本文仅讨论节省图片加载时间问题,这里面可能有一些容易忽视的细节。yolov5的训练参数里面有一个--cache,默认是ram,就是把解码后的图片保存在内存中。也可以是disk,就会把解码后的图片保存在硬盘上。
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
解码后的图片就是numpy数组啦,保存为.npy文件

这里可能有一个问题,保存在硬盘上有啥用?能加速吗?
接下来就稍微展开讨论一下。
一。现象
在训练的时候,有可能会发现显卡使用率不高,甚至有的时候显卡使率用老是为0(用nvidia-smi查看),然后刷地一下升高了,然后又较长时间为0,这时候可能会觉得奇怪,它到底在干啥呢?这个时候如果查看cpu使用率,往往发现cpu占用率一直很高,有几个逻辑cpu始终满负责(用top命令查看)
二。分析
训练的时候无非是几个步骤:
1.加载图片
2.图片预处理,数据增强,比如缩放,旋转,错切等等,还有yolov5常用的mosaic、mixup
3.正向反向,更新梯度等等要用显卡的地方
而1、2两步里面的加载图片其实是一个容易忽略的耗时步骤,加载图片的耗时即磁盘IO耗时和解码图片耗时,这两个耗时都跟图片大小有关系,图片越大,耗时就越长。而磁盘IO又跟你的磁盘性能有关系,磁盘性能相差可能天差地别,比如pcie4.0的SSD和机械硬盘就可能是10倍以上的速度差别,而解码图片这个只跟CPU有关系了,差别不会太大。
所以这里先回前面的问题保存在硬盘上有啥用?能加速吗?-----能,就算解码后图片文件比原图片文件更大,都能加速,只要你用的是高性能的SSD就行,因为它把CPU解码时间完全给省掉了。
另外,其实yolov5每训练一张图片,它不是只读了一张图,它起码会读4张图,因为mosaic数据增强是默认开启的,概率为1,它会把4张图拼成一张(随机中心点),这个暂不详述。然后如果开启了mixup,mixup又会再读4张图,跟之前的4张图做混合,那就是一次读8张图了。(当然如果mixup开的概率不大的话,那就不是每次都读8级图)。总之就是一次最多能读到8张图,那么读图时间成本就翻了8倍了。虽然你可能会说我CPU多核的,我SSD很快,但是你本来开一个较大的batch-size的时候,就已经充分用到了多核性能,现在再乘个8,就不够用啦。
这里要提一下mmdetection里的yolox,它默认是会用到mosaic加mixup的,并且没有概率设置,每次都读8张图,所以给人的感觉就是,这玩意儿训练怎么这么慢?我的显卡为什么一直是0,它在干啥?
注:原生的yolox是可以用缓存的,但mmdetection好像不行,如果你知道怎么用,请告诉我
三。先上结论
1.如果训练图片总量不大,或者服务器内存超高,即完全可以把解码后的图片放内存里,那就充分利用,直接加上--cache参数完事
2.如果读图片的时间不长,它的耗时只占总时间的很少一部分,没什么优化意义那就不用管它。比如:
(1)训练图片都很小,比如大多在200K以下
(2)模型比较大,导致显卡耗时占了大部分,比如用yolov5x的规模训练
(3)只开mosaic,没开mixup,甚至mosaic的概率还调小了
3.如果想节省读图时间,但是内存又装不下。但是你有一个高性能的SSD,那你就可以考虑把解码后的图片缓存在硬盘上。即用--cache disk参数
4.如果想节省读图时间,但是内存装不下,又没有SSD,那怎么办呢?凉拌!买一个SSD不就行了,买不起显卡,还买不起SSD吗,管够!不过还有一点
如果你的训练图片都很大,比如分辨率高,或者压缩率低,你都可以根据训练用到的分辨率直接把原图resize一下,保存为jpg格式,直接保存到npy文件中(具体见续篇),比如你训练的分辨率用的是640(yolov5默认就是640),那你就把图片resize到640(保持宽高比例)就行了,这样你的图片就变小了,那读图时间自然就少了。并且有可能变小之后你的内存装的下了,那速度就起飞了!
