目录
一:项目概述
二:模块实现
2.1 Python爬虫的技术实现
2.1.1 爬取网页,获取数据
2.1.2 解析内容
2.1.3 保存数据
2.2 数据可视化
2.2.1 Flask框架
2.2.2 首页和电影页(表格)
2.2.3 使用Echarts呈现电影评分分布图
2.2.4 jieba分词,WordCloud生成“词云”
一:项目概述
本项目运用 Python爬取电影Top250网页数据,使用BeautifulSoup和正则表达式进行解析,存于excel和sqlite数据库中。数据可视化应用Flask 框架,使用Echarts呈现电影评分分布图,使用jieba进行文本分析,WordCloud生成电影“词云”。
二:模块实现
2.1 Python爬虫的技术实现
技术概览:
1.爬取网页,获取数据:使用urllib2库获取指定url的数据。
2.解析内容:使用BeautifulSoup定位特定的标签位置;使用正则表达式找到具体的内容。
3.保存数据:使用xlwt将抽取的数据写入Excel表格中;使用sqlite3将数据写入数据库。
2.1.1 爬取网页,获取数据
使用urllib2库获取指定url的数据。
import urllib.request
#得到指定一个URL的网页内容
def askURL(url)
head = { #模拟浏览器头部信息,向豆瓣服务器发送消息
"User-Agent": "xxxx"
} #用户代理:表示告诉电影网站服务器,我们是什么类型的机器、浏览器(本质上是告诉服务器,我们可以接收什么水平的文件内容)
req = urllib.request.Request(url=url, headers=head)
html = ""
try:
response = urllib.request.urlopen(req)
html = response.read().decode("utf-8")
print(html)
except urllib.error.URlError as e:
if hasattr(e,"code"): #hasattr(e,"code“): 判断e这个对象里面是否包含code这个属性
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html#爬取网页
def getData(baseurl):
datalist = []
for i in range(0,10): #调用获取页面信息的函数,10次
url = baseurl + str(i*25)
html = askURL(url) #保存获取到的网页源码
#2.逐一解析数据
return datalist2.1.2 解析内容
使用BeautifulSoup定位特定的标签位置;使用正则表达式找到具体的内容。
#创建正则表达式对象,表示规则(字符串的模式)
findLink = re.compile(r'<a href="(.*?)">') #只拿括号里的内容;括号里的?表示非贪婪模式,找到第一个>就停下
findImgSrc = re.compile(r'<img.*src="(.*?)"',re.S) #re.S表示使.匹配包括换行在内的所有字符
findTitle = re.compile(r'<span class="title">(.*)</span>')
findRating = re.compile(r'<span class="rating_num".*>(.*)</span>')
findJudgeNum = re.compile(r'<span>(\d*)人评价</span>')
findInq = re.compile(r'<span class="inq">(.*)</span>')
findBd = re.compile(r'<p class="">(.*?)</p>',re.S)#2.逐一解析数据
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_ ="item"): #查找符合要求的字符串,形成列表;class_加下划线表示属性
#print(item) #测试:查看电影item全部信息
data = [] #保存一部电影的所有信息
item = str(item) #转变类型为字符串,未后面的正则匹配做准备
#影片详情的链接
link = re.findall(findLink,item)[0] #re库用来通过正则表达式查找指定的字符串
data.append(link)
#影片图片
imgSrc = re.findall(findImgSrc,item)[0]
data.append(imgSrc)
#影片片名
titles = re.findall(findTitle,item) #片名可能只有一个中文名,也可能还有外文名,甚至多个外文名
if len(titles)>=2: #若有多个外文名也只取一个
ctitle = titles[0] #添加中文名
data.append(ctitle)
otitle = titles[1].replace("/","").strip() #添加英文名,并去掉/和前后空格
data.append(otitle)
else:
data.append(titles[0])
data.append("") #外国名字要留空,否则数据会错位
#影片评分
rating = re.findall(findRating,item)[0]
data.append(rating)
#评分人数
judgeNum = re.findall(findJudgeNum,item)[0]
data.append(judgeNum)
# 影片概述
inq = re.findall(findInq, item) #有的影片没有概述,因此这里用了[0]会报错
if len(inq) != 0:
inq = inq[0].replace("。", "")
data.append(inq)
else:
data.append("")
#影片的相关内容
bd = re.findall(findBd, item)[0]
bd = re.sub('<br(\s+)?/>(\s+)'," ",bd) #去掉(\s+),\s匹配空白和tab键
bd = re.sub('/'," ",bd) #替换/
bd = bd.strip() #去掉前后的空格
data.append(bd)
datalist.append(data) #把处理好的一部电影信息放入datalist2.1.3 保存数据
1.Excel表储存
利用python库xlwt将抽取的数据datalist写入表格中
import xlwt
# 保存数据(excel存储)
def saveData(datalist,savepath):
book = xlwt.Workbook(encoding="etf-8",style_compression=0) # encoding:设置编码,可写中文;style_compression:是否压缩,不常用
sheet = book.add_sheet('电影Top250',cell_overwrite_ok=True) # cell_overwrite_ok:是否可以覆盖单元格,默认为False
col = ("影片详情链接","影片图片","影片中文名","影片外文名","影片评分","评分人数","影片概述","影片相关内容") #设置表头
for i in range(0,len(col)):
sheet.write(0,i,col[i]) #存入列名
for i in range(0,250):
data = datalist[i] #拿出每一条电影的信息
for j in range(0,len(col)):
sheet.write(i+1,j,data[j]) #第0行是表头,故须i+1
book.save(savepath) #保存数据表
2.SQLite储存
使用sqlite3。步骤包括:连接数据库,创建数据表,插入数据。
import sqlite3 #进行SQLite数据库操作
#保存数据(db存储)
def saveData2(datalist,savedb):
conn = sqlite3.connect(savedb)
cur = conn.cursor()
#建表
sql1 = '''
create table movie250
(id integer PRIMARY KEY autoincrement,
link text,
imgSrc text,
ctitle text,
otitle text,
rating real,
judgeNum int,
inq text,
bd text);
'''
cur.execute(sql1)
#插入数据
for i,data in enumerate(datalist):
sql2 = '''
insert into movie250(id,link,imgSrc,ctitle,otitle,rating,judgeNum,inq,bd)
'''
value_str = 'values(' + str(i+1) + ','
for j in range(0,len(data)):
if j == 4 or j == 5 :
value_str = value_str + str(data[j]) + ','
elif j != len(data) - 1:
value_str = value_str + '"' + data[j] + '",'
else:
value_str = value_str + '"' + data[j] + '"'
sql2 += value_str + ');'
cur.execute(sql2)
conn.commit()
conn.close()2.2 数据可视化
2.2.1 Flask框架
本项目使用Flask作为Web框架。Flask框架的核心是Werkzeug和Jinja2。Werkzeug进行请求的路由转发;Jinja2进行界面的渲染。
新建基于Flask框架的工程文件:

