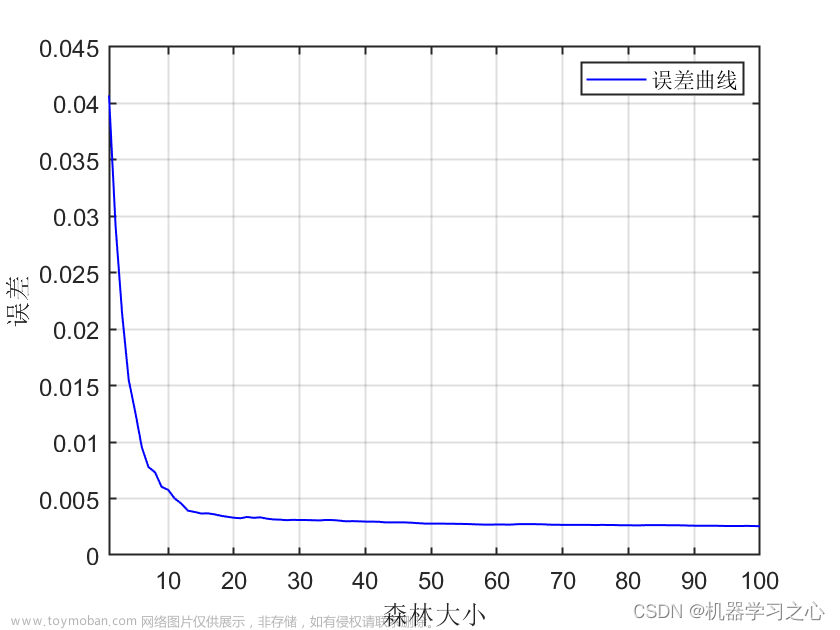
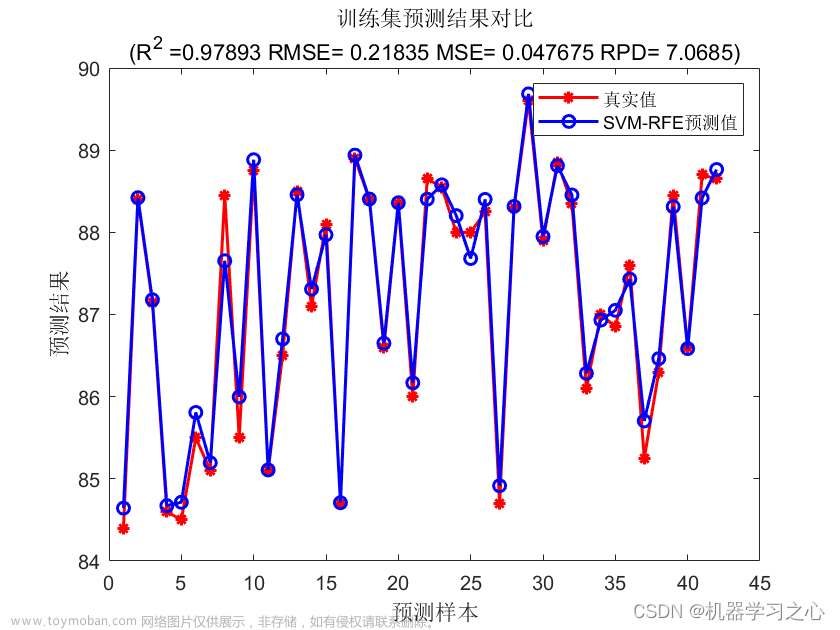
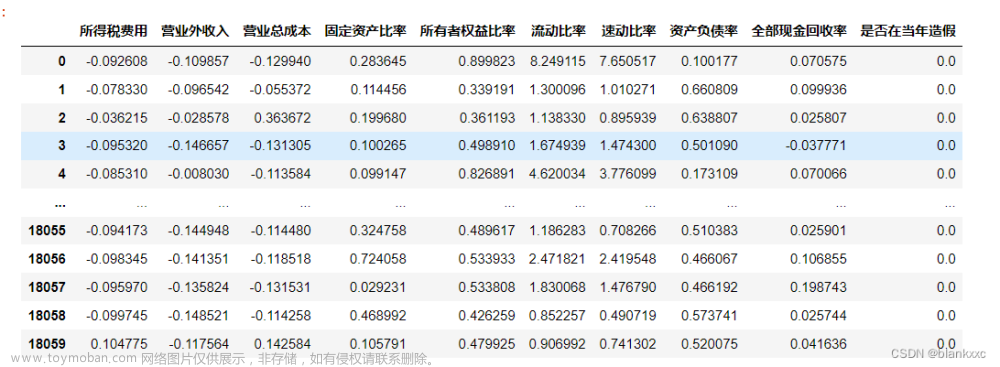
随机森林的REF递归特征消除法是一种基于模型的特征选择方法。它通过构建随机森林模型,并反复训练模型来评估每个特征的重要性,从而递归地消除不重要的特征。REF方法通过以下步骤实现:
1.计算初始模型在所有特征上的特征重要性得分。
2.去掉得分最低的特征,并重新训练模型。
3.重复步骤1和步骤2,直到选择的特征数达到所需的数量或者达到预定义的停止标准。
这种方法的优点是可以在不需要先验知识的情况下对特征进行选择,而且它可以对高维数据集进行有效的特征筛选。此外,REF方法还可以通过交叉验证来评估模型的性能,以避免过拟合。但是,该方法的缺点是计算成本较高,特别是在处理大型数据集时。
总之,REF递归特征消除法是一种可靠的特征选择方法,可以帮助我们从大量的特征中识别出最重要的特征,并提高模型的预测性能。
以下是使用Python中scikit-learn库实现随机森林的REF递归特征消除法的代码示例:
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import RFECV
from sklearn.datasets import make_classification
# 生成一组样本数据
X, y = make_classification(n_samples=1000, n_features=20, n_informative=5, n_redundant=0, random_state=42)
# 定义一个随机森林分类器
clf = RandomForestClassifier(n_estimators=100, random_state=42)
# 定义REF递归特征消除器,使用5折交叉验证
rfecv = RFECV(estimator=clf, step=1, cv=5, scoring='accuracy')
# 运行REF递归特征消除器,并返回选择的特征
selected_features = rfecv.fit_transform(X, y)
# 输出选择的特征数量和选择的特征的索引
print("Selected Features: %d" % rfecv.n_features_)
print("Feature Ranking: %s" % rfecv.ranking_)
在这个示例中,我们首先使用make_classification函数生成了一个包含1000个样本和20个特征的数据集,其中有5个特征对目标变量有信息量。然后我们定义了一个随机森林分类器,以及一个RFECV对象来执行REF递归特征消除。最后,我们将样本数据和目标变量传递给RFECV对象的fit_transform方法,以获得选定的特征。程序输出选择的特征数量和特征排名。
python版本,不依赖模块
import numpy as np
from sklearn.tree import DecisionTreeClassifier
class RandomForestClassifier:
def __init__(self, n_estimators=10, max_depth=None, random_state=None):
self.n_estimators = n_estimators
self.max_depth = max_depth
self.random_state = random_state
self.estimators = []
def fit(self, X, y):
np.random.seed(self.random_state)
n_samples, n_features = X.shape
# 构建随机森林
for i in range(self.n_estimators):
# 从原始数据集中随机抽样,构建一个新的子数据集
sample_indices = np.random.choice(n_samples, n_samples, replace=True)
