0、写在最前:
----2022.10.10 更新yolov5-seg实例分割模型:
2022.09.29更新 c++下面使用opencv部署yolov5和yolov7实例分割模型(六)_爱晚乏客游的博客-CSDN博客
-----2022.07.25 更新了下yolov7的部署,有需要的自取
2022.07.25 C++下使用opencv部署yolov7模型(五)_爱晚乏客游的博客-CSDN博客
此篇文章针对yolov5的6.0版本,4.0和5.0版本请看前面三篇的修改。
2022.10.13 更新
有些人使用的是最新的torch1.12.x版本,在导出onnx的时候需要将do_constant_folding=True,这句换成false,否者dnn读取不了onnx文件,而onnxrutime可以,具体原因未知。
torch.onnx.export(
model.cpu() if dynamic else model, # --dynamic only compatible with cpu
im.cpu() if dynamic else im,
f,
verbose=False,
opset_version=opset,
do_constant_folding=False,
input_names=['images'],
output_names=output_names,
dynamic_axes=dynamic or None)2022.02.18更新:
最新版的代码在windows下面导出onnx可能会失败,windows10下面请保证pandas>=1.4.0,或者注释掉export.py中的import pandas as pd(pandas的功能暂时未在export.py使用,win10下直接import版本低于1.4.0其他都不干,导出onnx就会失败,原因未知)
2021.12.6更新,增加摄像头和视频检测,需要将drawPred()中的inshow和waitkey注释掉。
VideoCapture cap(0); //视频检测将0改成视频地址
while (true) {
Mat fram;
cap >> fram;
vector<Output> result;
if (test.Detect(fram, net, result))
test.drawPred(fram, result, color);
imshow("detect output", fram);
if (waitKey(2)==27) break; //esc退出
}
cap.release();
destroyAllWindows();2021.11.04更新,对于图片长宽比过大导致目标检测失败修改,本来想偷懒直接放个图片的。

此篇除了第4点修改检测的代码修改,其他代码和第三篇中的一样!
目录
0、写在最前:
一、yolov5 6.0版本新增对opencv的支持
二、导出onnx模型
三、查看网络结构。
四、修改检测代码
一、yolov5 6.0版本新增对opencv的支持
最新的项目地址可以看下https://github.com/ultralytics/yolov5
二、导出onnx模型
导出onnx的时候需要修改参数,将opset默认值改成12,原来的默认值为13,我测试了opencv4.5.0和4.5.2两个版本,opencv都报错了,将之改成12即可读取。
在export.py中修改下参数(用命令行导出的请加上--opset 12,请注意不要带上dynamic参数,opencv对动态输入支持做的不好,应该是需要opencv4.5.3以上的版本,并且需要TBB支持才行来着):

三、查看网络结构。
使用netron(www.netron.app)查看下修改onnx版本之后的网络模型,可以看到现在模型有4个输出1,output是另外三个输出的总输出,而另外三个就是之前模型的三个输出口(P3,P4,P5)。所以我们只需要遍历output这个输出口就可以(另外三个输出口是可以单独遍历获取数据,如果你只需要小目标,就可以只遍历P3输出口,中目标为P4输出口,而P5位大目标,但是并不建议这么做就是了,因为大中小并没有具体的区分,只是一个概念性的,实际上小目标也有可能在P4口被检测出来,而且概率比P3口还高也是有可能的。所以如果只需要检测小目标,还不如直接修改网络只要P3出口来的好一些)。

而输出口的形状由之前的[25200,85]变成了[1,25200,85],因为是一个batch size,所以在c++下面使用指针遍历的话可以不考虑这多出来的一个维度(c++下Mat.data指针会将三维和二维按行优先展开成一维指针,所以影响不大)。
四、修改检测代码
按照我前面三篇修改过的方法来说,应为新版本不需要再修改原来的common.py和yolo.py的代码,所以需要看下原来在yolo.py中被修改的部分做了些什么,然后需要对c++源码进行一些修改。
之前在models/yolo.py中的Detect类中的修改,会将红色框的部分注释掉,所以在c++的代码中这部分需要我们自己去计算,而现在不需要修改了,就要将这部分自己的计算去掉。

