前言
最近 LLM 模型很火,chatGPT 涵盖的知识范围之广,令人叹为观止。然而码农肯定不能满足于现有的知识库,要扩展自有数据才能发挥其更大的实用价值。
一般来说,深度学习模型大多采用 finetune 的方式来增加训练数据,但 LLM 模型太大了,训练成本过高。无论是离线或是在线训练样本,短时间只有 OpenAI 可为。随着通用大模型的兴起,另外一种被称为 ”前导词注入“ 的提示工程(prompt)逐渐成熟,也能接入自有数据。
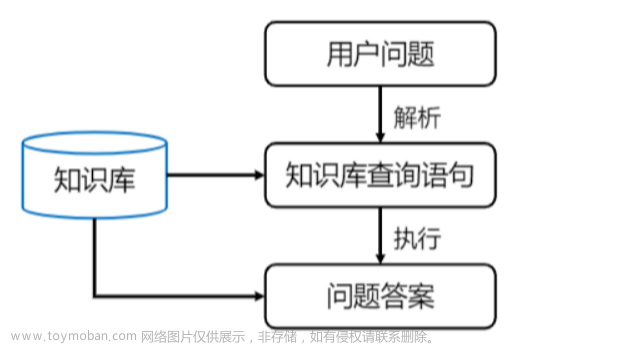
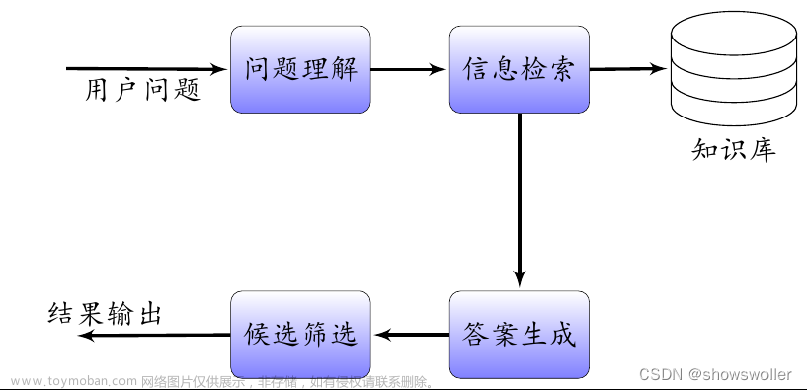
本篇主要采用后面这种方法,将软件开发文档转换为矢量数据,再通过 chatGPT 构建更好的问答交互体验,利用强大的归纳搜索能力,大大提高信息获取效率。

环境准备
安装 python 3.8
conda create -n chat python=3.8
conda activate chat配置 jupyter 环境
conda install ipykernel
python -m ipykernel install --user --name chat --display-name "chat"安装 pytorch
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116
这里注意版本匹配,我笔记本上采用的是 cuda 11.6 的版本。若显卡不够强大的话,也可以安装 cpu 版本。
安装依赖
pip install langchain
pip install unstructured
pip install openai
pip install pybind11
pip install chromadb
pip install Cython
pip3 install "git+https://github.com/philferriere/cocoapi.git#egg=pycocotools&subdirectory=PythonAPI"
pip install unstructured[local-inference]
pip install layoutparser[layoutmodels,tesseract]
pip install pytesseract安装编译 detectron2
git clone https://github.com/facebookresearch/detectron2.git
python -m pip install -e detectron2
由于要在 windows 环境下通过源码编译 detectron2,这里有几个坑要提示一下:
pdf2image 出错
pdf2image.exceptions.PDFInfoNotInstalledError: Unable to get page count. Is poppler installed and in PATH?
https://github.com/oschwartz10612/poppler-windows/releases/下载 poppler,并添加环境变量。
pdfminer 与 pdfminer.six 版本冲突
'LTChar' object has no attribute 'graphicstate' Error in a docker container卸载 pdfminer 和 pdfminer.six 后重新安装即可修复。

gcc 和 ninja
编译过程中需要配置 gcc,我这里采用的是 MinGW,而 ninja 在windows 下并非可选(否则编译不通过),需放置到 Path 下。(文末有相关文件下载链接)

