前言
上一篇介绍了 MySQL 的存储过程和触发器,这一篇将介绍表分区和分库分表相关的内容。
表分区
原本的表文件都是以完整的形式存储在磁盘中,而表分区则是指将一张表的数据拆分成多个磁盘文件,然后放到磁盘中存储。
做了表分区之后,表在逻辑上还是同一张,只是磁盘中会划分为多个文件存储而已,所以表分区并不会影响原有的增删改查操作。
表分区只能进行水平划分,即以行为粒度进行划分,一条记录只能在一个分区中。
好处:
- 相较于使用单个文件存储表数据,表分区技术可以打破单个磁盘分区的容量限制。
- 对于一些失效数据,如三年前的数据,可以通过快速删除分区的方式清理,效率十分高。
- 能够在一定程度上提升磁盘 IO 检索数据的性能,毕竟只需对一小片磁盘表文件做寻道。
- 支持聚合函数的并行执行,比如 sum()、count() 这类函数,可以分别统计各分区的数据做汇总。
- 带来更好的数据管理性和可用性,当一个表文件受损时,不会影响其他分区文件中的表数据。
限制:
- 单张表最多只能创建 1024 个分区,MySQL5.6 版本中拓展到 8192 个。
- MySQL5.1 及之前的版本中,分区键只能选择整数型字段,或支持哈希函数处理的字段。
- 对一个表做了分区后,后续使用表的过程中,无法对表上的其他字段建立唯一索引。
- 分区表中无法创建外键,不过一般情况下表也不允许创建外键,都是靠逻辑上维护主外关系。
- 表中存在主键、唯一键的情况下,分区键的字段必须为主键或唯一键的部分或全部字段。
在 MySQL 中总共支持六种分区类型:range、list、hash、key、sub、columns。
RANGE
按照一个字段范围进行分区,仅支持整数类型字段作为分区键,如果想要以日期字段来做数据分区,需要想将其转换为整数格式的时间戳。
partition by range(r_id)(
partition p1 values less than (100000),
partition p2 values less than (200000),
partition p3 values less than (300000),
partition p4 values less than maxvalue
);
-- 查询 zz_range 表中不同分区的数据量
select
partition_name,table_rows
from
information_schema.partitions
where
table_name = 'zz_range';
LIST
枚举分区,只支持整数字段作为分区键。如果插入的数据在所有分区中找不到对应的值,会直接报错。
partition by list(l_sex)(
partition p1 values in (0),
partition p2 values in (1)
);
HASH
哈希分区中支持两种哈希分区法:
- 常规哈希:基于某个整数型字段,直接做取模,最后根据余数来决定数据的分区。
- 线性哈希:基于某个字段哈希之后的哈希值,进行取模运算,最后根据余数来决定数据的分区。
常规哈希只能基于整数型字段对数据做划分;线性哈希则可以不限制字段的类型,只要能够通过 MySQL 哈希函数,转换出哈希值的字段类型都可以作为分区键(但本质上 MySQL 中好像没有提供将字符串转换为数值类型的哈希函数)。
-- 选用 h_id 作为分区键,划分为三个分区
partition by hash(h_id)
partitions 3;
-- 使用线性哈希分区
partition by linear hash(lh_id)
partitions 3;
KEY
在 hash 分区中,想要使用一个字段作为分区键,要么这个字段本身是整数类型,要么这个字段经过哈希函数处理后,能够得到一个整数的哈希值才行。但在 key 分区中,除开不支持 text、blob 两种类型外,其他类型的字段都可以作为分区键。
在 key 分区中也可以不显式指定分区键,MySQL 会自动选择,但不管是自己显式声明分区键,亦是 MySQL 自动选取分区键,都会遵循如下规则:
- 表中只存在主键或唯一字段时,分区键必须为主键/唯一键的部分或全部字段,不允许选择其他字段。
- 表中主键、唯一字段同时存在时,分区键必须为主键和唯一键共有的部分或全部字段。
