
C++布隆过滤器
用哈希表存储用户记录,缺点是需要消耗较大的内存;用位图存储用户记录,缺点是位图一般处理整形,内容是字符串或者自定义类型就很勉强。基于以上,若将哈希和位图结合,称为布隆过滤器,会不会把上面的问题都解决了呢?
概念
布隆过滤器是一种概率型数据结构。可以高效的插入和查询,然后告诉我们某个数据一定不在或者可能存在。它是用多个哈希函数,将一个数据映射到位图结构中。即可以提高查询效率,又可以节省内存空间。
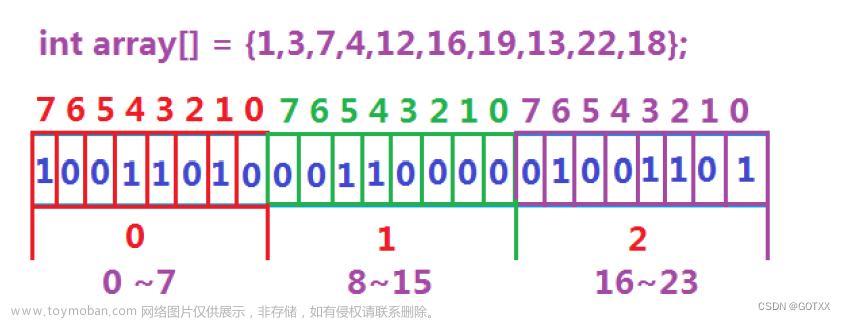
若只用一个哈希函数来映射到位图上,那么可能会发生以下情况。字符串string先存在了,然后来了一个字符串str通过映射到位图上,由于"str"与"string"发生了冲突,那么位图反馈给"str"的结果是"str"已存在。

若是用多个哈希函数进行映射,则会大大减少以上的情况。
当已经存在的数据通过两个哈希函数在位图上就有两个映射位置,新查询的的字符串"str"通过两个哈希函数映射,其中一个映射的位置与字符串"string"的一个映射位置发生冲突,但是字符串"str"还有一个映射位置是反馈不存在,那么字符串"str"就不存在。相比之前降低了误判率,但不能完全消除误判率。用的哈希函数越多,位图上要映射的位置就越多,相同的误判率就越低。