准备训练数据
将 pdf 文档 放置于 /text 目录下,可放置多个文件,这里使用的是音视频的开发文档 meeting.pdf。
jupyter notebook
import os
os.environ['OPENAI_API_KEY'] = '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'万事俱备,我们来配置一下 OpenAI 的 api key。(这里省略一万步,最近申请 ChatGPT 的难度又提升了不少,看来白嫖党给 OpenAI 的算力压力很大啊~~,plus 又对国内发行的国际信用卡拒绝,总之很烦)
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.indexes import VectorstoreIndexCreator配置训练采用 gpu 或是 cpu
from detectron2.config import get_cfg
cfg = get_cfg()
cfg.MODEL.DEVICE = 'gpu' #GPU is recommended将自定义数据导入loader
text_folder = 'text'
loaders = [UnstructuredPDFLoader(os.path.join(text_folder, fn)) for fn in os.listdir(text_folder)]
训练数据
文本矢量化,并接入 ChatGPT
index = VectorstoreIndexCreator().from_loaders(loaders)由于开发文档非常小(169k),在我的 1060 的显卡上只需要不到1分钟就完成了训练,cpu 会稍微慢些。

API 的 使用费用也十分的低廉,免费额度够用100多次。重度使用者,估计要考虑上 plus 版本了。

问答效果

服务器的主入口文件是什么?
query = "服务器的主入口文件是什么?"
index.query(query)' app.js'

这个问题比较简单,能直接在文中找到答案,回答是正确的。
routes/index.js有什么作用?
query = "routes/index.js有什么作用?"
index.query(query)' routes/index.js is used to define the routes for the application. It is responsible for mapping incoming requests to the appropriate controller functions.'
这个问题显然文档中并没有详细描述,只提到了路由定义文件,这回答大概率是 ChatGPT 做出的补充说明。
介绍一下这个项目?
query = "介绍一下这个项目?"
index.query(query)' 这个项目包含了一个服务器,一个README.md文件,一个app.js文件,以及double_room,multi_room和live_room三个文件夹,每个文件夹都包含一个index.js文件,以及一些其他的js文件,这些文件用于实现双人房间,多人房间和直播房间的功能,还有一个selfHost的URL,以及一个logic/double_room_mgr.js文件和一个http://localhost:5757/weapp/utils/logfilelist的URL。'
这个属于归纳性问题,显然 ChatGPT 通读了全文后总结的还算不错。
哪个文件处理云通讯相关?
query = "哪个文件处理云通讯相关?"
index.query(query)' double_room_mgr.js'

这个问题 chat老师“翻车”了,可能是提问里的“相关”,在中文的上下文环境中产生了歧义,把下一个模块的文件当做了答案。
如何服务器部署?
query = "如何服务器部署?"
index.query(query)' The server is configured with upstream app_weapp, a server block listening on port 80, and a server block listening on port 443. The server_name is set to the selfHost URL, and the ssl_certificate and ssl_certificate_key are set to the specified paths. The location block is configured to proxy requests to the upstream app_weapp. The files listed in the context are not related to server deployment.'
对于文档里没有的内容,ChatGPT 就开始放飞了,丫丫了一堆正确的废话。
总体效果还是很惊艳的,远远超出了我的想象,特别是归纳总结能力上。搜索定位功能来说,对于开发文档,我们码农可能习惯用关键字匹配搜索更高效,而在模糊搜索领域,其实才是 chat 老师真正的用武之地。
可以想象一些使用场景,通读个人小说,归纳出人物关系和故事线;文案的风格提取,并应用到自己的产品上;读各种金融研究报告,给出投资建议。。。
「未来需要一个会提问的人,一个足够庞大的基础语言模型,以及一份足够专业的指导文档,垂直领域专家就这么诞生了!」
展望和改进
本篇每次将文本构建成矢量数据将花费很长的时间(特别是采用 CPU 方式的话),若能将这部分工作用向量数据库来完成,速度将提升几个数量级。
鉴于现在 chatGPT 在国内服务的不友善,还是很期待类似百度的“文心一言”,阿里的“通义千问“,包括讯飞的大语言模型尽快成熟起来。后续更改 api 接口可切换不同的服务,未来算力问题若不是瓶颈,甚至于可以考虑自建语言模型来做本地化部署,这对知识图谱类应用会是一个有力的竞争者。
❝ps:吐槽一下联想的售后,本来题图想用stable diffusion来生成的,结果把我一台3090训练机“从CPU降频故障”修到“主板烧CPU”,也是没谁了...
用文心一言暂时顶一下,效果也还不错,国产大模型加油!
❞
源码下载

本期相关文件资料,可在公众号“深度觉醒”,后台回复:“chat01”,获取下载链接。文章来源:https://www.toymoban.com/news/detail-440065.html
 文章来源地址https://www.toymoban.com/news/detail-440065.html
文章来源地址https://www.toymoban.com/news/detail-440065.html
到了这里,关于用 ChatGPT 采用自有数据集训练问答机器人的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!