此处修正:
1.保存为640jpg是有可能影响训练效果的,可以保存为640分辨率的npy
2.关于读图时间、显卡耗时与总时间的关系,其实不是简单地相加,两者是木桶效应。
具体可以见续篇:
yolov5训练加速--一个可能忽视的细节(mmdetection也一样),为什么显卡使用率老是为0?(续)_kv1830的博客-CSDN博客文章来源地址https://www.toymoban.com/news/detail-440350.html
四。实验
我其实是用mmdetection的yolox在训练cityscape数据集的时候,发现了这么个问题,cityscape的图片都是2M左右,分辨率是2048乘1024的,然后你再用一个小规模的模型来训练,比如yolox_s,那就会发现训练时间明显长于yolov5s(那是因为yolox开了mixup),而且貌似还没有把图片加内存里的功能。
但是我家里的电脑上没有准备好cityscape的标注文件,我就不用它演示了。我正好有一个之前做一个实验用的超小数据集,训练集一共只有45张图,验证集只有5张图,但是里面的图片都蛮大的,都是2M多,正好用它来试试。之前的实验在如下文章中:
https://blog.csdn.net/ogebgvictor/article/details/128179019

我的显卡是笔记本上的3080,为了增强对比效果,先把mixup打开,概率设为1(复制了一份超参数文件data/hyps/hyp.scratch-low-my.yaml)
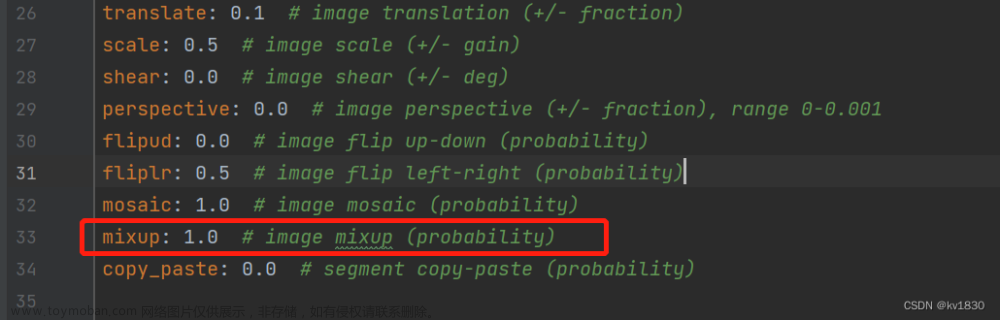
注意,我笔记本上只有一个PCIE4.0的SSD,所以我的耗时主要不在磁盘IO上,而是在图片解码上
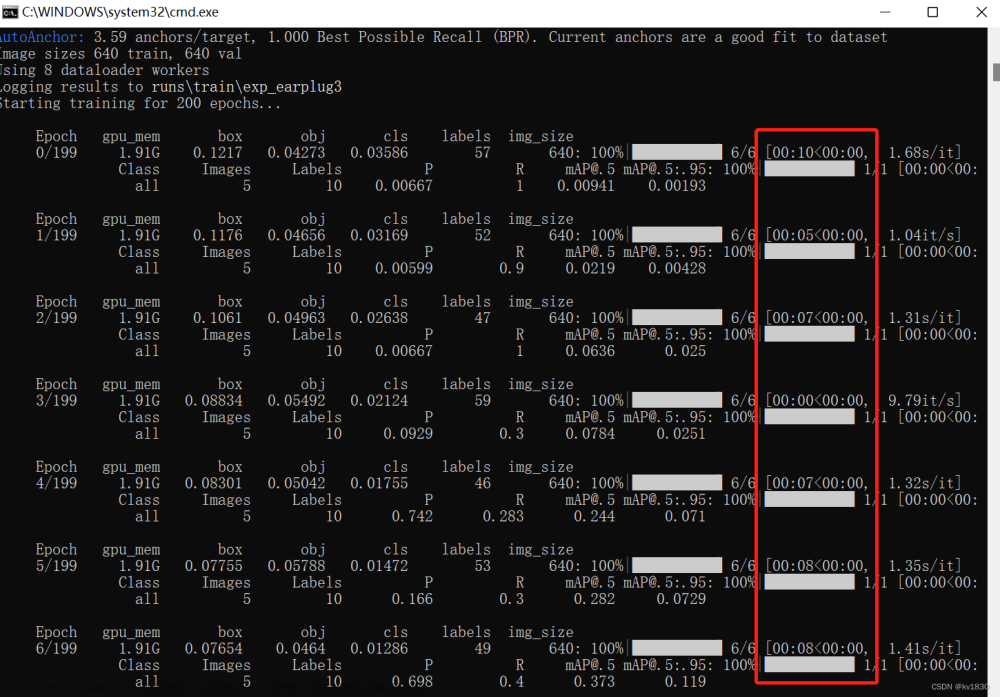
1.啥也不缓存
python train.py --data earplug_data/dataset.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --batch-size 8 --epochs 200 --name exp_earplug --hyp data/hyps/hyp.scratch-low-my.yaml
耗时如下,45张图按理来说岂不是飞地一下就没了,这边却耗时在7、8秒左右一轮,而且明显会感觉进度条卡顿(时快,时卡那种,那个0秒的可能不太准)
2.直接装内存里
