分享了地理位置的匿名网民的公开言论也以社区为单位进行了统计,题目要求基于二者数据进行建模研究。
针对问题一,由于有相同的价值观的网民其语言的情感色彩往往有趋同性,题目要求根据数据1,建立适当的模型,以便区分A市网民的价值观念群体。首先基于数据类型,判断应选择Q型聚类,此处以轮廓系数作为聚类数量选取标准,通过K-Means聚类方法来对数据进行聚类,再使用PCA方法 将数据降维为二维数据进行数据可视化展示,验证得出聚类结果较好。
针对问题二,题目给出前提“‘键盘侠’是相对少数存在的群体”,以此为标准,根据问题一给出的聚类结果,将少数群体判断为“可能存在的‘键盘侠’们”,题目要求构建合理算法识别出可能存在的“键盘侠”们,首先将“键盘侠”和“非键盘侠”分别定义标签“1”、“0”,使用随机森林算法进行分类训练,所得模型识别准确度可达100%,保存模型,此模型即为所求。同时题目要求给出“键盘侠”们与其他群体不同的词条,此处通过主成分分析进行主成分提取,即“键盘侠”们与其他群体不同的词条。
针对问题三,每个社区由不同群体的网民组成,题目要求基于此,根据附件2所给数据,结合问题一中结果,建立算法分析每个社区中不同群体网民的比例。在不存在其他任何因素影响的前提下,将社区特征属于某中分类的概率视作社区中该中网民的比例。根据问题二的结果,将“键盘侠”聚为一类,共41类,与问题一中聚类结果结合,得到新的聚类结果,使用随机森林分类训练,所得模型识别准确度可达100%,调用此模型,得到预测结果中分属每种类别的概率,即该社区中属于此网民种类的比例,即可得到不同社区中不同群体网民的组成比例。
针对问题四,题目要求基于提供的数据建立算法,对 A 市进行较为合理的功能区划分,并针对划分的结果提出治理“网络暴力”的解决方案或者建议。假设同一位置可以同时具有几种功能,即同一区域可分属不同功能区。首先采用K-Means方法对所有社区进行词条特征聚类,对于同一类别的社区,采用DBSCAN聚类进行空间聚类,即可得到不同的功能区域划分。基于以上,通过分析即可给出合理建议。
关键词:K-Means聚类分析、MAD、PCA、随机森林分类预测、DBSCAN空间聚类
一、问题重述
1.1问题背景
随着新媒体环境的到来,网民获取信息的途径越来越多样化,表达自己意见的方式更为便捷,但是也产生了诸多问题,比如网络暴力,其对社会的负面影响不容小觑,“网络暴力”与传统意义中的暴力不同,其发源于网络公共领域,主要通过非法利用他人信息、散布谣言、恶意炒作、言语攻击等方式对网络事件当事人施暴,甚至将线上暴力转到线下,侵犯当事人的个人隐私甚至威胁到人身安全,践踏了法律的尊严,破坏了和谐健康的社会环境。2022 年初,中央网信办开展了为期 1 个月的“清朗·2022 年春节网络环境整治”专项行动,其中重点整治的五个方面任务,排在首位的就是“网络暴力、散播谣言等问题”。
