topsis模型原理:
1.topsis模型介绍
TOPSIS法(Technique for Order Preference by Similarity to Ideal Solution)
可翻译为逼近理想解排序法,国内常简称为优劣解距离法
TOPSIS 法是一种常用的综合评价方法,其能充分利用原始数据的信息,
其结果能精确地反映各评价方案之间的差距。
2.适用范围
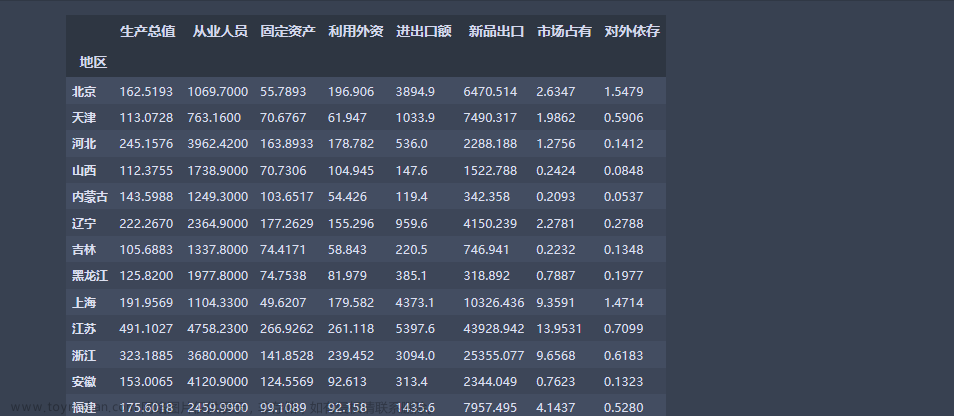
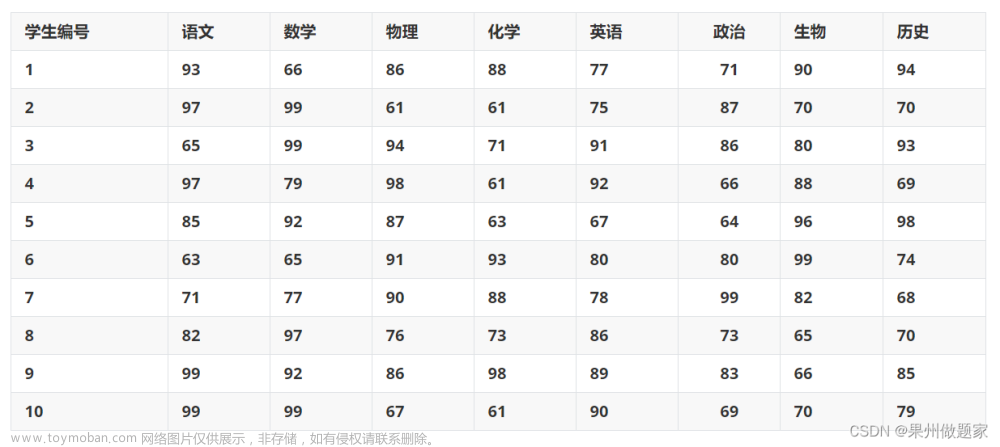
评价对象得分,且各个指标值已知。
3.模型基本步骤
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Vw1Znhvu-1655460949768)(https://pic4.zhimg.com/80/v2-bbaadad2aa8e41cb5691f339cc435af3_1440w.jpg “步骤图解”)]
- 将原始数据矩阵正向化。也就是将那些极小型指标,中间型指标,区间型指标对应的数据全部化成极大型指标,方便统一计算和处理。
- 将正向化后的矩阵标准化。也就是通过标准化消除量纲的影响。
- 计算每个方案各自与最优解和最劣解的距离
- 根据最优解与最劣解计算得分并排序
4.模型计算公式
-
指标正向化公式
对于极小型指标:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rNzjuStX-1655460949771)(https://www.zhihu.com/equation?tex=%5Cbegin%7Bsplit%7D+%26+%5Cquad%26x%27%3DM-x+%5Cend%7Bsplit%7D “”)]
对于中间型指标:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FHGWEl2r-1655460949772)(https://www.zhihu.com/equation?tex=x%27%3D%5Cleft%5C%7B+%5Cbegin%7Bsplit%7D+%262%5Cfrac%7Bx-m%7D%7BM-m%7D%2C%5Cqquad+%26m%5Cle+x%5Cle%5Cfrac12%28M%2Bm%29%5C%5C+%262%5Cfrac%7BM-x%7D%7BM-m%7D%2C%26%5Cfrac12%28M%2Bm%29%5Cle+x%5Cle+M+%5Cend%7Bsplit%7D+%5Cright. “”)]
对于区间型指标:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NQVnkKdG-1655460949772)(https://www.zhihu.com/equation?tex=x%27%3D%5Cleft%5C%7B+%5Cbegin%7Bsplit%7D+%261-%5Cfrac%7Ba-x%7D%7Ba-a%5E%2A%7D%5Cqquad+%26x%5Clt+a+%5C%5C+%261%26a%5Cle+x%5Cle+b%5C%5C+%261-%5Cfrac%7Bx-b%7D%7Bb%5E%2A-b%7D%26x%5Cgt+b+%5Cend%7Bsplit%7D+%5Cright. “”)]
-
计算各评价指标与最优及最劣向量之间的差距
定义第i个评价对象与最大值的距离:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TGHvbA82-1655460949772)(https://pic2.zhimg.com/80/v2-3370dbbb6e23193c50d45da0c83847d5_1440w.jpg “”)]
定义第i个评价对象与最小值的距离:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j9Vylh1v-1655460949773)(https://pic3.zhimg.com/80/v2-59f1f0882b99d161db15db8a2c7a5832_1440w.jpg “”)]
其中z_j为第j个属性的权重(重要程度),指标权重可以使用熵权法或者层次分析法等方法确认。
D+和D-值的实际意义:评价对象与最优或最劣解的距离,值越大说明距离越远,研究对象D+值越大,说明与最优解距离越远;D-值越大,说明与最劣解距离越远。最理解的研究对象是D+值越小同时D-值越大。
-
评价对象与最优方案的接近程度
D-值相对越大,则说明该研究对象距离最劣解越远,则研究对象越好;C值越大, 表明评价对象越优:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZAsDfONL-1655460949773)(https://pic3.zhimg.com/80/v2-b5c8920029dece882deff2c807945ce6_1440w.jpg “”)]
熵权法原理:
1.topsis模型介绍
熵权法是一种客观赋权的方法,依据的原理是指标的变异程度越小,所反映的信息量也越少,其对应的权值也应该越低。(这里的客观指的是数据本身可以给定我们的权重)
2.熵权法的计算步骤
- 第一步:判断输入的矩阵中是否存在负数,如果有则要重新标准化到非负区间

- 第二步:计算第 j 项指标下第 i 个样本所占的比重,并将其看作相对熵计算中用到的概率。
 文章来源:https://www.toymoban.com/news/detail-440394.html
文章来源:https://www.toymoban.com/news/detail-440394.html - 第三步:计算每个指标的信息熵,并计算信息效用值,并归一化得到每个指标的熵权。
 文章来源地址https://www.toymoban.com/news/detail-440394.html
文章来源地址https://www.toymoban.com/news/detail-440394.html
到了这里,关于topsis算法模型和熵权法使用原理详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!