一、链表
1.1 定义
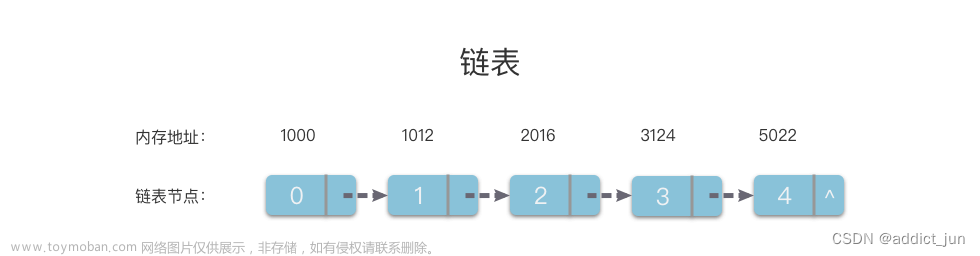
链表是一种常见的数据结构由一系列节点按顺序连接而成,一般每个节点包含一个数据元素和一个指向下一个节点的引用。
链表有多种类型:
- 单向链表:每个节点只有一个指向下一个节点的引用
- 双向链表:每个节点有一个指向前一个节点和一个指向后一个节点的引用
- 循环链表:尾节点指向头节点形成循环
- 双向循环链表:既是双向链表又是循环链表
1.2 实现
1.2.1 单向链表
单向链表是指每个节点包含一个指向下一个节点的指针,最后一个节点的指针为NULL。
以下是单向链表的基本结构:
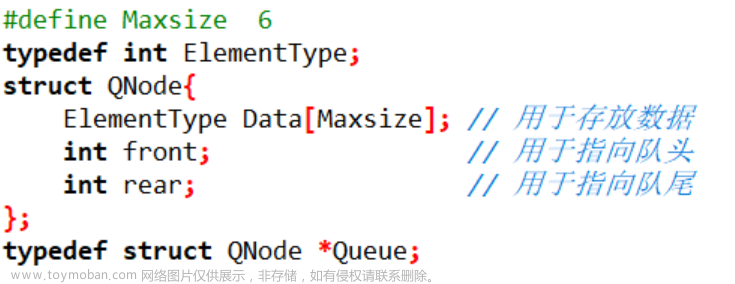
struct ListNode
{
int val;
ListNode *next;
ListNode(int x) : val(x), next(NULL) {}
};
1.2.2 双向链表
双向链表是在单向链表的基础上,每个节点还包含一个指向上一个节点的指针。
以下是双向链表的基本结构:
struct ListNode
{
int val;
ListNode *prev;
ListNode *next;
ListNode(int x) : val(x), prev(NULL), next(NULL) {}
};
1.2.3 常见操作(反转 合并 查找)
/* 链表反转 */
Node* reverseLinkedList(Node* head) {
Node* newHead = nullptr;
while(head != nullptr) {
Node* tmp = head->next;
head->next = newHead;
newHead = head;
head = tmp;
}
return newHead;
}
/* 链表合并 */
Node* mergeLinkedList(Node* head1, Node* head2) {
Node* dummy = new Node;
Node* cur = dummy;
while(head1 != nullptr && head2 != nullptr) {
if(head1->data < head2->data) {
cur->next = head1;
head1 = head1->next;
} else {
cur->next = head2;
head2 = head2->next;
}
cur = cur->next;
}
cur->next = (head1 != nullptr ? head1 : head2);
return dummy->next;
}
/* 链表查找 */
Node* findNode(Node* head, int data) {
Node* cur = head;
while(cur != nullptr && cur->data != data) {
cur = cur->next;
}
return cur;
}
1.3 应用
链表在程序中有着多种应用 例如:
- 实现LRU缓存淘汰算法
- 实现文件系统中的文件块分配
- 链表作为数据流的缓冲区
使用双向循环链表实现的LRU缓存示例:
class LRUCache
{
private:
struct CacheNode
{
int key;
int value;
CacheNode(int k, int v) : key(k), value(v) {}
};
int capacity;
list<CacheNode> cacheList;
unordered_map<int, list<CacheNode>::iterator> cacheMap;
public:
LRUCache(int capacity)
{
this->capacity = capacity;
}
int get(int key)
{
if (cacheMap.find(key) == cacheMap.end())
{
return -1;
}
// 把当前节点移到链表头部
cacheList.splice(cacheList.begin(), cacheList, cacheMap[key]);
return cacheMap[key]->value;
}
void put(int key, int value)
{
if (cacheMap.find(key) == cacheMap.end())
{
if (cacheList.size() == capacity)
{
// 删除链表最后一个节点
int key = cacheList.back().key;
cacheMap.erase(key);
cacheList.pop_back();
}
cacheList.push_front(CacheNode(key, value));
cacheMap[key] = cacheList.begin();
}
else
{
// 修改节点的值,并移到链表头部
cacheMap[key]->value = value;
cacheList.splice(cacheList.begin(), cacheList, cacheMap[key]);
}
}
};
使用LRU缓存:
LRUCache cache = LRUCache(2);
cache.put(1, 1);
cache.put(2, 2);
cout << cache.get(1) << endl; // 输出 1
cache.put(3, 3);
cout << cache.get(2) << endl; // 输出 -1,因为键 2 已经被删除了