自动生成两个文件夹:
1.static放一些css、js文件,网页相关素材的提供
2.templates模板:放一些html网页文件,反馈给用户想要访问的内容
运行一下得到一个网页

run()监听用户访问这个网页

这两部分就是我们可以自定义的内容了。Werkzeug负责判断特定路径执行哪一个函数(红框部分);Jinja2负责返回的内容(黄框部分)

2.2.2 首页和电影页(表格)
首页和电影列表页代码:
@app.route('/index') # 首页
def home():
return index()
@app.route('/movie') # 列表页
def movie():
datalist = []
conn = sqlite3.connect("movie250.db")
cur = conn.cursor()
sql = "select * from movie250"
data = cur.execute(sql)
for item in data:
datalist.append(item)
cur.close()
conn.close()
return render_template("movie.html",movies = datalist)电影页html表格部分代码:
<table class="table table-striped">
<tr>
<td>排名</td>
<td>中文名称</td>
<td>外文名称</td>
<td>评分</td>
<td>评分人数</td>
<td>一句话概述</td>
<td>其他信息</td>
</tr>
{% for movie in movies %}
<tr>
<td>{{ movie[0] }}</td>
<td>
<a href="{{ movie[1] }}" target="_blank">
{{ movie[3] }}
</a>
</td>
<td>{{ movie[4] }}</td>
<td>{{ movie[5] }}</td>
<td>{{ movie[6] }}</td>
<td>{{ movie[7] }}</td>
<td>{{ movie[8] }}</td>
</tr>
{% endfor %}
</table> 效果图:
首页

