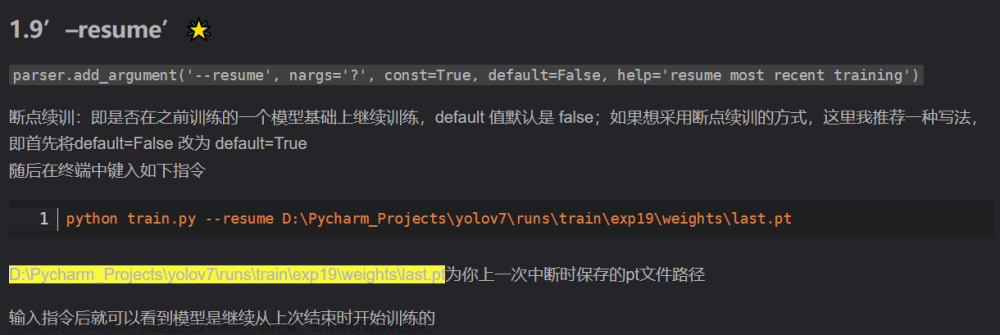
一、问题描述:检测框重复

出现上述问题一般是整体检测方向没错,但conf-thres和iou-thres的参数需要调整。(在默认值0.25和0.45的基础上,提高置信区间,降低iou)
conf-thres:置信度阈值(检测精度,作者是设置的0.25)
iou-thres:做nms的iou阈值
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
二、解决方案:detect、val.py文件手动调参
1、目的:本身conf-thres和iou-thres参数在detect.py文件配置(配置的地方如下图),调好参数开始训练,训练后的结果若大体满意,但细节需要通过调整conf-thres和iou-thres来优化的,可以考虑用训练完的权重进行手动调参。
2、好处:相比在detect.py文件里修改参数再次训练,手动调参可以快速得到结果。
3、理由:因为每次完整训练都要经过300次,cpu机子可能需要花一夜时间来训练,但用训练完的权重来调参可能1分钟不到就出结果了。
三、手动调参的步骤
1 点击edit configuration
2 在弹出来的run/debug configurations界面更改下图的三个地方,
- 改成detect.py文件的位置。
- parameters要填写如下代码
--weights
runs/train/exp10/weights/best.pt //改成你自己权重best.pt对应的文件位置
--data
data/myData2.yaml //改成你自己数据集.yaml对应的文件位置
--source
models/myData2/images/train //改成你自己测试数据集val对应的文件位置
--conf-thres
0.3 //如果检测框重复可以提高置信区间,如从默认的0.25提高到0.3
--iou-thres
0.2 //如果检测框重复可以降低iou,如从默认的0.45降低到0.2
- 点run

3 再次点击edit configuration在弹出来的run/debug configurations界面更改下图的三个地方文章来源:https://www.toymoban.com/news/detail-442838.html
- 改成val.py文件的位置。
- parameters要填写如下代码(注意和上面代码的区别,少了个source)
--weights
runs/train/exp10/weights/best.pt //改成你自己权重best.pt对应的文件位置
--data
data/myData2.yaml //改成你自己数据集.yaml对应的文件位置
--conf-thres
0.3 //如果检测框重复可以提高置信区间,如从默认的0.25提高到0.3
--iou-thres
0.2 //如果检测框重复可以降低iou,如从默认的0.45降低到0.2
- 点run
 文章来源地址https://www.toymoban.com/news/detail-442838.html
文章来源地址https://www.toymoban.com/news/detail-442838.html
到了这里,关于yolov5检测框重合重复,手动调参方法(调整detect,val的conf,iou)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!