1.2问题重述
在社交平台上发表的言论在一定程度上能够反映出一个人的价值观,因此有相同的价值观的网民其语言的情感色彩往往有趋同性。问题一要求我们基于此对附件1中的数据进行不同价值观念群体的区分。
“键盘侠”在网民中是少数存在的群体,题目二要求我们基于此前提,结合问题一中的结果,建立识别算法,可以识别出潜在于网络中的“键盘侠”们,同时给出“键盘侠”们与其他群体不同的词条。
每个社区都是由不同群体的网民组成的。附件2是不同社区(一个社区包含多个网民)在一个月内的发言的统计数据。问题四要求一句附件2的数据,同时结合问题1的结果,给出每个社区不同群体的组成比例。
城市能够根据不同的功能划分为多个区域,其中不同的功能区由附近多个小的社区组成,而同一功能区的网络言论往往有一些相似性。问题四要求我们基于提供的数据建立可以第A市进行合理的功能区划分的算法,并提出治理“网络暴力”的解决方案或者建议。
二、分析方法与过程
2.1问题分析
针对问题一,题目要求对附件1中的数据以不同网民为单位,以不同词条为不同特征进行多特征聚类分析,基于数据特征,应采用Q型聚类,则选择K-Means聚类方法来对数据进行聚类。由于不清晰应聚类数量,则选择轮廓系数(silhouette_score)作为判断,绘制轮廓系数折线图观察不同聚类数量的轮廓系数结果,选取折现下降趋势趋于稳定后的最小值为最优聚类数量,再据此数量进行聚类分析,得到结果后用PCA方法将数据特征的维度降至2维以方便数据聚类后展示。
针对问题二,题目给出前提“‘键盘侠’是相对少数存在的群体”,以此为标准,根据问题一给出的聚类结果,将少数群体判断为“可能存在的‘键盘侠’们”。题目要求构建合理算法识别出可能存在的“键盘侠”们,首先将“键盘侠”和“非键盘侠”分别定义标签“1”、“0”,使用随机森林算法进行分类训练,所得模型识别准确度可达100%,保存模型,此模型即为所求。同时题目要求给出“键盘侠”们与其他群体不同的词条,此处要求使用合理的方法提取出对对判断某网民是否为“键盘侠”的主要词条,可以采取主成分分析法,对标签为“1”的数据进行主成分分析,得到结果中,影响较大的词条即为所求。
针对问题三,每个社区由不同群体的网民组成,题目要求基于此,根据附件2所给数据,结合问题一中结果,建立算法分析每个社区中不同群体网民的比例。在不存在其他任何因素影响的前提下,将社区特征属于某中分类的概率视作社区中该中网民的比例。根据问题二的结果,将“键盘侠”聚为一类,与问题一中聚类结果结合,得到新的聚类结果,即将问题一结果列表中的所有在第二问判断为“1”的数据合并,人数相加,合成新的类别。使用随机森林分类训练,所得模型识别准确度依旧可达100%,调用此模型,得到预测结果中分属每种类别的概率,即该社区中属于此网民种类的比例,即可得到不同社区中不同群体网民的组成比例。