python train.py --data earplug_data/dataset.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --batch-size 8 --epochs 200 --name exp_earplug --hyp data/hyps/hyp.scratch-low-my.yaml --cache
速度起飞没的说,非常流畅
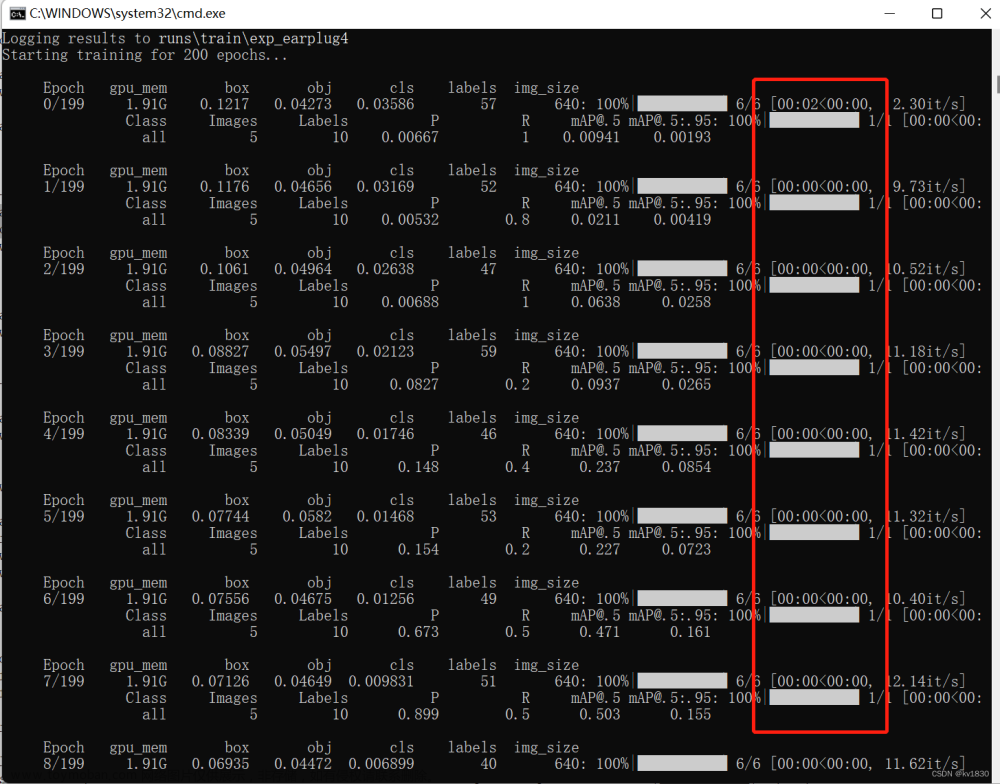
3.缓存到硬盘里
python train.py --data earplug_data/dataset.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --batch-size 8 --epochs 200 --name exp_earplug --hyp data/hyps/hyp.scratch-low-my.yaml --cache disk
速度也是很快,但是稍有卡顿,没有内存那么流畅,而且这边的0秒是个整数,我感觉它其实并不是0秒,可能0.5也算0秒了,跟2那个0秒是有差距的。
这里也证 明了之前关于保存在硬盘上有啥用?能加速吗?的回答,是正确的
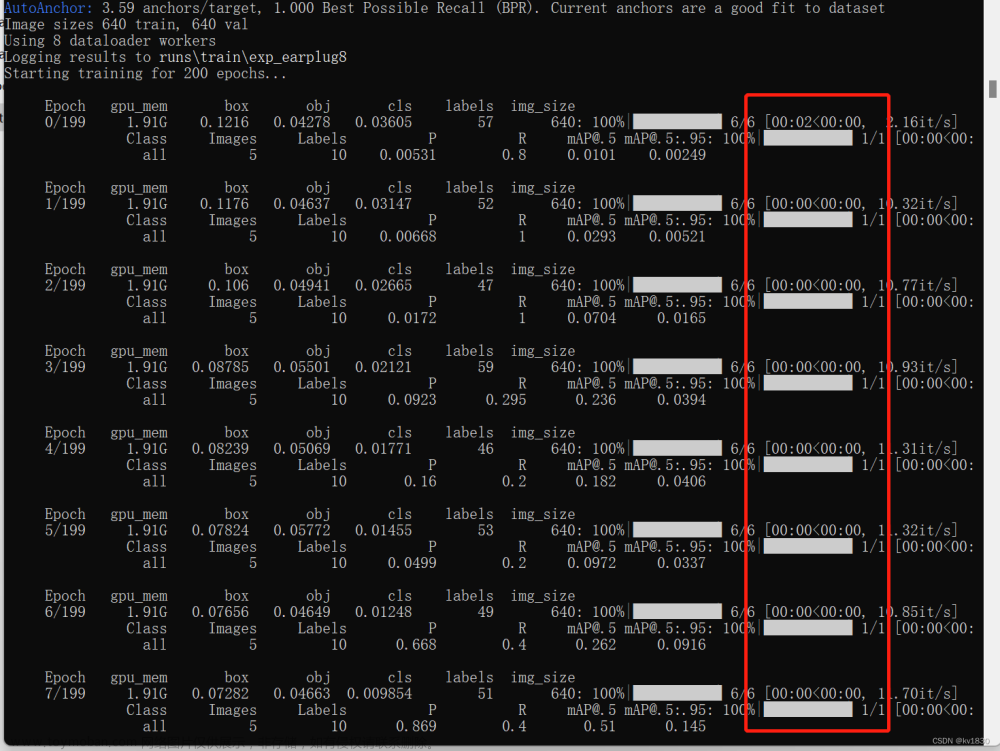
我PCIE4.0的SSD,读几个图片咋就会稍有卡顿?仔细看一下训练图片发现,图片2M多,解码后36M!