- 当表中不存在主键或唯一键时,分区键可以是除 text、blob 类型外的任意单个或多个字段。
partition by key(k_name)
partitions 3;
SUB
又称子分区,所谓的子分区是指基于表分区后的结果,进一步做分区处理,也就是基于一个分区再做分区,好比一张表可以基于日期中的年份做分区,基于年份做了分区后,还可以基于年分区进一步做月分区。
这种方式要求每个一级分区下的二级分区数量都一致,同时二级分区的类型只能为 hash、key 类型。
partition by range(year(register_time))
subpartition by hash(month(register_time))
(
partition p1 values less than (2000)(
subpartition p1_s1,
subpartition p1_s2
),
partition p2 values less than (2020)(
subpartition p2_s1,
subpartition p2_s2
),
partition p3 values less than maxvalue(
subpartition p3_s1,
subpartition p3_s2
)
);
COLUMNS
cloumns 分区实际上是 range、list 分区的变种,cloumns 分区可以使得 range、list 的分区键由多个字段来组成,同时支持的字段类型也相对更丰富一些,但这种分区法一般用的极少。
分表
垂直分表
当一张表由于字段过多时,会导致表中每行数据的体积变大,一方面会导致磁盘 IO 次数增多,影响数据的读写效率;同时另一方面结果集响应时还会占用大量网络带宽,影响数据的传输效率;再从内存维度来看,单行数据越大,缓冲区中能放下的热点数据页会越少,当读写操作无法在内存中定位到相应的数据页,从而又会产生大量的磁盘 IO。
垂直分表一半可以根据冷热字段对表进行拆分。拆分的表中需要保存外键来建立联系。
由于修改数据时会同时修改多张表,所以需要使用事务来保证原子性。
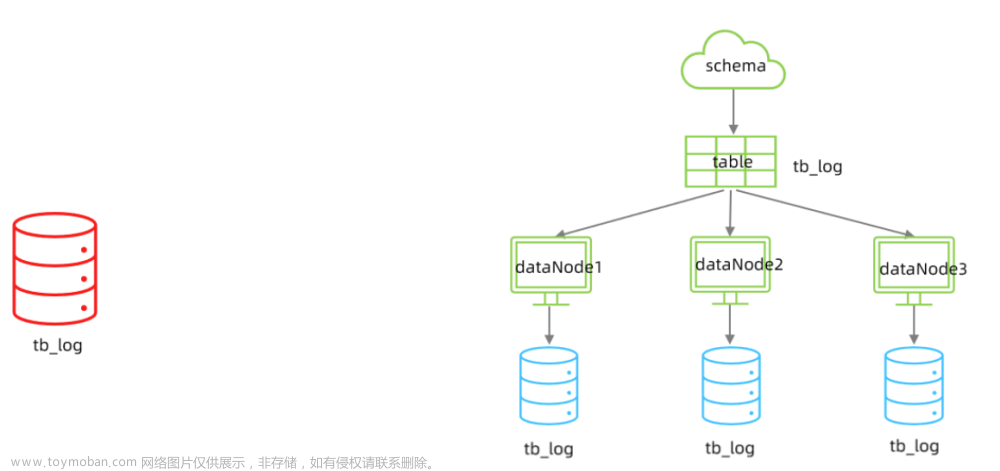
水平分表
当一张表内的数据量过大(一般要求控制在 500-1200w 之间),查询性能就会下降,从而需要对表进行水平拆分。
水平分表后,多个表的表结构、索引相同,数据不同,每张表中会存储不同范围的数据。
水平分表和表分区十分类似,一般会选用水平分表方案。
由于数据会被存储到多个表中,所以进行增删改查数据前,需要定位到相应的表中再进行操作。且进行聚合操作时,需要从多个表中取出数据,再在后端进行聚合操作,或者依赖 Redis、ES 等第三方中间件来完成。
另外,可能出现多个表中 ID 相同,数据不同的情况,所以要合理设置 ID 规则来避免。比如可以设置交叉增长的 ID;可以利用特殊算法(雪花算法等)生成有序的分布式 ID;利用第三方中间件生成 ID 等。
分库
如果数据库整体负载都很高,那不管再怎么做分表也不能解决问题,此时就需要考虑分库方案。
垂直分库
可以按业务特性将大库拆分为多个业务功能单一的小库,每个小库只为对应的业务提供服务。
一次查询需要的数据如果被分到了多个库中,就需要用额外的手段来获取数据。比如通过广播表/网络表/全局表将对应的表数据直接完全同步一份到相应库中;或者在程序中组装数据再返回。
修改数据时,可能会一次性修改不同库中的数据,所以需要考虑数据一致性问题,即分布式事务问题,就需要分布式锁等额外的手段来保证数据一致性。
垂直分库无法解决部分库的性能瓶颈,所以可能还需要分表或者水平分库。
水平分库
当单个数据库节点的性能达到瓶颈后,除了提升该节点的配置外,还可以通过水平拆分的方案,将数据存储在多个节点上,从而分担压力。
水平分表中存在的问题在水平分库中也会遇到。
最后
本文介绍了 MySQL 的表分区和分库分表。文章来源:https://www.toymoban.com/news/detail-441797.html
下一节将介绍 MySQL 的主从架构。文章来源地址https://www.toymoban.com/news/detail-441797.html
到了这里,关于MySQL原理(九):表分区和分库分表的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!