针对问题四,题目要求基于提供的数据建立算法,对 A 市进行较为合理的功能区划分,并针对划分的结果提出治理“网络暴力”的解决方案或者建议。假设同一位置可以同时具有几种功能,即同一区域可分属不同功能区。首先采用K-Means方法对所有社区进行词条特征聚类,对于同一类别的社区,采用DBSCAN聚类进行空间聚类,即可得到不同的功能区域划分。基于以上,通过分析即可给出合理建议。
三、模型假设
- 假设仅根据所给数据中的特征,足以判断某网民是否为“可能存在的‘键盘侠’”。
- 假设在输入被预测值时,输出的此被预测值属于每个种类的概率,可以认为在社区中有同等比例的网民属于该种类。
- 假设同一社区可以同属不同功能区,即同一社区可以同时具有不同功能,即同一社区可同时归为不同功能区内。
- 假设无任何其他因素对判断“键盘侠”结果可能造成影响
四、特征工程
4.1数据分析
4.1.1数据描述
附件 1:不同网民在一个月内发言的统计数据。行代表网民(netizen),共随机抽样了8449个网 民。列代表词条(word),共有 17681 个不同的词条。数据中每一个元素代表统计得到的某一个网 民发言的某个词的个数(单位是百)。
附件 2:不同社区(一个社区包含多个网民)在一个月内的发言的统计数据。行代表社区(community) 共统计了 604 个社区的发言。列代表词条(word),共有 17681 个不同的词条。最后一列(position) 代表该社区的位置坐标(坐标是用 x 号隔开,例如 26.96x7.97 代表(26.96,7.97))。数据中每一个元素代表统计得到的某一个社区内的网民发言的某个词的个数(单位是百)。
其中,为了去除词条的敏感性,该数据不提供每一词条的具体含义。并且为了保护共享地理位置的 网民隐私,附件 2 只测量了社区总体网民发言的次数。
4.1.2 描述性统计
针对附件1,首先使用Jupter Notebook软件对数据进行整体查看。得到附件一表格共8449行,17682列,即共有8449名网民参与统计,共统计了17681个词条,和附件1数据描述相同,可以进行下一步计算。再调用describe()函数计算出附件1中所给数据中的非空值数(count)、平均值(mean)、标准差(std)、最大值(max)、最小值(min)、(25%、50%、75%)分位数8个指标,由于数据量巨大,详见于附录—支撑材料—计算结果文件—描述性统计1.csv。
针对附件2,首先使用Jupter Notebook软件对数据进行整体查看。得到附件一表格共604行,17682列,即共有604个社区参与统计,共统计了17681个词条,和附件2数据描述相同,可以进行下一步计算。再调用describe()函数计算出附件1中所给数据中的非空值数(count)、平均值(mean)、标准差(std)、最大值(max)、最小值(min)、(25%、50%、75%)分位数8个指标,由于数据量巨大,详见于附录—支撑材料—计算结果文件—描述性统计2.csv。
