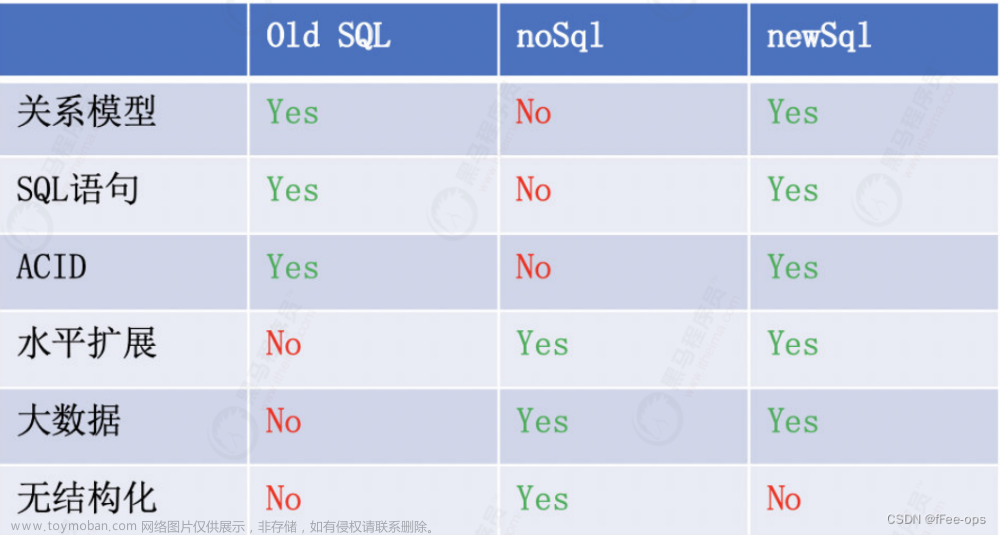
简介
使用TiDB Lightning 导入数据。
原理
TiKV进入导入模式

它是使用物理导入的模式,将SQL文件直接导入到TiKV中,它是一种初始化的导入,也就是说目标的数据库和表都是不能够存在的(注意事项,在这种方式导入的时候TiKV要切换到导入模式才行) 。
初始化表元数据信息

将导入的文件分成区块
切分的区块转存到本地

导入数据到TiKV集群

先导入数据,然后在导入索性。
对于导入的数据进行校验

切回到普通模式正常提供服务

导入模式的比较

Logical Import Mode 就是执行SQL的方式。
适用场景
导入限制

- 如果有TiFlash的时候,会影响导入的速度。
- 如果表里面的字符集是GBK的话,那么TiDB v5.4之前是不支持的。
- 如果源文件是Apache Parquet文件,不支持导入。
硬件需求
因为它会跑满机器的性能。
region-concurency 这个配置能够限制TiDB Lighning导入数据时候使用的CPU核数
前置检查
 版本v4.0之后才支持上面的这种导入方式。
版本v4.0之后才支持上面的这种导入方式。
目标库需要的权限