由于python的模型已经做了sigmoid的转换了,所以c++下面这部分去掉就可以了。按下面的位置修改下,原来的代码就可以使用了(注释部分的代码是原来的代码)。另外的代码请看
2021.09.02更新说明 c++下使用opencv部署yolov5模型 (三)_爱晚乏客游的博客-CSDN博客

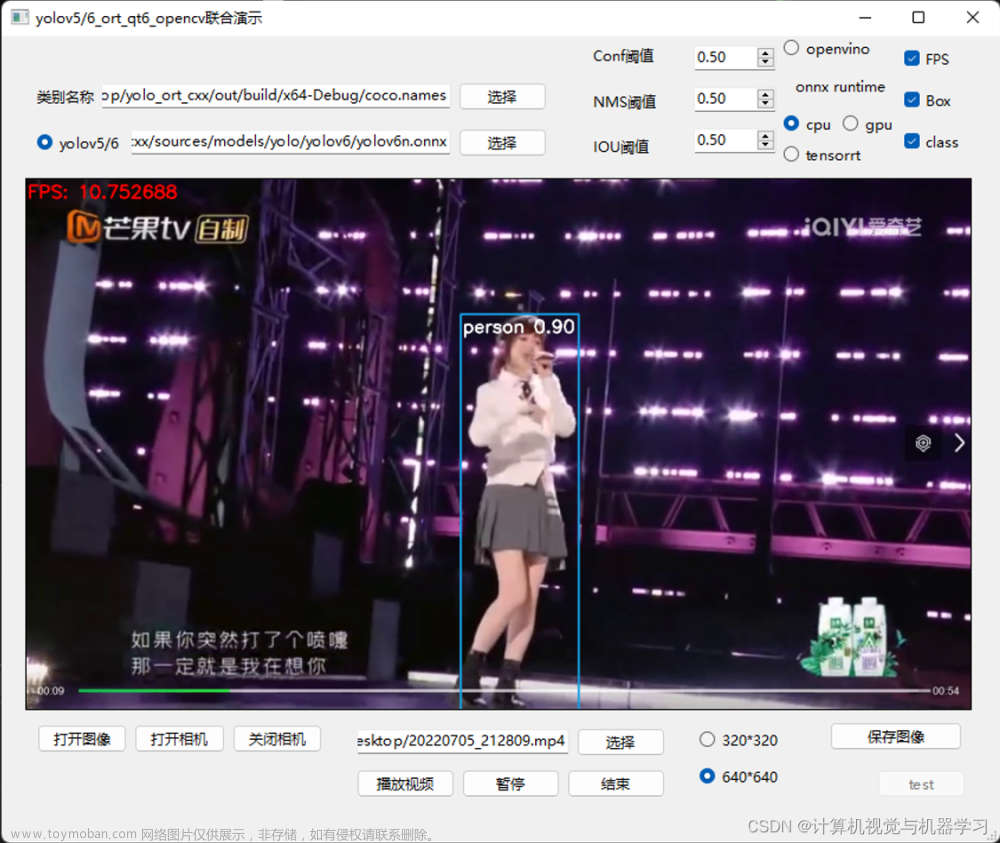
测试下程序结果:

完美运行!
总的来说,6.0版本完美的解决了opencv下读取onnx模型的痛点,不需要繁琐的去修改源码,将无法读取的网络层替换掉,可以很轻松的部署了。
贴个github链接吧,聊胜于无,想偷懒的同学可以直接下载文件了,不需要从上一篇复制了
https://github.com/UNeedCryDear/yolov5-opencv-dnn-cpphttps://github.com/UNeedCryDear/yolov5-opencv-dnn-cpp
onnx测试模型:yolov5s.onnx-深度学习文档类资源-CSDN下载文章来源:https://www.toymoban.com/news/detail-441635.html
目前是免费的,有需要收费了说下我重新改下文章来源地址https://www.toymoban.com/news/detail-441635.html
到了这里,关于2021.11.01 c++下 opencv部署yolov5-6.0版本 (四)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!






![[BPU部署教程] 教你搞定YOLOV5部署 (版本: 6.2)](https://imgs.yssmx.com/Uploads/2024/02/619039-1.png)