4.2数据预处理
4.2.1缺失值处理
现实生活中,很可能由于种种原因,以上数据产生缺失。
针对附件1,由描述性统计1结果可知,所给数据中并非缺失数据均等于8449,不存在缺失值,所以暂不考虑由缺失值带来的影响,即不进行缺失值处理操作。
针对附件2,由描述性统计2结果可知,所给数据中并非缺失数据均等于604,不存在缺失值,所以暂不考虑由缺失值带来的影响,即不进行缺失值处理操作。
4.2.2异常值处理
针对附件1,由描述性统计可知,所给数据中不存在缺失值,现只须对数据尽行异常值处理,因为数据与时间并无关系,不存在时间序列,所以选择进行替换极值处理的方法进行异常值处理。由于MAD法对样本量不敏感,即使是在大规模数据中依然可行,且MAD法对异常值不敏感,不会因为特殊的异常值而导致估计的严重偏差,故使用绝对中位差法进行去极值处理,处理方法如下图所示。

图1.MAD处理方法
一般去极值的原理为先确定该项指标的上下限,然后找出超出限值的数据,并将它们的值统统变为限值,其中离群值及限值演示图如下所示。
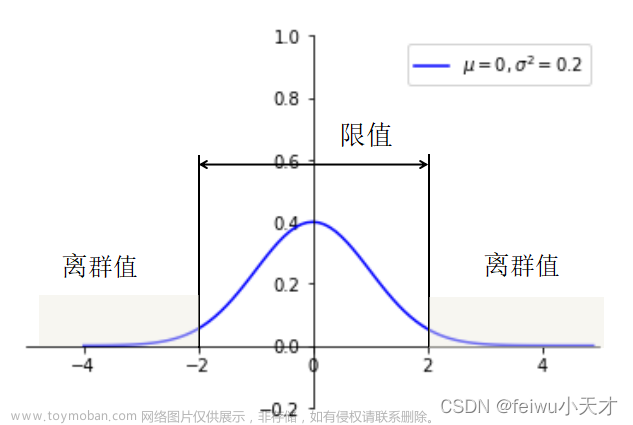
图2.离群值及限值演示图
由于样本量巨大,暂不在文中展示结果,数据处理结果详见于附录—支撑材料—特征工程计算结果—MAD附件1处理后描述性统计.csv。
同理,针对问题二,使用MAD方法进行异常值处理,数据处理后描述性统计结果详见于附录—支撑材料—特征工程计算结果—MAD附件2处理后描述性统计.csv。
五、第一问模型建立及求解
由于在社交平台上发表的言论在一定程度上能够反映出一个人的价值观,所以有相同的价值观的网民其语言的情感色彩往往有趋同性。基于此,问题一要求我们基于此对附件1中的数据进行不同价值观念群体的区分。可以采用K-Means的方法进行对A市网民进行聚类。
5.1K-Means算法简介
5.1.1K-Means算法
K-means算法也称之为均值算法,是聚类分析中比较成熟的方法,其中心思想是在欧几里得空间中划分个数据对象,通过初始中心策略实现对象选择,使其成为聚类中心。再对其他对象计算和每个质心距离,使用最近的归类,再次对每个簇数据平均值进行计算,能够得到全新聚类中心,对此过程反复进行迭代计算,直到全部聚类收敛,具体算法流程如附录表1所示。
一般来说,聚类数的确定是K-means算法的重要部分,很多研究根据行业的经验来确定聚类数,但是这种方法带有主观性,结果不一定是数据的真实聚类数,因此研究领域会使用数据自身来确定真实的聚类数。通过数据自身来确定聚类数的方法有2种,一种是误差平方和(SSE)方法,另一种是轮廓系数法,此处使用轮廓系数法进行聚类数量确定。
5.1.2轮廓系数法