cache.put(4, 4);
cout << cache.get(1) << endl; // 输出 -1,因为键 1 已经被删除了
cout << cache.get(3) << endl; // 输出 3
cout << cache.get(4) << endl; // 输出 4
二、 栈-Stack 队列-Queue
1.1 定义
- 栈(Stack):后进先出(LIFO: Last In First Out)
- 队列(Queue):先进先出(FIFO: First In First Out)
栈和队列是C++提供的两种基本数据类型,定义如下:
// 栈的定义
template <class T> class Stack {
public:
Stack(); // 构造函数
void push(const T&); // 将元素加入栈顶,返回 void
void pop(); // 移除栈顶的元素,返回 void
T& top(); // 返回栈顶元素的引用,不移除该元素
const T& top() const; // 返回常量栈顶元素的引用,不移除该元素
bool empty() const; // 判断栈是否为空,返回 bool
int size() const; // 返回栈中元素的个数
};
// 队列的定义
template<class T> class Queue {
public:
Queue(); // 构造函数
void push(const T&); // 将元素加入队尾,返回 void
void pop(); // 移除队头的元素,返回 void
T& front(); // 返回队头元素的引用,不移除该元素
const T& front() const; // 返回常量队头元素的引用,不移除该元素
bool empty() const; // 判断队是否为空,返回 bool
int size() const; // 返回队中元素的个数
};
1.2 实现
栈和队列的实现方法比较简单可以使用数组或链表来实现
1.2.1 数组实现 栈和队列 示例:
// 数组实现的栈
template <class T> class Stack {
T* a;
int n; // 栈的大小
int t; // 栈顶元素的下标
public:
Stack(int maxn) {
a = new T[maxn];
n = maxn;
t = -1;
}
bool empty() const {
return t == -1;
}
void push(const T& x) {
a[++t] = x;
}
void pop() {
--t;
}
T top() const {
return a[t];
}
};
// 数组实现的队列
template<class T> class Queue {
T* a;
int n; // 队列的大小
int head, tail; // 队头和队尾的下标
public:
Queue(int maxn) {
a = new T[maxn];
n = maxn;
head = 0;
tail = -1;
}
bool empty() const {
return head > tail;
}
void push(const T& x) {
a[++tail] = x;
}
void pop() {
++head;
}
T front() const {
return a[head];
}
};
1.2.3链表实现 栈和队列 示例:
// 链表实现的栈
template <class T> class Stack {
// 定义链表节点
struct node {
T data;
node* next;
node(const T& d, node* n = nullptr): data(d), next(n) {}
};
node* t; // 栈顶节点
public:
Stack() : t(nullptr) {} // 默认构造函数
bool empty() const {
return t == nullptr;
}
void push(const T& x) {
t = new node(x, t);
}
void pop() {
node* tmp = t;
t = t->next;
delete tmp;
}
T& top() const {
return t->data;
}
};
// 链表实现的队列
template <class T> class Queue {
// 定义链表节点
struct node {
T data;
node* next;
node(const T& d, node* n = nullptr) : data(d), next(n) {}
};
node* head; // 队头节点
node* tail; // 队尾节点
public:
Queue() : head(nullptr), tail(nullptr) {} // 默认构造函数
bool empty() const {
return head == nullptr;
}
void push(const T& x) {
if (tail != nullptr) {
tail->next = new node(x);
tail = tail->next;
} else {
head = tail = new node(x);
}
}
void pop() {
node* tmp = head;
head = head->next;
delete tmp;
if (head == nullptr) {
tail = nullptr;
}
}
T& front() const {
