kafka消息队列有两种消费模式,分别是点对点模式和订阅/发布模式。具体比较可以参考Kafka基础–消息队列与消费模式。
下图是一个点对点的Kafka结构示意图,其中有以下几个部分:
- producer:消息生产者
- consumer:消息消费者
- Topic:消息主题
- partition:主题内分区
- Brokers:消息服务器
- Groups:消费者组
下面聊一聊为什么Kafka需要有这些组成部分,不就是生产者生产消息,消费者消费消息吗?有必要这么复杂吗?
一、为什么需要有Topic?
Topic是一个消息的逻辑分类。Kafka为什么需要Topic,就是Kafka为什么需要对消息进行逻辑上的分类。
在一个小型电商项目中,如果订单模块和商品模块都需要使用消息队列。两个模块中的消息一个是订单信息,一个是商品的描述消息。两种消息肯定不是同一类的消息,它们消息内容不一样、结构不一样、并且分别有自己的生产者群体和消费者群体。
Kafka消息系统是一个庞大的系统,不可能针对两个模块都各自搭建一套kafka消息系统。那么如何在一套消息系统中为多个模块提供服务。那就要对不同类型的消息进行逻辑分类,具体分类的方式就是用Topic进行区分,不同类别的消息具有不同的Topic。
既然Kafka通过Topic唯一标示每类消息,那么,
- 每条消息属于且仅属于一个Topic
- Producer发布数据时,必须指定将该消息发布到哪个Topic
- Consumer消费消息时,也必须指定消费哪个Topic的信息
二、为什么有partition?
(一) partition的作用
既然Topic已经对消息进行了分类,为什么每个Topic内部还需要按照Partition进行再次区分。
topic是逻辑的概念,partition是物理的概念。 啥是物理概念,就是物理上进行分离,分布在不同的实体机器上。
知乎上有一段很形象的描述:Kafka的设计也是源自生活,好比是为公路运输,不同的起始点和目的地需要修不同高速公路(主题topic)。高速公路上可以提供多条车道(分区partition),流量大的公路多修几条车道保证畅通,流量小的公路少修几条车道避免浪费。收费站好比消费者,车多的时候多开几个一起收费避免堵在路上,车少的时候开几个让汽车并道就好了。
如果没有分区,一个topic对应的消息集在分布式集群服务组中,就会分布不均匀,即可能导致某台服务器A记录当前topic的消息集很多,若此topic的消息压力很大的情况下,服务器A就可能导致压力很大,吞吐也容易导致瓶颈。有了分区后,假设一个topic可能分为10个分区,kafka内部会根据一定的算法把10分区尽可能均匀分布到不同的服务器上,比如:A服务器负责topic的分区1,B服务器负责topic的分区2,在此情况下,Producer发消息时若没指定发送到哪个分区的时候,kafka就会根据一定算法上个消息可能分区1,下个消息可能在分区2。
所以,partition的目的是:通过多分区实现负载均衡的效果,提高kafka访问吞吐率。
扩展阅读:
[1] 通过植物大战僵尸解释为什么Topic内需要partition:https://zhuanlan.zhihu.com/p/125159716
[2] 消费者与Partition的关系:https://www.pianshen.com/article/41571683192/
(二)partition怎么用?
在没有partition的时候,生产者产生特定Topic的消息,消费者消费特定topic的消息。现在每个Topic内又划分了Partition,原来的模式会如何变化呢,具体partition怎么用呢?参考图解进一步理解。
Kafka 中 Topic 被分成多个 Partition 分区。
Topic 是一个逻辑概念,Partition 是最小的存储单元,掌握着一个 Topic 的部分数据。每个 Partition 都是一个单独的 log 文件,每条记录都以追加的形式写入。
1、数据写入
一个 Topic 有多个 Partition,那么,向一个 Topic 中发送消息的时候,具体是写入哪个 Partition 呢?有3种写入方式:
- kafka默认轮询规则
- producer指定partition key写入特定的partition
- producer自定义规则
2、数据消费
点对点的消费模式中,Consumer 必须自己从 Topic 的 Partition 拉取消息。一个 Consumer 连接到一个 Broker 的 Partition,从中依次读取消息。
2.1 一个消费群组
2.1.1 partition数目 > 消费者数目
只有一个消费者时,消费者1将收到4个分区的全部消息。当有两个消费者时,每个消费者将分别从两个分区接受消息。
2.1.2 partition数目 = 消费者数目
当有四个消费者时,每个消费者都可以接受一个分区的消息。
2.1.3 partition数目 < 消费者数目
当有五个消费者时,会有闲置的消费者。
2.2 两个或多个消费者组
消费者群组之间是互不影响的,每个消费者群组内部仍然按照2.1中的策略进行消息消费。
在实际的业务中,特别是涉及到指定任务是否结束,任务对应消息是否消费完毕时,单纯指定topic消费,由kafka自动分配partition已经无法满足我们的实际需求了,这时我们还需要指定partition进行生产与消费。
(三)为什么消费者需要Groups?

consumer group是kafka提供的可扩展且具有容错性的消费者机制。
既然是一个组,那么组内必然可以有多个消费者或消费者实例(consumer instance),它们共享一个公共的ID,即group ID。组内的所有消费者协调在一起来消费对应主题(subscribed topics)的所有分区(partition)。
同一个topic的partition只能由同一个消费组内的一个consumer来消费,group内部是“共享订阅、提高性能”。
当然,该分区partition还可以被分配给其他group,各group间是“各自消费,互不影响”。
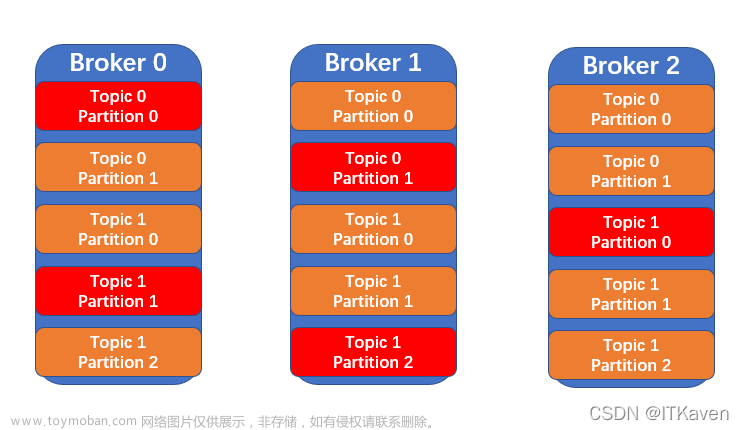
(四)为什么有Brokers?
缓存代理,Kafka集群中的一台或多台服务器统称broker。
一个broker是由ZooKeeper管理的单个Kafka节点。一组brokers组成了Kafka集群。 文章来源:https://www.toymoban.com/news/detail-440391.html
文章来源:https://www.toymoban.com/news/detail-440391.html
在Kaka中创建的主题基于分区,复制和其他因素分布在broker中。当broker节点基于ZooKeeper中存储的状态失败时,它会自动重新平衡群集,如果领导分区丢失,则其中一个跟随者请求被选为领导者。文章来源地址https://www.toymoban.com/news/detail-440391.html
到了这里,关于kafka中Topic、Partition、Groups、Brokers概念辨析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!