布隆过滤器在这样的场景下就是通过映射多个位置,降低误判率。
实质用途
当布隆过滤器判断一个数据存在可能是不准确的,因为这个数据通过多个哈希函数映射的位置可能都已经被1个或多个数据占用了,此时就需要进入数据库中查询。
当布隆过滤器判断一个数据不存在是准确的,因为数据映射的位置若被别的数据占用了,位图上的比特位会是1(没有被占用比特位上是0)
控制误判率
布隆过滤器过小,上面的所有的比特位被占用的比率(设置成1)就越大,此时布隆过滤器的误判率就越大,因此布隆过滤器的长度直接影响了误判率,布隆过滤器越大则误判率越小。
哈希函数的个数越多,单个数据需要映射到位图上的位置就需要越多,若此时布隆过滤器有过多的位置被设置成1,误判率就会很大,但哈希函数的个数太少,误判率也会很大。
那么如何选择布隆过滤器的长度和哈希函数的个数的权衡就直接控制了误判率
有大佬通过实验得出一下关系式
m
=
−
n
l
n
p
/
(
l
n
2
)
2
m=-nlnp/(ln2)^2
m=−nlnp/(ln2)2
k = l n 2 m / 2 k=ln2m/2 k=ln2m/2
其中n为插入的元素个数,p为误判率,m为布隆过滤器长度,k为哈希函数个数
这里我们估算一下,如果使用3个哈希函数,(k=3),ln2近似取值0.7,那么m和n关系是m=4.2n(布隆过滤器的长度应为插入元素个数的4.2倍)
实现
因为插入布隆过滤器的元素有字符串,也有其他数据类型包括自定义类型,所以可以实现为一个模板类,只需要调用者提供把数据类型转化成整形的哈希函数即可。一般情况下布隆过滤器用来处理字符串类型,所以这里模板参数缺省值给string
布隆过滤器的成员一般是一个位图,所以还需要提供一个非类型模板参数N,给调用者指定位图的长度。
下面调用了三个综合评分最高的四个哈希算法(把字符串转化成整形)
struct BKDRHash
{
size_t operator()(const string& key)
{
size_t hash = 0;
for (auto ch : key)
{
hash *= 131;
hash += ch;
}
return hash;
}
};
struct APHash
{
size_t operator()(const string& key)
{
unsigned int hash = 0;
int i = 0;
for (auto ch : key)
{
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ (ch) ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ (ch) ^ (hash >> 5)));
}
++i;
}
return hash;
}
};
struct DJBHash
{
size_t operator()(const string& key)
{
unsigned int hash = 5381;
for (auto ch : key)
{
hash += (hash << 5) + ch;
}
return hash;
}
};
struct JSHash
{
size_t operator()(const string& s)
{
size_t hash = 1315423911;
for (auto ch : s)
{
hash ^= ((hash << 5) + ch + (hash >> 2));
}
return hash;
}
};
插入和查找
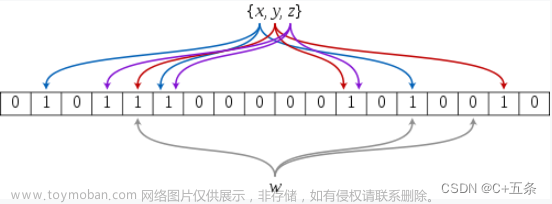
当元素插入到布隆过滤器时,需要把数据通过三个哈希函数计算映射到对应的位图上的位置设置成1(stl库中bitset中set的用法)
当用于检测某个数据是否在布隆过滤器中时,需要通过三个哈希函数计算得出数据映射在位图上的位置,然后判断这几个比特位:
若三个比特位全部被设置成1,就返回true表示数据存在(可能发生误判)
若只要有一个比特位没有被设置成1,立即返回false表示数据不存在(不存在是准确的)
template<size_t N,//最多存储的数据个数
size_t X=6,//平均存储一个数据要开辟6个映射位
class K=string,//数据类型的模板参数---缺省值给string
class HashFunc1=BKDRHash,
class HashFunc2 = APHash,
class HashFunc3 = DJBHash>
//class HashFunc4 = JSHash>
class BloomFilter
{
public:
void Set(const K&key)
{
size_t hashi1 = HashFunc1()(key) %(N * X);
size_t hashi2 = HashFunc2()(key) % (N * X);
size_t hashi3 = HashFunc3()(key) % (N * X);
_bts.set(hashi1);
_bts.set(hashi2);
_bts.set(hashi3);
//size_t hashi4 = HashFunc4()(key) % (N * X);
}
bool Test(const K& key)
{
size_t hashi1 = HashFunc1()(key) % (N * X);
if (!_bts.test(hashi1))//数据不在是确定的
{
return false;
}
size_t hashi2 = HashFunc2()(key) % (N * X);
if (!_bts.test(hashi2))//数据不在是确定的
{
return false;
}
size_t hashi3 = HashFunc3()(key) % (N * X);
if (!_bts.test(hashi3))//数据不在是确定的
{
return false;
}
return true;//可能存在误判--映射的几个位置都冲突,就会发生误判
}
private:
std::bitset<N* X> _bts;//开辟最多存储的数据个数*平均存储一个数据要开辟的映射位
};
事例

