YOLO是最先进的目标检测模型之一。目标检测问题相比分类问题要更加复杂,因为目标检测不仅要把类别预测正确,还要预测出这个类别具体在哪个位置。
我将目标识别的评估指标总结为两部分,一部分为预测框的预测指标,另一部分为分类预测指标。
预测框的预测指标——IOU(交并比)
预测框的准确率用IOU来反映。交并比是目标检测问题中的一项重要指标,它在训练阶段反映的是标注框与预测框的重合程度,用于衡量预测框的正确程度。

如上图所示,绿色框为标注框,是在标注数据集时人为标注的框;红色框为预测框,是训练的模型预测出的预测框;中间的橙色区域则为两个框的重合区域。而判断这个模型预测框预测的准不准,就要看IOU了。

如上图所示,IOU指的就是两框的重叠部分的面积,与两框总共部分的面积之比。IOU又称交并比,从字面意思也可以理解,IOU就是两框交集与并集之比。IOU越接近于0,两框重叠越少;IOU越接近于1,两框的重叠程度越高,当IOU等于1时,两框完全重叠。
IOU要搭配IOU阈值一起使用。
IOU阈值一般被定为0.5,当两框的IOU大于阈值时,则判断预测框预测正确。IOU阈值可以修改,IOU阈值越高,则判断预测框预测正确的条件越严格。
分类预测指标
混淆矩阵
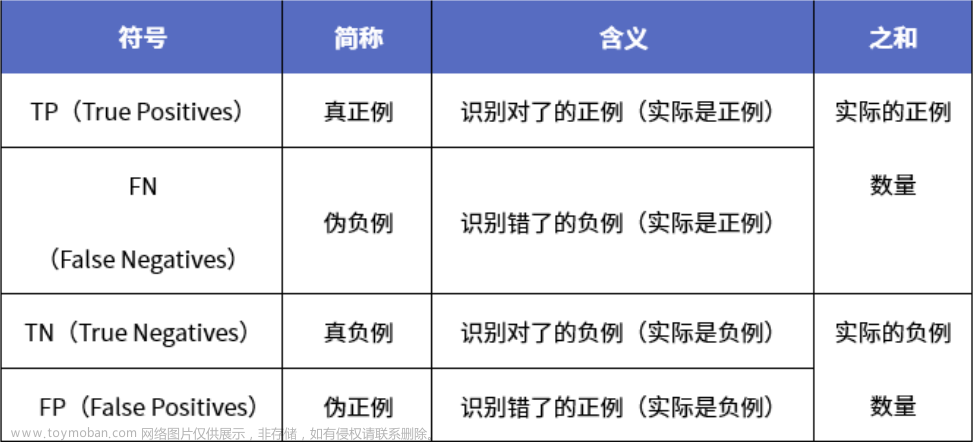
在机器学习和深度学习中,将分类任务的预测结果分为以下四种,被称作混淆矩阵:
True Positive(TP):预测出的为正例,标签值也为正例,预测正确
False Negative(FN):预测出的为负例,标签值为正例,预测错误
False Positive(FP):预测出的为正例,标签值为负例,预测错误
True Negative(TN):预测出的为负例,标签值为负例,预测正确
我在学习这块知识的时候,一直有一个疑问。在多分类的任务中,如何界定某个类别是正例或负例?后来才理解,这里的正例和负例其实只是针对某一类别而言的。例如,coco数据集有80个类别,针对person类而言,person类别就是正例,其他79个类别就是负例;针对car类而言,car类别就是正例,其他79个类别就是负例。
Precision(精度)
Precision指的是精度,Precision的定义如下:
根据定义,Precision的分母是TP与FP之和,TP是预测为正例,真实值也为正例的个数;FP是预测为正例,实际为负例的个数。
分析式子可知,Precision关心的是预测的正例,以及真实的正例和负例。当Precision越大时,FP越小,此时将其他类别预测为本类别的个数也就越少,可以理解为预测出的正例纯度越高。Precision越高,误检越少。
Recall(召回率)
Recall指的是召回率,Recall的定义如下:
根据定义,Recall的分母时TP与FN之和,TP是预测为正例,真实值也为正例的个数;FN是预测为负例,实际是正例的个数。
分析式子可知,Recall关心的是预测的正例和负例,以及真实的正例。当Recall越大时,FN越小,此时将正例预测为负例的个数越少,可以理解为把全部的正例挑出来的越多。Recall越高,漏检越少。
P-R曲线
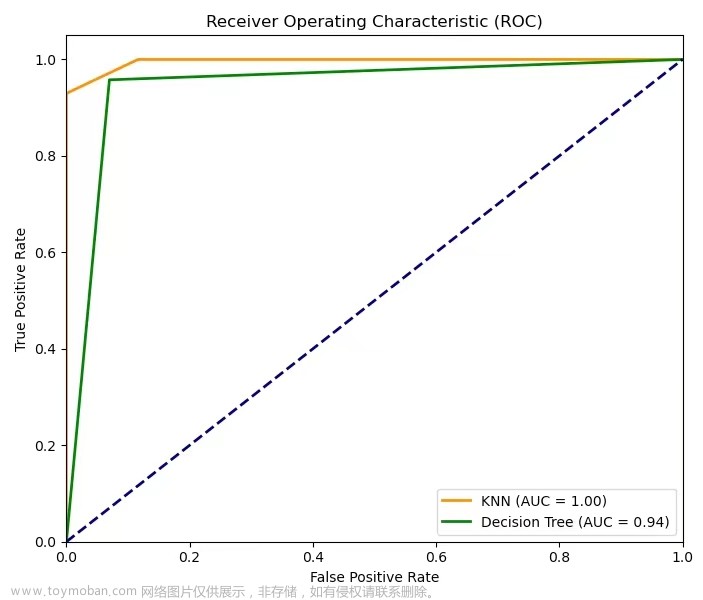
P-R曲线即为分别以Precision与Recall为坐标围成的曲线。如下图所示,这是一张我自己训练过程中产生的P-R曲线:

不同颜色的线代表不同类别的PR曲线,蓝色的粗线条表示所有类别平均的PR曲线
P-R曲线与坐标轴围成的面积,可作为衡量一个模型预测结果的参考。若一个模型的P-R曲线完全将另一模型的P-R曲线包裹,那么这个模型预测结果一定优于另一模型。
F1-score
如果有不同的几个模型,他们有着不同的Precision与Recall,那么我们应该如何挑最优的模型?
最直接的办法就是取Precision与Recall的平均值,但取平均值并不可取。因为有时二者有一个极高,一个极低时,这样平均值是高的,但实际的效果并不会好。这时就要用F1-score来权衡Precision与Recall的平均值。
化简得
根据F1-score的定义式可知,F1-score也是取平均值,只不过强调的是二者之间的较小值。通过F1-score的方式来权衡Precision与Recall,可以有效的避免短板效应,这在数学上被称为调和平均数。
mAP@0.5
有了预测框的预测指标与分类预测的指标,接下来将二者结合即为评价目标检测模型的指标。
AP
AP(average precision 平均精度):虽然名为平均精度,但AP的计算方法并不是计算Precision的平均值,而是计算每个类别的PR曲线与坐标轴围成的面积,可以用积分的方法进行计算。如果一个模型的AP越大,也就是说PR曲线与坐标轴围成的面积越大,Precision与Recall在整体上也相对较高。
mAP
mAP(mean of Average Precision) : 对所有类别的AP值求平均值。AP可以反映每个类别预测的准确率,mAP就是对所有类的AP求平均值,用于反映整个模型的准确率。mAP越大,PR曲线与坐标轴围城的面积越大。平时我们说的,某一目标检测算法的准确率达到了多少,这个准确率就泛指mAP。
mAP@0.5
在YOLO模型中,你会见到mAP@0.5这样的表现形式,这种形式表示在IOU阈值为0.5的情况下,mAP的值为多少。当预测框与标注框的IOU大于0.5时,就认为这个对象预测正确,在这个前提下再去计算mAP。一般来说,mAP@0.5即为评价YOLO模型的指标之一。文章来源:https://www.toymoban.com/news/detail-441248.html
mAP@[0.5:0.95]
YOLO模型中还存在mAP@[0.5:0.95]这样一种表现形式,这形式是多个IOU阈值下的mAP,会在q区间[0.5,0.95]内,以0.05为步长,取10个IOU阈值,分别计算这10个IOU阈值下的mAP,再取平均值。mAP@[0.5:0.95]越大,表示预测框越精准,因为它去取到了更多IOU阈值大的情况。文章来源地址https://www.toymoban.com/news/detail-441248.html
到了这里,关于YOLO 模型的评估指标——IOU、Precision、Recall、F1-score、mAP的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!