return head->data;
}
};
1.3 应用
栈和队列是常用的数据结构在程序中的应用广泛,例如:
- 表达式求值
- 函数调用
- 网络请求处理
- 路径搜索
如下使用栈来实现表达式求值示例:
// 使用栈来实现表达式求值
double calc(const string& s) {
Stack<double> stk;
for (int i = 0; i < s.size(); ++i) {
if (isdigit(s[i])) {
int j = i;
while (j < s.size() && (isdigit(s[j]) || s[j] == '.')) ++j;
stk.push(stod(s.substr(i, j - i)));
i = j - 1;
} else if (s[i] == '+') {
double b = stk.top(); stk.pop();
double a = stk.top(); stk.pop();
stk.push(a + b);
} else if (s[i] == '-') {
double b = stk.top(); stk.pop();
double a = stk.top(); stk.pop();
stk.push(a - b);
} else if (s[i] == '*') {
double b = stk.top(); stk.pop();
double a = stk.top(); stk.pop();
stk.push(a * b);
} else if (s[i] == '/') {
double b = stk.top(); stk.pop();
double a = stk.top(); stk.pop();
stk.push(a / b);
}
}
return stk.top();
}
三、树和二叉树
1.1 定义
1.1.1 树的定义
树是一种非线性的数据结构,它由n个节点组成的有限集合,其中每个节点是一个具有唯一标识的对象,且节点之间存在着一些特定的关系。通常这些关系可以用父子关系来描述。每个节点可以有多个子节点,但是一个节点只有一个父节点,树中有且仅有一个无父节点的节点这个节点被称为根节点。
1.1.2 树的特点
- 树中的每个节点都有唯一的标识
- 树中每个节点至少有一个子节点
- 树中节点之间的关系是“父子”关系
- 树中有且仅有一个无父节点的节点这个节点被称为根节点
- 树中任意两个节点之间都存在一条唯一的路径
1.1.3 二叉树的定义
二叉树是一种特殊的树结构,每个节点最多有两个子节点,它的左子节点和右子节点分别称为左子树和右子树
1.1.4 二叉树的特点
- 二叉树中的每个节点都有唯一的标识
- 一个节点最多只有两个子节点
- 二叉树中节点之间的关系是“父子”关系
- 如果二叉树中任意一个节点(除了叶子节点),其左子树不为空则左子树中的所有节点的值都小于这个节点的值.如果其右子树不为空则右子树中所有节点的值都大于这个节点的值。
1.2 实现
1.2.1 实现方法
树和二叉树可以通过结构体和指针实现,使用链式结构来描述。节点包括一个数据域和两个指针域分别指向左右子树。
// 定义树节点结构体
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};
1.2.2 常用算法
- 先序遍历:遍历顺序为根结点、左子树、右子树。
- 中序遍历:遍历顺序为左子树、根结点、右子树。
- 后序遍历:遍历顺序为左子树、右子树、根结点。
- 层序遍历:按层遍历二叉树。
先序遍历的代码示例:
void preorder_traversal(TreeNode *node) {
if (node) {
cout << node->val << " ";
preorder_traversal(node->left);
preorder_traversal(node->right);
}
}
中序遍历的代码示例:
void inorder_traversal(TreeNode *node) {
if (node) {
inorder_traversal(node->left);
cout << node->val << " ";
inorder_traversal(node->right);
}
}
后序遍历的代码示例:
void postorder_traversal(TreeNode *node) {
if (node) {
postorder_traversal(node->left);
postorder_traversal(node->right);
cout << node->val << " ";
}
}
层序遍历的代码示例:
void level_order_traversal(TreeNode *node) {
queue<TreeNode *> q;
q.push(node);
while (!q.empty()) {
TreeNode *temp = q.front();
q.pop();
cout << temp->val << " ";
if (temp->left) {
q.push(temp->left);
}
if (temp->right) {
q.push(temp->right);
}
}
}
1.3 应用
在程序中的应用有:
- 堆排序算法
- 哈夫曼编码
- 字典树
- AVL树(自平衡二叉搜索树)
- B树和B+树(多路搜索树)
四、 图结构
1.1 定义
1.1.1 图的定义
图是一种数据结构,它由节点/顶点 (vertex)和边(edge)组成。
节点表示图中的元素而边描述它们之间的关系
在图中元素间的关系不再是父子关系而是一个相关的关系
// 定义图结构体
