注意: 由于SOPHGO SE5微服务器的CPU是基于ARM架构,部分步骤将在 基于x86架构CPU的开发环境中完成
一、初始化开发环境(基于x86架构CPU的开发环境中完成)
二、模型转换 (基于x86架构CPU的开发环境中完成)
三、YOLOv5模型部署测试(在SOPHGO SE5微服务器上进行)
本实验代码和模型可在Connecting... 下载
一、初始化开发环境 (基于x86架构CPU的开发环境中完成)
1.1 初始化开发环境
1.2 配置Docker容器开发环境
以下步骤均在Docker容器中进行:
1. 安装nntc以及配置环境变量
# 切换成 root 权限
sudo -i
# 下载Docker镜像
wget https://sophon-file.sophon.cn/sophon-prod-s3/drive/22/07/19/10/x86_sophonsdk
_ubuntu18.04_py37_dev_22.06_docker.zip
# 确保环境安装unzip后解压
unzip x86_sophonsdk3_ubuntu18.04_py37_dev_22.06_docker.zip
# 进入文件夹并加载Docker镜像
cd x86_sophonsdk3_ubuntu18.04_py37_dev_22.06_docker
docker load -i x86_sophonsdk3_ubuntu18.04_py37_dev_22.06.docker
# 下载SOPHON SDK3.0.0
wget https://sophon-file.sophon.cn/sophon-prod-s3/drive/22/07/18/11/
sophonsdk_v3.0.0_20220716.zip
unzip sophonsdk_v3.0.0_20220716.zip
cd sophonsdk_v3.0.0
# 通过脚本文件创建并进入Docker容器
# 若您没有执行前述关于docker命令免root执行的配置操作,需在命令前添加sudo
./docker_run_sophonsdk.sh
cd /workspace/scripts/
./install_lib.sh nntc
# 设置环境变量-[有PCIe加速卡]
source envsetup_pcie.sh
# 设置环境变量-[无PCIe加速卡]
source envsetup_cmodel.sh
导出的环境变量只对当前终端有效,每次进入容器都需要重新执行一遍,或者可以将这些环境变量写入
~/.bashrc,这样每次登录将会自动设置环境变量
二、模型转换 (基于x86架构CPU的开发环境中完成)
由于BMNNSDK中的PyTorch模型编译工具BMNETP只接受PyTorch的JIT模型(TorchScript模型),需要用户自行将训练好的Pytorch模型进行转换。JIT(Just-In-Time)是一组编译工具,用于弥合PyTorch研究与生产之间的差距。它允许创建可以在不依赖Python解释器的情况下运行的模型,并且可以更积极地进行优化。在已有PyTorch的Python模型(基类为torch.nn.Module)的情况下,通过 torch.jit.trace 就可以得到JIT模型,如torch.jit.trace(python_model,torch.rand(input_shape)).save('jit_model') 。BMNETP暂时不支持带有控制流操作(如if语句或循环)的JIT模型,因此不能使用 torch.jit.script ,而要使用torch.jit.trace ,它仅跟踪和记录张量上的操作,不会记录任何控制流操作
2.1 将训练好的Pytorch模型转换为JIT模型
2.1.1 直接获取转换好的 JIT 模型
在sleep/sleep-aug-640.yolov5pytorch/yolov5s6/weights/best.trace.pt 为转换好的JIT模型
2.1.2 自行将训练好的Pytorch模型转换为JIT模型
下载ultralytics官方YOLOv5源码
# 在容器里, 以python3.7的docker为例
cd ${YOLOv5}
# 下载yolov5源码
git clone https://github.com/ultralytics/yolov5.git yolov5_github
# 切换到yolov5工程目录
cd yolov5_github
# 使用tag从远程创建本地v6.1分支
git branch v6.1 v6.1
git checkout -v6.1
# 将下载好的sleep导入yolov5_github
修改models/yolo.py中Detect类的forward函数的最后return语句,实现不同的输出
# 此模型为单输出
def forward(self, x):
return x if self.training else (torch.cat(z, 1)) # 1个输出
#return x if self.training else x # 3个输出
# return x if self.training else (torch.cat(z, 1), x) # 4个输出
导出JIT模型
cd ${yolov5}/yolov5_github目录下
# 创建python虚拟环境virtualenv
pip3 install virtualenv
# 切换到虚拟环境
virtualenv -p python3 --system-site-packages env_yolov5
source env_yolov5/bin/activate
# 安装依赖
pip3 install -r requirements.txt
# 此过程遇到依赖冲突或者错误属正常现象
# 导出jit模型
python3 export.py --weights ${sleep}/ sleep-aug-640.yolov5pytorch/yolov5s6/weights/best.pt --include torchscript
# 退出虚拟环境
deactivate
# 将生成好的jit模型best.torchscript拷贝到${YOLOv5}/build文件夹下
mkdir ../build
cp best.torchscript ../build/sleep_best_1output.trace.pt
# 拷贝一份到${YOLOv5}/data/models文件夹下
mkdir ../data/models
cp best.torchscript ../data/models/sleep_best_1output.trace.pt
2.2 模型转换:生成FP32 BModel
Python命令生成FP32 BModel
BMNETP是针对pytorch的模型编译器,可以把pytorch模型直接编译成BMRuntime所需的执行指令。
通过以下命令可以实现FP32 BModel模型的直接生成(确保生成的JIT模型拷贝至
${YOLOv5}/data/models 路径下):
cd ${YOLOv5}/data/models/
python3 -m bmnetp --mode="compile" \
--model=sleep_best_1output.trace.pt \
--outdir=sleep_best_1output \
--target="BM1684" \
--shapes=[[1,3,640,640]] \
--net_name=yolov5s_fp32_b1 \
--opt= 2 \
--dyn=False \
--cmp=True \
--enable_profile=True
上述脚本会在 ${YOLOv5}/data/models/sleep_best_1output 下生成 compilation.bmodel 文件
使用如下命令查看模型具体信息:
bm_model.bin –info compilation.bmodel