该方法是以确定样本的轮廓系数S为目标,某个样本点Xi的轮廓系数S定义如下式:
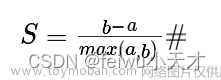
式中,α是Xi与相同簇的其他样本的平均距离,称为凝聚度,b是Xi与最近簇中所有样本的平均距离,称为分离度。
求出所有样本的轮廓系数后再求平均值就得到了平均轮廓系数。平均轮廓系数的取值范围为[-1,1],且簇内样本的距离越近,簇间样本距离越远,平均轮廓系数越大,聚类效果越好。这样平均轮廓系数最大的便是最佳聚类数。本研究同时使用2种聚类数的标准,并选取其中较为合适的为聚类标准。
5.2最优聚类系数选取
由于A市网民课分成的类别数量为未知数,所以并不能在K-Means聚类分析中直接赋予种类数量,因此选择一个衡量聚类结果好坏的指标作为标准,从而根据该指标选取合适的聚类数量是较合理的方法,此处选用轮廓系数作为评价指标。
我们采用循环的方式计算从2至100类K-Means聚类,同时计算出附件1数据的轮廓系数,得到最优聚类数量选取图如下。

图3.最优聚类数量选取图
通过上图可以看出,大致最有数量位于90至100之间,根据程序,输出最优聚类数量为94。
5.3模型建立及求解
得到最优聚类数量之后,对附件1数据进行聚类,由于直接计算得出的结果数据过于庞大,暂不在文中全部展示,详见于附录—支撑材料—计算结果文件—new_df最优聚类.csv。
表1.部分聚类结果展示
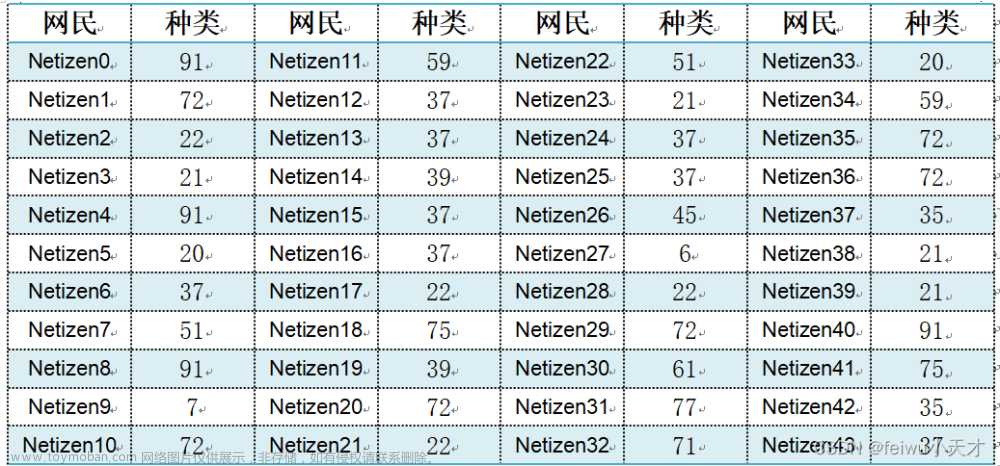
为方便展示结果展示,现将多维特征经过PCA(主成分分析法)算法降至二维,绘制散点图如下所示。

图4.最优聚类结果二维展示图
由最优聚类二维散点图可以看出,同一类别的居民分布较近,且正相关趋势较大,具有较强可信度。
六、第二问模型建立及求解
问题二要求结合问题1的计算结果,识别可能存在的“键盘侠”们,并给出“键盘侠”们与其他群体不同的词条。由于“键盘侠”是相对少数存在的群体,所以选取聚类后数量较少的几个类别相加,认作“可能存在的‘键盘侠’”,对所有“可能存在的‘键盘侠’”的词条分别做主成分分析,即可得出其与其他群体不同的词条。使用随机森林预测进行模型训练,得到“可能存在的‘键盘侠’”预测算法。
6.1 “可能存在的‘键盘侠’”选取
由问题一聚类结果可以得到不同类别中网民的数量,制作不同种类网民数量柱状图,如下所示。
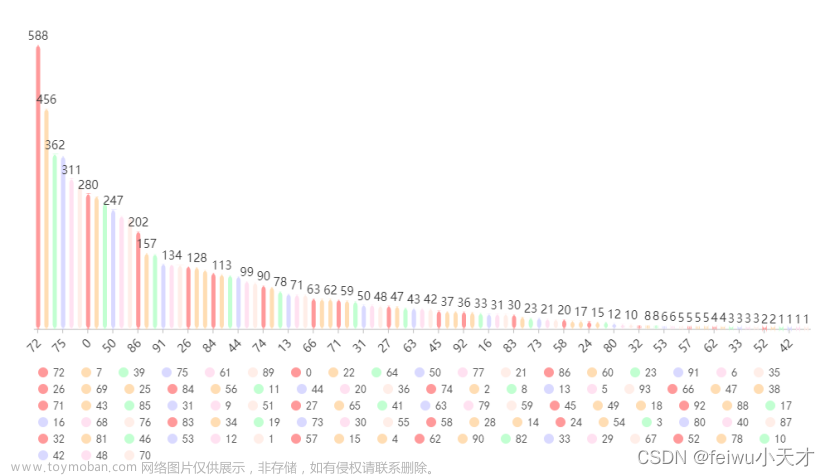
图5.不同种类网民数量柱状图
