0.前言
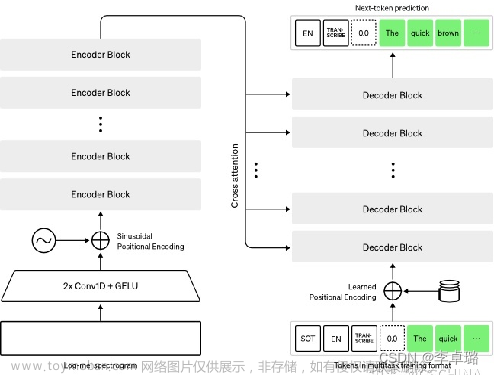
语音识别(Automatic Speech Recognition, ASR,或称语音转录文本)使声音变得"可读",让计算机能够"听懂"人类的语言并做出相应的操作,是人工智能实现人机交互的关键技术之一。在《图像字幕生成》一节中,我们已经学习了如何将手写文本图像转录为文本,在本节中,我们将利用类似的端到端模型实现将语音转录文本文章来源地址https://www.toymoban.com/news/detail-441571.html
文章来源:https://www.toymoban.com/news/detail-441571.html
到了这里,关于Keras深度学习实战(41)——语音识别的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!