实际上布隆过滤器只能降低误判率,而不能完全消除,多次实验后还是会有冲突的数据。

布隆过滤器的删除
布隆过滤器一般不支持删除操作,理由如下:
布隆过滤器判断一个数据存在是不确定的(数据的存在可能是误判)
- 当要删除的数据存在布隆过滤器是误判时,删除该数据对应的位图上的比特位(把对应的比特位由1置0)会影响其他也映射到这些位置上的数据。
- 无论要删除的数据是否真的在位图上,删除该数据的操作都会影响到其他也映射到相同位置上的数据。
若确定要支持删除操作,当删除数据时最好进入数据库(磁盘)中确认数据是否存在,这个过程要通过文件IO流,这个过程相对缓慢,效率极低;另一种方法是位图上每个比特位都新增一个计数器,当有插入数据,映射到这个比特位上,计数器++,当要删除数据时,对应的比特位上的计数器–。但这个方法会导致位图需要的内存成倍增加,代价巨大。所以一般而言布隆过滤器不支持删除操作。
布隆过滤器优点
- 增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无关
- 哈希函数相互之间没有关系,方便硬件并行运算
- 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
- 在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势
- 数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
- 使用同一组散列函数的布隆过滤器可以进行交、并、差运算
布隆过滤器缺陷
- 有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再
建立一个白名单,存储可能会误判的数据) - 不能获取元素本身
- 一般情况下不能从布隆过滤器中删除元素
- 如果采用计数方式删除,可能会存在计数回绕问题
相关大数据题目
给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件的交集?给出近似算法
解题思路:
先读取其中一个文件中的query,将其全部插入到布隆过滤器中。
再读取另一个文件只的query,依次判断每个query是否在布隆过滤器中,若存在,则是两个文件的交集,把交集再放到同一个文件中。但这个存储交集的文件还需要去重工作,把这个文件放到set或者map中进行去重。这个算法可能会存在误判—近似算法。
准确算法:
假设平均每个query是50byte,100亿个query合计500GB。由于我们只有1G内存,所以我们把一个文件的query通过hashfunc函数切分成400个文件。每个query作为key,通过hashfunc函数转化成整形i,i是多少就进入对应i的Ai或Bi文件。这样两个大文件的query都能切分到对应的小文件里。

切分两个大文件是用的hashfunc函数要是一样的,这样通过hashfunc函数切分A文件和B文件出来的i是相同的,key对应的query大概率也是相同的(query可能会冲突)
现在只需要在A0和B0、A1和B1、A2和B2…小文件中寻找交集即是原本两个大文件的交集。

理论上切分出来的每个小文件的平均大小是512M,因此我们可以将对应i的值其中一个的小文件加载到内存中放到set里,然后依次遍历另外一个小文件中的query,依次判断每个query是否在set容器中,若存在则是交集。
但因为切分文件时并不是平均切分的,所以切分出来的小文件大小有可能超过1G。
若对应i的值的两个小文件其中一个的大小没有超过1G,就把较小的那个小文件加载到内存中放进set里,然后遍历那个较大的,判断交集。文章来源:https://www.toymoban.com/news/detail-441359.html
.(img-u5LNDvmc-1682421381710)]
理论上切分出来的每个小文件的平均大小是512M,因此我们可以将对应i的值其中一个的小文件加载到内存中放到set里,然后依次遍历另外一个小文件中的query,依次判断每个query是否在set容器中,若存在则是交集。
但因为切分文件时并不是平均切分的,所以切分出来的小文件大小有可能超过1G。
若对应i的值的两个小文件其中一个的大小没有超过1G,就把较小的那个小文件加载到内存中放进set里,然后遍历那个较大的,判断交集。
若对应i的值的两个小文件的大小都超过了1G,就按照上面切分方式再次切分这两个小文件。切分完后在判断是不是交集。文章来源地址https://www.toymoban.com/news/detail-441359.html
到了这里,关于C++哈希应用——位图布隆过滤器的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!







![【数据结构】盘点那些经典的 [哈希面试题]【哈希切割】【位图应用】【布隆过滤器】(10)](https://imgs.yssmx.com/Uploads/2024/02/764640-1.png)