现实生活中,由于人与人之间兴趣、爱好、价值观等存在偏差,所以键盘侠也应存在不同种类,且“可能存在的‘键盘侠’”为数量较少的存在,依据不同种类网民数量柱状图,不难发现从种类序号72至55,柱状图呈较快下降趋势,且每个种类人数较多,之后柱状图成缓慢下降趋势,且人数较少,暂取种类58、28、14、24、54、3、80、40、87、32、81、46、53、12、1、57、15、4、62、90、82、33、29、67、52、78、10、42、48、70为“可能存在的‘键盘侠’”。设“可能存在的‘键盘侠’”为1,其他群体为0,则“可能存在的‘键盘侠’”数量为1082,普通网民数量为7367,得到饼状图如下。

图6.潜在“键盘侠”与普通网民数量分布饼状图
6.2识别模型的建立
6.2.1随机森林介绍
2001年Leo Breiman把分类树组合成随机森林(Random Forest,RF),即在变量和数据的使用上进行随机化,得到一定数量的分类树,再将分类树的结果进行汇总,提出随机森林算法。
决策树模型结构与树的结构类似,分为根节点、内部节点和叶子节点。根节点为全部特征,内部节点为某一特征,叶子节点为预测结果,通过不断分枝和生长得到最终结果。
随机森林回归算法以决策树为基础,从原始训练数据集中有放回的随机抽取K个新的数据集,生成K颗决策树,形成随机森林,最终预测结果为所有决策树预测结果的均值。模型的基本流程如图3,算法基本步骤如下:
- 从原始训练集S中应用bootstrap法有放回的随机抽取N个数据集,产生N颗决策树。
- 决策树采用CART决策树,每次生长分支时,从M个特征属性中随机选取m个特征(m≤M),衡量分支质量的指标为均方误差(mean squared error,MSE),公式如下:
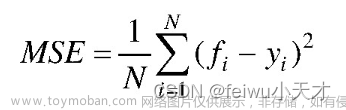
式中,N为样本数量;i是一个数据样本;fi是模型预测值;yi是样本i的实际值。
3. 依据均方误差选取最优特征最大限度分支生长,中间过程不进行剪枝。
4. 将所有决策树的预测结果取均值则为最终预测结果,即:
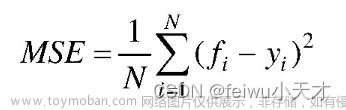
6.2.2模型的建立
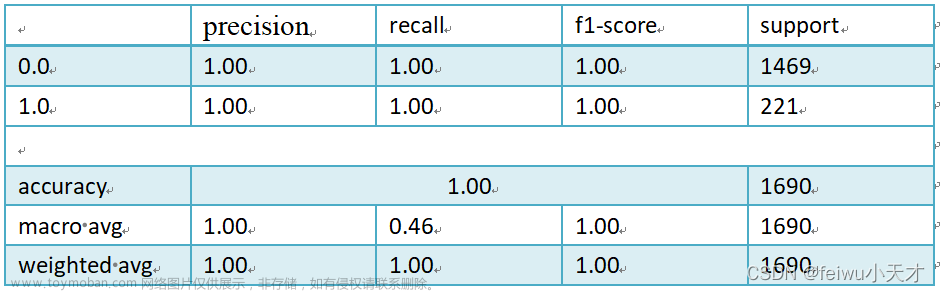
本文使用Jupter Notebook对预处理后的数据进行预测,即识别“可能存在的‘键盘侠’”的合理算法。该算法精确度可达100%,具体结果如下表所示。
表2. 问题二随机森林模型精确度展示表
训练好的模型保存为“model.pkl”,详见于附件—支撑材料—第二问结果。
使用joblib.load()即可调用此模型,使用predict()函数即可开始识别是否为“可能存在的‘键盘侠’”(结果为1即为是,0即为不是)。
七、第三问模型建立及求解
每个社区由不同群体的网民组成。问题三要求根据附件2中的数据,并结合问题1的结果,建立算法分析每个社区中不同群体网民的组成比例。

图7.整合“键盘侠”后个群体数量展示玫瑰图
7.1模型的建立及求解
本文使用Jupter Notebook对预处理后的数据进行预测,即不同类别网民的合理算法。该算法精确度可达100%,具体结果如下表所示。