struct Graph {
int V; // 节点个数
vector<int> *adj; // 指向相邻顶点列表的指针
Graph(int V) {
this->V = V;
adj = new vector<int>[V];
}
void addEdge(int v, int w) { // 添加一条边
adj[v].push_back(w); // 无向图,边为双向,v->w 和 w->v 都需加入 adj 中
adj[w].push_back(v);
}
};
1.1.2 图的类型
在图论中重点讨论无向图和有向图,以及它们的变种:
- 无向图:由节点和无向边组成的图结构,边没有方向,节点间的关系是双向的
- 有向图:由节点和有向边组成的图结构,边有方向,节点间的关系是单向的
- 带权图:除了节点和边之外还有一些权重信息
- 多重图:允许多个节点之间有多条边
// 定义带权图结构体
struct WeightedGraph {
int V; // 节点个数
vector<pair<int, int>> *adj; // pair中的第一个值表示相邻顶点,第二个值表示权重
WeightedGraph(int V) {
this->V = V;
adj = new vector<pair<int, int>>[V];
}
void addEdge(int v, int w, int weight) { // 添加一条带权边
adj[v].push_back(make_pair(w, weight));
adj[w].push_back(make_pair(v, weight)); // 无向图,边为双向,v->w 和 w->v 都需加入 adj 中
}
};
1.2 实现
1.2.1 实现方法
- 邻接矩阵:使用一个二维数组表示节点与边之间的关系可以表示带权图
- 邻接表:使用一个数组+链表的方式表示节点与边之间的关系可以表示带权图
// 用邻接表实现的广度优先遍历算法
void bfs(Graph graph, int start) {
bool *visited = new bool[graph.V]; // 标记节点是否被访问
for (int i = 0; i < graph.V; ++i) {
visited[i] = false;
}
queue<int> q;
visited[start] = true; // 标记起始节点被访问
q.push(start);
while (!q.empty()) {
int curr = q.front();
cout << curr << " "; // 输出访问顺序
q.pop();
for (auto i = graph.adj[curr].begin(); i != graph.adj[curr].end(); ++i) {
if (!visited[*i]) { // 如果该节点未被访问
visited[*i] = true; // 标记该节点被访问
q.push(*i); // 将该节点加入队列中,等待遍历
}
}
}
}
1.2.2 常用算法
- 深度优先遍历(DFS):以深度为优先级,沿着路径遍历,可以通过递归或栈实现
- 广度优先遍历(BFS):以广度为优先级,按照“就近原则”,先遍历与起点直接相邻的节点,再遍历距离起点稍远的节点,可以使用队列实现
- 最短路径算法:解决两个节点之间的最短路径问题
- 最小生成树算法:解决连通图中,权值最小的生成树问题
// 用邻接矩阵实现的深度优先遍历算法
void dfs(int v, bool visited[], int **graph, int size) {
visited[v] = true; // 标记该节点被访问
cout << v << " "; // 输出访问顺序
for (int i = 0; i < size; ++i) {
if (graph[v][i] && !visited[i]) { // 如果该节点未被访问且与 v 有连接
dfs(i, visited, graph, size); // 递归遍历该节点
}
}
}
1.3 应用
图作为一种重要的数据结构在程序中的应用有:
- 最短路径问题:GPS 导航
- 网络问题:路由算法
- 社交网络:朋友推荐
- 游戏策略:国际象棋
- 电路设计:电路布线
五、小结回顾
链表是一种常用的线性数据结构,它可以动态的添加或删除元素并且没有固定大小
链表是由节点组成的每个节点包含一个数据元素和一个指向下一个节点的指针
栈是一种后进先出的数据结构所有元素都在栈顶,可以理解为一种特殊的列表。
栈的基本操作包括入栈和出栈有时会使用压入和弹出这样的类比来描述这些操作。
队列是一种先进先出的数据结构所有元素被放置在队列的末尾并从队列的开头移除。
队列是一种有限制的列表它仅允许在列表的前面进行插入而仅允许在列表的后面进行删除
树是一种非线性数据结构由由节点组成,并且节点之间有特定的关系(如父节点、子节点等)
每个节点可以包含一个数据元素,还可以连接到其他节点。树被广泛应用于各种算法和数据结构中文章来源:https://www.toymoban.com/news/detail-442206.html
图是一种非线性的数据结构由一个或多个节点组成并且节点之间有关联
图是由边和节点组成的每个边连接两个节点
图在计算机科学和算法中被广泛应用,例如网络路由、图像处理、算法设计等。文章来源地址https://www.toymoban.com/news/detail-442206.html
到了这里,关于C++数据结构与算法详解:链表、栈、队列、树、二叉树和图结构的实现与应用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!