并行导入(v5.3以后)
MySQL分库分表收敛场景

本身数据很大

注意事项

TiDB Lightning的使用
安装

下载
TiDB 社区版 | PingCAP

安装
#解压下载好的安装包
tar -zxvf tidb-community-toolkit-v6.5.0-linux-amd64.tar.gz
#进入到文件夹以后解压出dumpling
cd tidb-community-toolkit-v6.5.0-linux-amd64
tar -zxvf tidb-lightning-v6.5.0-linux-amd64.tar.gz
vi /etc/profile.d/my.sh
#TOOLKIT_HOME
export TOOLKIT_HOME=/root/tidb-community-toolkit-v6.5.0-linux-amd64
export PATH=$PATH:$TOOLKIT_HOME
source /etc/profile.d/my.sh打印
[root@master tidb-community-toolkit-v6.5.0-linux-amd64]# tidb-lightning
Verbose debug logs will be written to /tmp/lightning.log.2023-04-16T15.24.04+0800
tidb lightning encountered error: [Lightning:Config:ErrInvalidConfig]tikv-importer.backend must not be empty!
使用
前期准备
TiDB实战篇-数据导出工具Dumping_顶尖高手养成计划的博客-CSDN博客
#先有对应的SQL文件,这里是TiDB Dumpling导出来的数据(这里我备份了是test库的数据)
cd /tmp/test/sql
[root@master sql]# ll
total 16
-rw-r--r-- 1 root root 146 Apr 16 12:06 metadata
-rw-r--r-- 1 root root 59 Apr 16 12:06 test.emp.0000000010000.sql
-rw-r--r-- 1 root root 139 Apr 16 12:06 test.emp-schema.sql
-rw-r--r-- 1 root root 95 Apr 16 12:06 test-schema-create.sql
#连接到数据库把test库给删除了
mysql -h127.0.0.1 -P4000 -uroot -ptidb
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| INFORMATION_SCHEMA |
| METRICS_SCHEMA |
| PERFORMANCE_SCHEMA |
| mysql |
| test |
+--------------------+
5 rows in set (0.00 sec)
mysql> drop database test;
Query OK, 0 rows affected (0.34 sec)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| INFORMATION_SCHEMA |
| METRICS_SCHEMA |
| PERFORMANCE_SCHEMA |
| mysql |
+--------------------+
4 rows in set (0.00 sec)
准备执行的配置文件
vi tidb-lightning.toml
[lightning]
# 数据的并发数。默认与逻辑 CPU 的数量相同。
# 混合部署的情况下可以将其大小配置为逻辑 CPU 数的 75%,以限制 CPU 的使用。
# region-concurrency = 1
# 日志
level = "info"
file = "tidb-lightning.log"
[tikv-importer]
# 是否允许启动多个 TiDB Lightning 实例(**physical import mode**)并行导入数据到一个或多个目标表。默认取值为 false。注意,这个参数**不是用于增量导入数据**,仅限目标表为空的场景使用。
# 多个 TiDB Lightning 实例(physical import mode)同时导入一张表时,此开关必须设置为 true。但前提是目标表不能存在数据,即所有的数据都只能是由 TiDB Lightning 导入。
incremental-import = true
#backend 设置成 pysical import 模式
backend = "local"
# 设置本地临时存储路径。
sorted-kv-dir = "/tmp/sorted-kv-dir"
[mydumper]
# 本地源数据目录或外部存储 URL,这里也就是Dumpling导出数据的目录文件
data-source-dir = "/tmp/test/sql"
# 只导入与该通配符规则相匹配的表。详情见相应章节。
filter = ['*.*', '!mysql.*', '!sys.*', '!INFORMATION_SCHEMA.*', '!PERFORMANCE_SCHEMA.*', '!METRICS_SCHEMA.*', '!INSPECTION_SCHEMA.*']
[tidb]
# 目标集群的信息。tidb-server 的地址,填一个即可。
host = "192.168.66.10"
port = 4000
user = "root"
# 设置连接 TiDB 的密码,可为明文或 Base64 编码。
password = "tidb"
# 表结构信息从 TiDB 的“status-port”获取。
status-port = 10080
# pd-server 的地址,填一个即可。
pd-addr = "192.168.66.10:2379"执行
nohup tidb-lightning -config tidb-lightning.toml > nohup.out &
mysql -h127.0.0.1 -P4000 -uroot -ptidb
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| INFORMATION_SCHEMA |
| METRICS_SCHEMA |
| PERFORMANCE_SCHEMA |
| mysql |
| test |
+--------------------+
5 rows in set (0.00 sec)
mysql> use test;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from emp;
+------+
| id |
+------+
| 1 |
+------+
1 row in set (0.00 sec)数据过滤导入

断点续传
 文章来源:https://www.toymoban.com/news/detail-440376.html
文章来源:https://www.toymoban.com/news/detail-440376.html
文章来源地址https://www.toymoban.com/news/detail-440376.html
到了这里,关于TiDB实战篇-TiDB Lightning 导入数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!