一:网络创新点
传统DETR提出的encoder-decoder结构,将transformer运用到了目标检测领域,在我看来属于Resnet相对于Alexnet的里程碑级别,思路很开辟但是细节还欠打磨,我分析一下DETR中的缺点:
- 收敛速度慢。因为keys的选取自整个特征图上的每个像素点,复杂度是指数级别的暴增。注意力初始分布十分平均,Dense-to-Sparse的效果不好。
- 精度不高,特别是对于小目标检测效果更差。原因用论文中的话说,
the deficits of Transformer attention in handling image feature maps as key elements,Modern object detectors use high-resolution feature maps to better detect small objects. However, high-resolution feature maps would lead to an unacceptable complexity for the self-attention module in the Transformer encoder of DETR, which has a quadratic complexity with the spatial size of input feature maps。究其原因是特征图处理模块少,也没有什么类似FPN这种低维和高维特征融合的手段。
针对以上的几个问题,Deformable DETR依次提出如下思路:
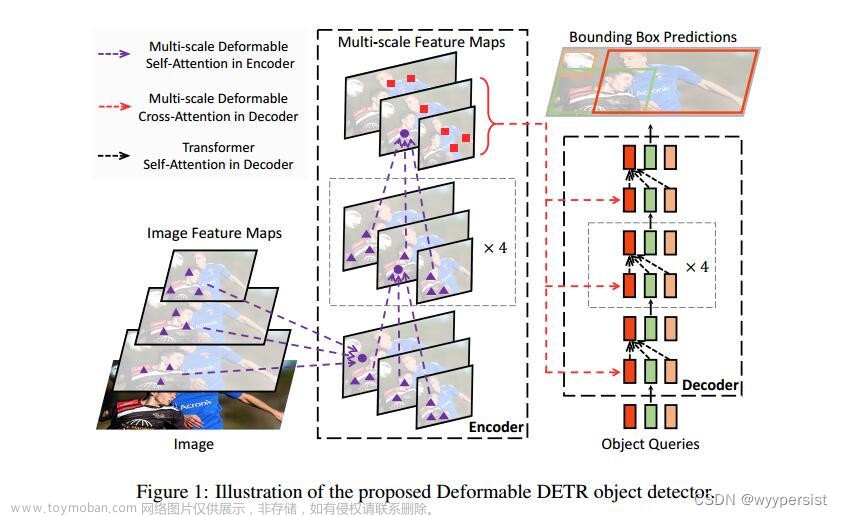
- key的选取不再是全图所有的像素点,而是每一个query在特征图上对应一个reference_point,基于每个reference_point再选取n = 4(源码中设置)个keys,根据Linear生成的attention_weights进行特征融合(注意注意力权重不是Q*k算来的,而是对query直接Linear得到的)。这样大大提高了收敛速度,而是有选择性的注意Sparse区域来训练attention
- 为了提高小目标检测效果,没有使用FPN,而是提取了backbone中C3~C5和用3✖3 kernel_size、(2, 2)stride得到的C6这四个特征图,每个query的head在这四个各取4个key,然后融合更新
- 后期作者还增加了Iterative Bounding Box Refinement,根据decoder上一层Layer输出结果,迭代更新bounding box,大大提高了预测准确率。
- 作者还增加了two-stage升级版结构,回到了检测的经典思想中,性能参数都有一定提高。由于较复杂,这里暂不讲。
二:流程详解
【part 1】deformable_detr模块
- 首先分析deformable_detr模块,从backbone的C3~C5提取出3个srcs和pos_embeds,将C5进行stride=2的下采样操作,得到第四个src和pos_embed。然后对四个srcs进行Linear,把channels变为hidden_dim,得到下图结果,pos_embeds的shape和变换通道后的srcs的shape相同:

- deformable_detr模块还初始化了query_embeds,
self.query_embed = nn.Embedding(num_queries, hidden_dim*2),即(10, 128),10是代码中设置的query_num。值得注意的是128,因为这里的self.query_embed一半是tgt,一半是pos_embeds。 - 将它们传给deformable_transformer模块中,self.transformer(srcs, masks, pos, query_embeds)
【part 2】deformable_transformer模块
- 首先对传入的数据做flatten()处理,打印如下:

- 接着将处理后的数据传入encoder模块中,
memory = self.encoder(src_flatten, spatial_shapes, level_start_index, valid_ratios, lvl_pos_embed_flatten, mask_flatten),让我们一起进入encoder模块看一看
【part3】Encoder模块

- 首先通过
self.get_reference_points(spatial_shapes, valid_ratios, device=src.device)得到reference_points,shape为 [2, 15060, 4 , 2],得到的是在每一层特征图中的相对位置(0 ~ 1)。处理方法如下:
- 接下来进入EncoderLayer层中,传入数据的shape可见图,EncoderLayer的forward结构如下:
 下面让我们重点看一下网络核心模块MSDeformAttn,对应着self.self_attn()
下面让我们重点看一下网络核心模块MSDeformAttn,对应着self.self_attn()
【part 4】MSDeformAttn

-
就是将加了pos_embeds的srcs作为query传入,通过Linear生成sampling_offsets和attention_weights,分别对应着每个query的每个head在每个特征层选取的4个keys和权重,可见这里的weight不是QK后生成的,而是直接Linear得到的。
-
最后传入MSDeformAttnFunction功能模块进行特征融合,实现细节略,输出memory。
-
结束了encoder模块,输出了memory。退回到deformable_transformer模块:

-
可见,就是将10个query_embed做了一下复制、拆分,得到真正的query_embed(decoder中也作为query_pos)和tgt,接着将query_embed传入Linear中得到reference_points,最后都传入Decoder中
【part5】Decoder模块


- 简单处理一下reference_points后,循环进入DecoderLayer中,可以对中间output和reference_points储存,如果加了bbox refinement那么reference_points会一次次改变。Layer结构如下:

- 先是自注意力,注意这里没有使用MSDeformAttn,而是正常的MutiheadAttention。然后交叉注意力,得到最终结果。
最后,让我们回到Deformable_Detr模块,从self.transformer中输出结果如下:
 后面根据任务转换输出结果的channels,之后就是基本的匈牙利匹配➕损失计算了,和Detr差不多。有一点值得注意,bbox的pred结果是reference_point + self.bbox_embed(hs[i])[…,:2]。相当于网络输出预测是长、宽和基于reference_point的偏移量!!!
后面根据任务转换输出结果的channels,之后就是基本的匈牙利匹配➕损失计算了,和Detr差不多。有一点值得注意,bbox的pred结果是reference_point + self.bbox_embed(hs[i])[…,:2]。相当于网络输出预测是长、宽和基于reference_point的偏移量!!!
至此我对Deformable DETR源码中全部的流程与细节,进行了深度讲解,希望对大家有所帮助,有不懂的地方或者建议,欢迎大家在下方留言评论。文章来源:https://www.toymoban.com/news/detail-439315.html
我是努力在CV泥潭中摸爬滚打的江南咸鱼,我们一起努力,不留遗憾!文章来源地址https://www.toymoban.com/news/detail-439315.html
到了这里,关于Deformable DETR源码解读的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!