表3. 问题三随机森林模型精确度展示表
| precision |
recall |
f1-score |
support |
|
| accuracy |
1.00 |
1690 |
||
| macro avg |
1.00 |
0.46 |
1.00 |
1690 |
| weighted avg |
1.00 |
1.00 |
1.00 |
1690 |
训练好的模型保存为“model3.pkl”,详见于附件—支撑材料—第二问结果。
使用joblib.load()即可调用此模型,使用predict()函数即可开始判断网民所属种类。
假设在输入被预测值时,输出的此被预测值属于每个种类的概率,可以认为在社区中有同等比例的网民属于该种类。调用sklearn包中的predict_proba()即可得到每各社区中不同类别人群的比例。详见于附录—支撑材料—第三问计算结果—各社区不同种类网民比例.csv。
八、第四问模型建立及求解
城市能够根据不同的功能划分为多个区域(如大学城,商业区等等),不同的功能区由附近多个小的社区组成。同一功能区的网络言论往往有一些相似性(如大学城的学生较多,所发表的言论也有相似之处)。第四问要求基于数据建立算法,对 A 市进行较为合理的功能区划分,并针对划分的结果提出治理“网络暴力”的解决方案或者建议。
8.1 数据可视化
将附件2中的position数据按分隔符为x进行分列,再绘制坐标图如下所示。
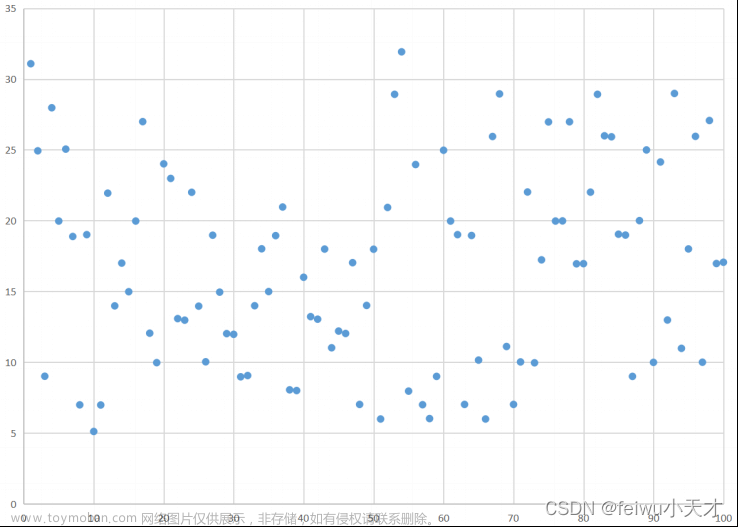
图8.社区坐标图
8.1 K-Means词条特征聚类分析
首先应进行最优聚类数量分析,由图可知,最优数量接近50,根据程序得出准确数值为48,即以48为聚类数量可得到较好的聚类结果。
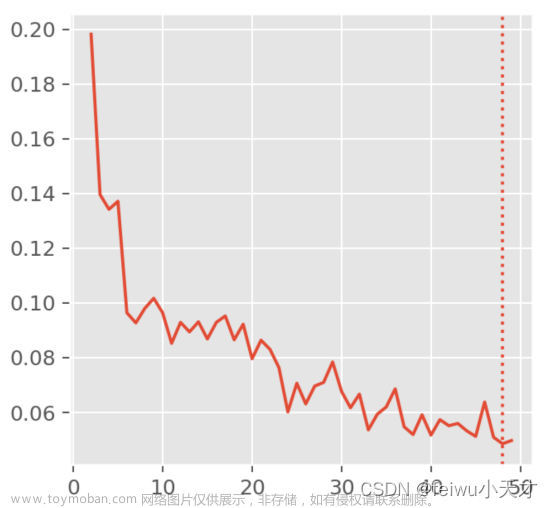
图9.社区最优聚类数量选取图
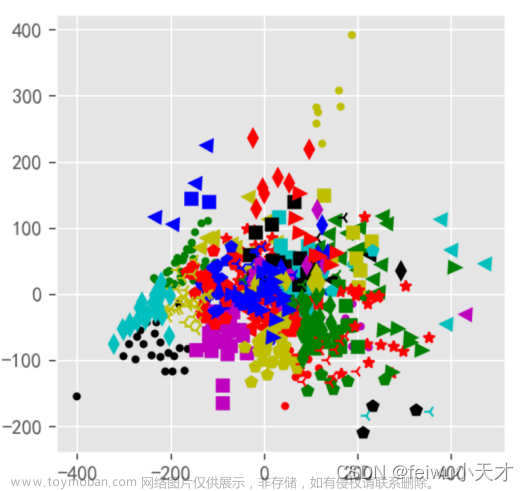
图10.社区最优聚类二维展示图
8.2 DBSCAN地点特征聚类
按照K-MEANS聚类分析中区分好的不同类别,将各个社区坐标散点图绘制如下。
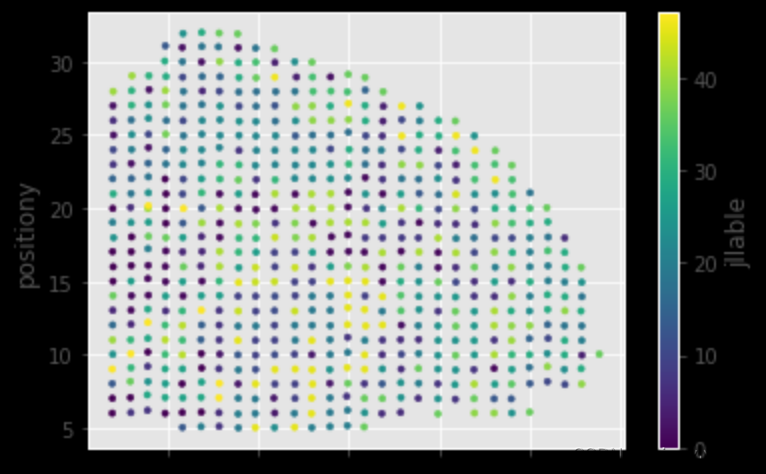
图11.社区不同类别地理位置散点图
因为城市能够根据不同的功能划分为多个区域(如大学城,商业区等等),不同的功能区由附近多个小的社区组成。假设同一个社区可以同属多个功能区,将每一类别单独进行距离聚类。由于类别较多,现只拿类别0做示例。
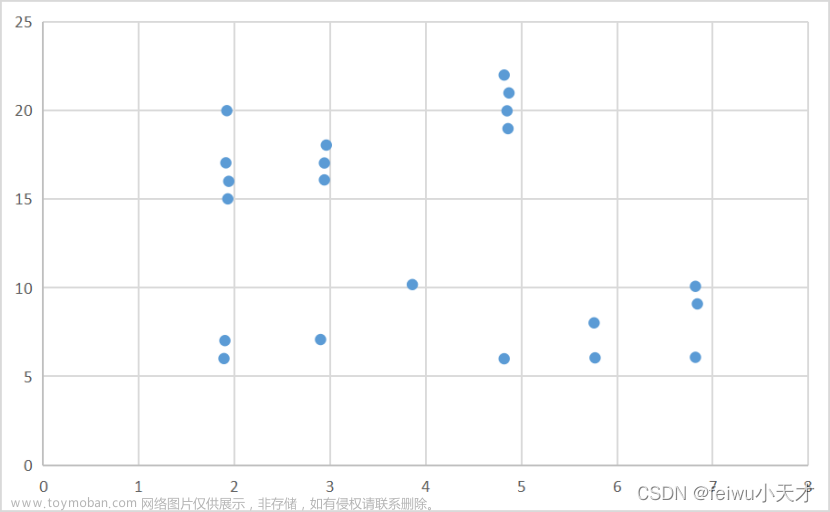
图12.社区类别0地理位置散点图
K-Means聚类后类别0DBSCAN聚类后结果如下图所示。