其实解码图片的大小是固定的,就是宽*高*3,单位字节,看一下我这个图片的分辨率
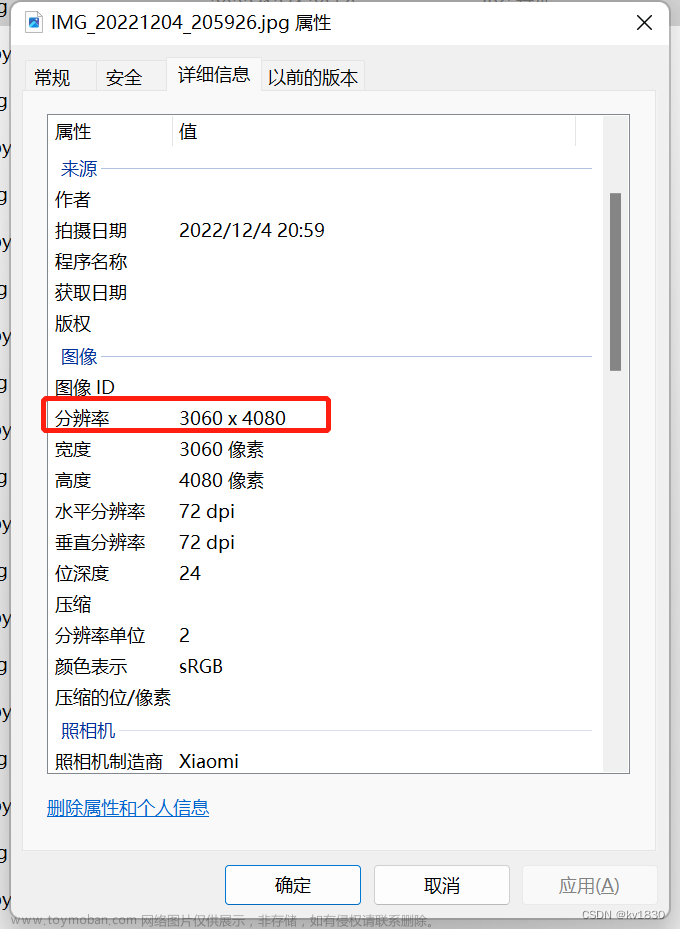
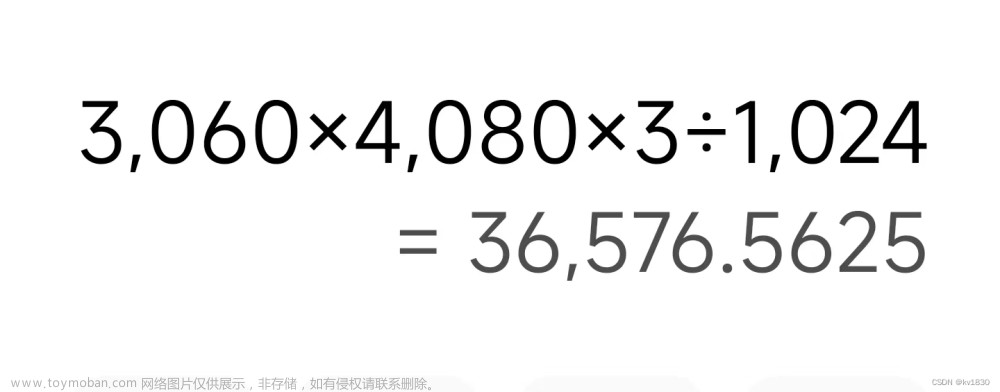
是36M吧,上面已经说到了解决办法,直接resize成640分辨率
4.resize后再用缓存
就像下面这样把图片都resize一下
import cv2 as cv
from pathlib import Path
def batch_resize(img_dir, dest_img_dir, size=640):
img_dir = Path(img_dir)
dest_img_dir = Path(dest_img_dir)
dest_img_dir.mkdir(parents=True, exist_ok=True)
for img_path in img_dir.glob('*.jpg'):
img = cv.imread(str(img_path))
h, w = img.shape[:2]
ratio = size / max(h, w)
img = cv.resize(img, None, fx=ratio, fy=ratio, interpolation=cv.INTER_LINEAR)
cv.imwrite(str(dest_img_dir/img_path.name), img)
batch_resize(r'D:\workPython\yolov5-6.2\data\earplug_data\images\train',
r'D:\workPython\yolov5-6.2\data\earplug_data\images_mini\train')
batch_resize(r'D:\workPython\yolov5-6.2\data\earplug_data\images\val',
r'D:\workPython\yolov5-6.2\data\earplug_data\images_mini\val')不过要注意的是,训练的时候你不能把图片目录指定为images_mini,你还是用得images,因为在yolov5代码里写死了,它由图片目录去找labels目录的时候只会把图片目录当成images来用。所以你自己改一下目录名,我就不帮你改了
改完了之后先啥都不缓存,直接试一下,命令同1.