bmrt_test --bmodel compilation.bmodel

三、YOLOv5模型部署测试(在算能云开发平台进行)
3.1 准备示例程序
以下步骤在基于x86架构CPU的开发环境中进行
一、初始化开发环境
https://cloud.sophgo.com/developer

参考云开发平台手册学习使用
云空间文件系统对应命令行 /tmp 目录
二、模型转换处理好的YOLOv5项目文件拷贝至云开发平台上:
将sleep文件模型拷贝到云开发平台。
3.2 BModel测试(Python例程)
cd ${sleep}/bmodel/python
# BModel和图片路径名仅供参考,具体根据各自的路径进行修改
python3 yolov5_opencv.py --bmodel
../bmodels/sleep_best_1output/compilation.bmodel --input../../ sleep-aug-640.yolov5pytorch/test/images/
python3 yolov5_bmcv.py --bmodel
../bmodels/sleep_best_1output/compilation.bmodel --input../../ sleep-aug-640.yolov5pytorch/test/images/
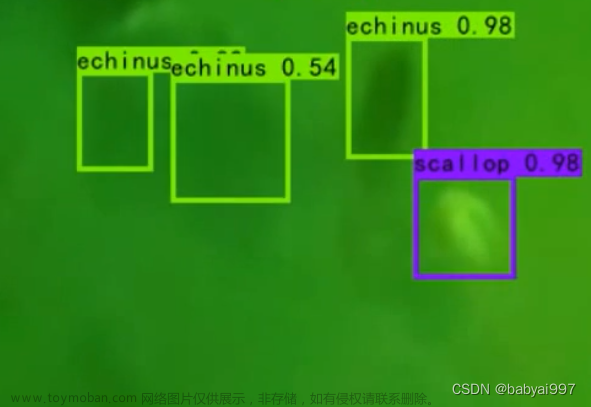
输出结果
 文章来源:https://www.toymoban.com/news/detail-440604.html
文章来源:https://www.toymoban.com/news/detail-440604.html

 文章来源地址https://www.toymoban.com/news/detail-440604.html
文章来源地址https://www.toymoban.com/news/detail-440604.html
到了这里,关于基于YOLOv5的儿童睡眠检测的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!