X_subset, y_subset = X[sample_indices], y[sample_indices]
# 构建决策树模型
tree = DecisionTreeClassifier(max_depth=self.max_depth, random_state=self.random_state)
# 训练决策树模型
tree.fit(X_subset, y_subset)
# 将决策树模型添加到随机森林中
self.estimators.append(tree)
def predict(self, X):
# 预测分类结果
predictions = []
for tree in self.estimators:
predictions.append(tree.predict(X))
return np.mean(predictions, axis=0)
def REF(X, y, n_selected_features):
# 定义一个随机森林分类器
clf = RandomForestClassifier(n_estimators=100, random_state=42)
# 定义一个包含特征索引和得分的列表
feature_scores = []
# 计算每个特征在随机森林模型中的重要性得分
for i in range(X.shape[1]):
# 选择除第i个特征之外的所有特征
X_subset = np.delete(X, i, axis=1)
# 训练随机森林模型并计算特征重要性得分
clf.fit(X_subset, y)
score = clf.estimators[0].feature_importances_
# 将特征得分添加到列表中
feature_scores.append(score)
# 将得分转换为平均得分
feature_scores = np.mean(feature_scores, axis=0)
# 选择前n_selected_features个特征的索引
selected_feature_indices = np.argsort(feature_scores)[::-1][:n_selected_features]
# 返回所选特征的索引
return selected_feature_indices
# 生成一组样本数据
X = np.random.randn(1000, 20)
y = np.random.randint(0, 2, size=1000)
# 使用REF方法选择5个特征
selected_feature_indices = REF(X, y, 5)
# 输出选择的特征的索引
print("Selected Features: %s" % selected_feature_indices)
在这个示例中,我们首先定义了一个自己实现的随机森林分类器,然后定义了一个REF函数来选择最重要的特征。在REF函数的实现基于以下步骤:
1.定义一个随机森林分类器,使用RandomForestClassifier类来实现。
2.定义一个包含特征索引和得分的列表feature_scores。
3.计算每个特征在随机森林模型中的重要性得分。对于每个特征,我们从原始数据集中删除该特征,然后训练随机森林模型并计算特征重要性得分。我们把特征得分添加到feature_scores列表中。
4.将特征得分转换为平均得分,使用np.mean函数实现。
5.选择前n_selected_features个特征的索引,使用np.argsort和[::-1]来实现。
6.返回所选特征的索引。文章来源:https://www.toymoban.com/news/detail-442550.html
在这个示例中,我们使用了numpy和sklearn.tree中的一些函数,但是我们没有使用任何其他外部包来实现REF函数。实现REF函数的核心思想是使用随机森林模型来计算每个特征的重要性得分,然后选择最重要的特征。文章来源地址https://www.toymoban.com/news/detail-442550.html
到了这里,关于随机森林的REF递归特征消除法来筛选特征(python实现不依赖sklearn)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!