python train.py --data earplug_data/dataset.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --batch-size 8 --epochs 200 --name exp_earplug --hyp data/hyps/hyp.scratch-low-my.yaml
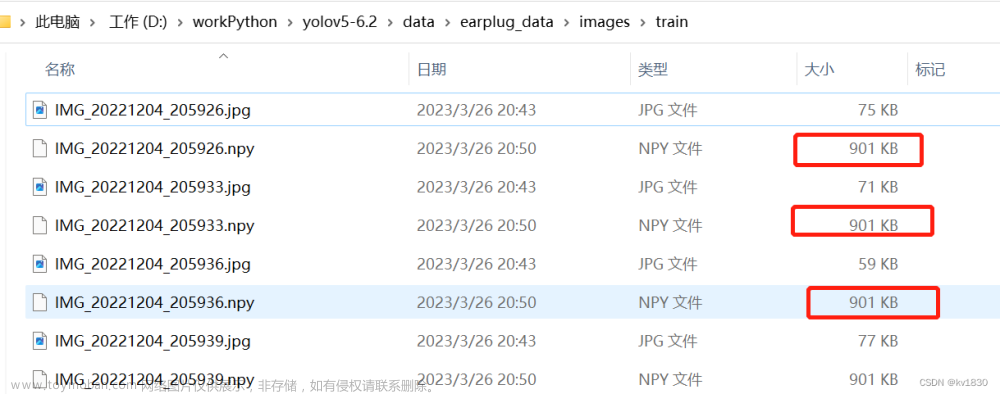
发现速度居然跟 3.缓存到硬盘里比较相近!此处就不贴图了,耗时显示的都是0。其实相对于3,我这是节省了磁盘IO时间,因为我的图片resize之后都在100K以下,增加了一点点解码时间。
如果resize之后再用缓存,那速度更是快的飞起,跟2.直接装内存里差不多了。缓存文件只有900K。
五。mmdetetion怎么办?
mmdetection好像不支持缓存(如果能的话请告诉我怎么用,我暂时没发现),所以办法即:
1.你给它加个缓存功能,可以参考yolov5,原生yolox的代码来看看怎么改,我暂时还没仔细研究
2.缓存到内存稍微麻烦一点,因为它涉及多进程的问题,但缓存到硬盘上那不是很简单吗,如果你不想涉及到多进程的问题,你直接找到它读图片的代码,好像在一个loading.py里面,把里面的逻辑改一下即可,改为如果存在npy,则加载它。然后呢你事先给先把图片缓存到硬盘上,然后再启动训练流程,就完全不会有多进程的问题啦。
3.如果你真的没有SSD,比如我用的服务器上就没有,那你可以先考虑把图片resize到训练分辨率,还是会节省一些时间的。文章来源:https://www.toymoban.com/news/detail-440350.html
下一篇:
yolov5训练加速--一个可能忽视的细节(mmdetection也一样),为什么显卡使用率老是为0?(续)_kv1830的博客-CSDN博客
到了这里,关于yolov5训练加速--一个可能忽视的细节(mmdetection也一样),为什么显卡使用率老是为0?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!