电影页

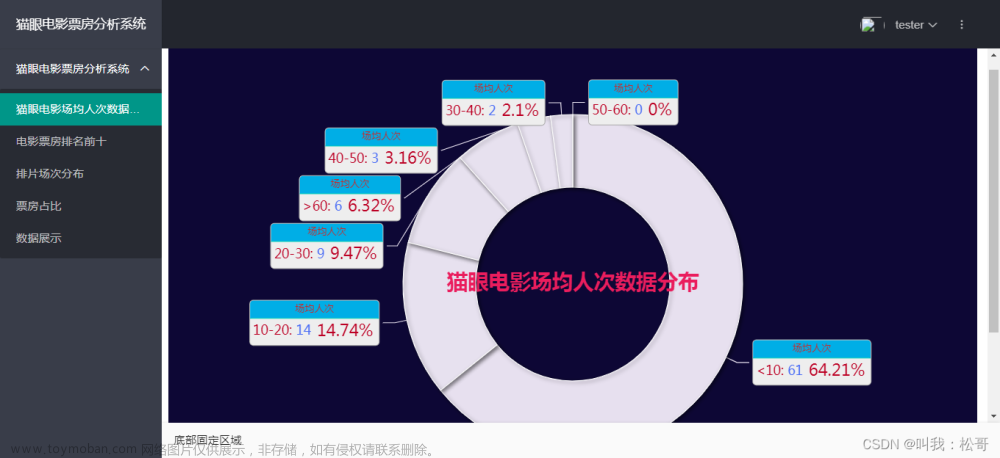
2.2.3 使用Echarts呈现电影评分分布图
ECharts是一款基于JavaScript的数据可视化图表库,提供直观,生动,可交互,可个性化定制的数据可视化图表。本项目应用使用Echarts呈现电影Top250的评分分布图。
score列表页代码
@app.route('/score')
def score():
score = [] #评分
num = [] #每个评分所统计出的电影数量
conn = sqlite3.connect("movie250.db")
cur = conn.cursor()
sql = "select rating,count(rating) from movie250 group by rating"
data = cur.execute(sql)
for item in data:
score.append(item[0])
num.append(item[1])
cur.close()
conn.close()
return render_template("score.html", score=score,num=num)html文件的Echarts部分
<!-- 为 ECharts 准备一个定义了宽高的 DOM -->
<div id="main" style="width: 100;height:350px;"></div>
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main'));
// 指定图表的配置项和数据
option = {
tooltip: {
trigger: 'axis',
axisPointer: {
type: 'shadow'
}
},
color:['#3398DB'],
grid: {
left: 100,
right: 50,
top: 10
},
xAxis: {
type: 'category',
data: {{ score }}
<!--['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun']-->
},
yAxis: {
type: 'value'
},
series: [{
data: {{ num }},
<!--[120, 200, 150, 80, 70, 110, 130],-->
type: 'bar',
barWidth:'50'
}]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
</script>效果图

2.2.4 jieba分词,WordCloud生成“词云”
需要安装jieba分词包(把一个句子分成很多个词),以及绘图工具matplotlib包,还有Wordcloud下载。
import sqlite3 #数据库
import jieba #分词
from matplotlib import pyplot as plt #绘图,数据可视化
from wordcloud import WordCloud #词云
from PIL import Image #图片处理
import numpy as np #矩阵运算
#准备词云所需的文字(词)
conn = sqlite3.connect('movie250.db')
cur = conn.cursor()
sql = 'select inq from movie250'
data = cur.execute(sql)
text = ""
for item in data:
text = text + item[0]
#print(text)
cur.close()
conn.close()
#分词
cut = jieba.cut(text)
str = " ".join(cut)
print(len(str))
#生成遮罩图片
img = Image.open(r'.\static\assets\img\tree.jpg') #打开遮罩图片
img_array = np.array(img) #将图片转换为数组
wc = WordCloud( #封装WordCloud对象
background_color='white',
mask=img_array,
font_path="SourceHanSansCN-Bold.otf", #字体所在位置:C:\Windows\Fonts
min_word_length=2 , #一个单词必须包含的最小字符数
stopwords=["就是","一个","不是","这样","一部","我们","没有","电影","不会","不能","每个"] #屏蔽词
)
wc.generate_from_text(str) #根据str文本生成wc词云
#绘制图片
fig = plt.figure(1) #绘制图片
plt.imshow(wc) #按照词云wc的规则显示图片
plt.axis('off') #是否显示坐标轴
#plt.show() #显示生成的词云图片
#输出词云图片到文件
plt.savefig(r'.\static\assets\img\word.jpg',dpi=1000)
裁剪优化:
裁剪前

裁剪后,视觉效果更好文章来源:https://www.toymoban.com/news/detail-440211.html
#裁剪图片
base_img = Image.open(r'.\static\assets\img\word.jpg')
w,h = base_img.size #获取图片尺寸的宽和高
box = (0.1*w,0.1*h,0.9*w,0.9*h) #四个参数值分别是x,y,w,h; x,y是图像左上点的坐标,w,h是图像的宽和高
base_img.crop(box).save(r'.\static\assets\img\word2.jpg')
#base_img.crop(box).show() 文章来源地址https://www.toymoban.com/news/detail-440211.html
文章来源地址https://www.toymoban.com/news/detail-440211.html
到了这里,关于电影Top250数据分析可视化,应用Python爬虫,Flask框架,Echarts,WordCloud的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!