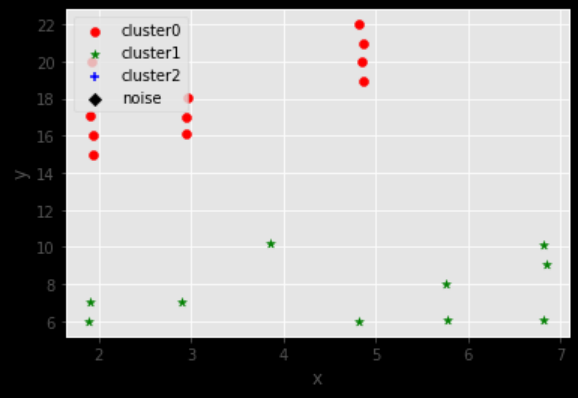
图13.社区类别0的DBSCAN聚类后地理位置散点图
如图所示,在K-Means聚类后再经过DBSCAN经过空间聚类,即可划分出2个功能区,其余聚类详见附录—支撑材料—问题四计算结果—功能区划分0-47.csv。
8.3 治理“网络暴力”的建议
1. 完善网络法律体系,目前网络环境已发生重大变化,社交平台流量与量激增,原有司法解释在行为特征、转发条数的立案标准等方面,均需做出相应修改。应当根据、微博等主流社交平台的信息发布模式,设置新的规范准则,尤其是立案标准以及作为公诉案件处理的标准,使法律规范更加适应当今社会的发展变化,同时也能为司法工作人员明确诽谤罪的公诉界限,维护自诉程序的独立价值,在公共利益与被害人隐私和个人意愿中取得平衡。
现阶段的技术手段完全可以达到高精度识别,并可以建立不同功能去言论识别系统,对于异常言论及审核,同时可以及时线上私信警告的程度。在系统识别为某网民为可能的“键盘侠”或其发言存在敏感词汇,立即发送信息对其进行警告,若再三警告依旧不改正,则依法处理。
2. 网络平台应主动自觉承担起监管责任。作为社会信息传播的重要媒介,应该承担起引领社会正能量的社会责任,加强对网络用户发布信息进行审校和管理,强化针对平台和个人的惩罚机制建设。政府应该成为网络平台监督的推动者,建立网络服务商和网民自觉协助配合政府监管机制,共同为净化网络环境保驾护航。本题中数据即为某平台提供,若网络平台都能有此众自觉监督监管的责任,那么从传播渠道层面即可减少很多的“网络暴力”言论。
3.探索建立网络实名制。网络实名制从网络主体入手,约束网民自觉遵守网络公共道德,建立网络诚信,从源头上规范网民网络行为,毕竟,实名网民在发声前会考虑自己的身份及影响。网络实名制将虚拟的网络行为与真实的人物身份对接,实现虚拟人与现实人、自由人与责任人、经济人与社会人的和谐统一。通过加强现实社会责任在网络里的延伸,对预防网络暴力、网络犯罪都能起到很好作用。
十、模型评价
10.1 模型优点
1.该模型在进行“可能存在的‘键盘侠’”识别算法建模后又进行了TPE超参数调优,得到的识别模型精确度得以提升。文章来源:https://www.toymoban.com/news/detail-439055.html
10.2 模型缺点
1.选取“可能存在的‘键盘侠’”时,仅考虑了数量较少的部分,主观性过强,说服性不高。文章来源地址https://www.toymoban.com/news/detail-439055.html
到了这里,关于如何治理“网络暴力” 在人类文明不断发展向前的进程中,大数据时代应运而来。数学建模解题步骤,愚见而已,欢迎指错和探讨呀~的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!