😸论文(
CVPR2022 Oral)主要贡献:
- 提出第一个涂鸦标注(scribble-annotated) 的激光雷达语义分割数据集 ScribbleKITTI
- 提出类范围平衡的自训练(class-range-balanced self-training)来应对伪标签对占据主要数量的类和近距离密集区域的偏好(bias)问题
- 通过金字塔局部语义上下文描述子(pyramid local semantic-context descriptor) 来增强输入的点云,从而提高伪标签的质量
- 通过将第
2和3点与 mean teacher 框架结合,论文提出的 pipeline 可在仅使用8%的标注点下实现95.7%的全监督(fully-supervised)性能
😿密集标注(densely annotating)激光雷达点云开销仍然过大,从而无法跟上不断增长的数据量。目前 3D 语义分割的科研工作主要集中在全监督的方法上,而利用弱监督(weak supervision)来实现有效的 3D 语义分割方法尚未被探索。因此,论文提出了使用涂鸦(scribbles)对激光雷达点云进行标注,并发布了第一个用于 3D 语义分割的涂鸦标注(scribble-annotated)数据集 ScribbleKITTI。但这也导致那些包含边缘信息的未标注(unlabeled)点并未被使用,且由于缺乏大量标注点(该方法只使用 8% 的标注点)的数据,影响了具有长尾分布的类置信度(受到的监督减少了),最终使得模型性能有所下降。
😸因此,论文提出了一个用以减少使用这种弱标注(weak annotations)时出现的性能差距的 pipeline,该 pipeline 由三个独立的部分组成,可以与任何 LiDAR 语义分割模型相结合,论文代码采用 Cylinder3D 模型,若对 Cylinder3D 感兴趣可参考我之前的一篇博客。其在只使用 8% 标注的情况下,可达到 95.7% 的全监督性能。
ScribbleKITTI 数据集

🙀使用涂鸦标注在 2D 语义分割中是一种较为流行且有效的方法,但与 2D 图像不同,3D 点云保留了度量(metric)空间,导致其具有高度的几何结构。为了解决这一问题,论文建议使用更几何化的直线涂鸦(line-scribble)来标注激光雷达点云,与 free-formed 涂鸦相比,直线涂鸦可以更快地标注跨越大距离的几何类(如:道路,人行道等),且直线涂鸦只需要知道这些点(某一类的点云)的起始与结束位置。正如上图汽车(蓝色线条)所示,只需确定两点即可完成标注。这将使原先需要花 1.5-4.5 个小时的标注时间减少到 10-25 分钟。
😸ScribbleKITTI 数据集是基于 SemanticKITTI 的 train-split 部分来标注的。其中,SemanticKITTI 的 train-split 部分包含 10 个 sequences、19130 个 scans、2349 百万个点;而 ScribbleKITTI 只包含 189 百万个标注点。
😿如上面 Figure 3 所示,论文中直线涂鸦主要是将 2D 的线条投影到 3D 表面,这会导致在视角改变时直线涂鸦会变得很模糊(indistinguishable)。
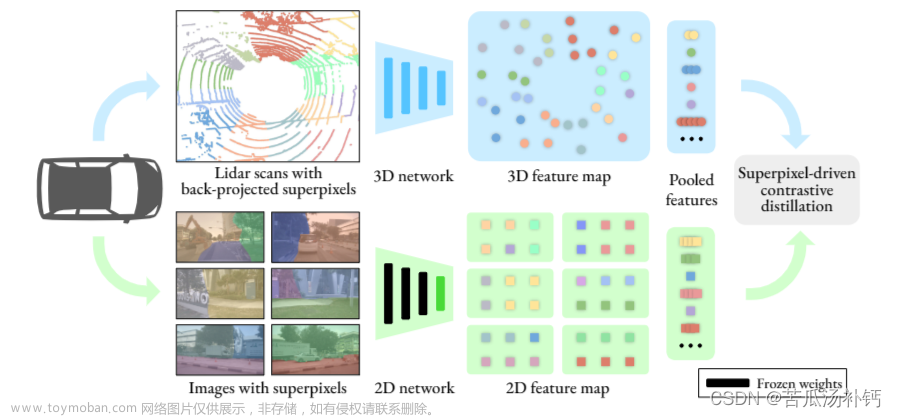
网络结构

- 论文提出的
pipeline可分为training、pseudo-labeling和distillation这三个阶段,这三个阶段紧密联系,提高生成的伪标签质量,从而提高模型的精度 - 在 training 阶段,首先通过 PLS 来对数据进行增强,再训练 mean teacher,这有利于后面生成更高质量的伪标签
- 在 pseudo-labeling 阶段,通过 CRB 来产生目标标签,降低由于点云自身属性降低生成伪标签的质量
- 在 distillation 阶段,通过前面生成的伪标签再对 mean teacher 进行训练
- mean teacher 中 L S L_S LS 和 L U L_U LU 分别对应有标注的点和未标注的点各自的损失
Partial Consistency Loss with Mean Teacher
-
mean teacher框架由 2 部分组成,分别是权值为 θ \theta θ 的学生网络和权值为 θ E M A \theta^{EMA} θEMA 的教师网络。通常,学生网络的权值通过梯度下降获得,而教师网络的权值则由指数加权平均(exponential moving average)学生的权值获得,其计算公式如下:
θ t E M A = α θ t − 1 E M A + ( 1 − α ) θ t \theta_t^{EMA} = \alpha \theta_{t-1}^{EMA} + (1-\alpha)\theta_t θtEMA=αθt−1EMA+(1−α)θt
✍️其中, θ t \theta_t θt 为第 t t t 步中学生网络的权值, θ t E M A \theta_t^{EMA} θtEMA 为第 t t t 步中教师网络的权值, α \alpha α 为平滑系数。通过指数加权平均,可避免 Temporal Ensembling 方法的局限性,且可得到更为精准的模型(相比于直接使用训练的到的权重)
-
partial consistency loss仅将 consistency loss 用在未标注的点上,这样可通过减少教师网络注入(injected)的不确定性来对标注点进行更严格的监督,同时利用更精准的教师网络输出来对未标注点进行监督。其损失函数如下:
min θ ∑ f = 1 F ∑ i = 1 ∣ P f ∣ G i , f = { H ( y ^ f , i ∣ θ , y f , i ) , p f , i ∈ S l o g ( y ^ f , i ∣ θ ) y ^ f , i ∣ θ E M A , p f , i ∈ U \min_{\theta} \sum_{f=1}^{F} \sum_{i=1}^{|P_f|}G_{i, f} = \begin{cases} H(\hat{y}_{f, i}|_{\theta}, y_{f, i}), & p_{f, i} \in S \\ log(\hat{y}_{f, i}|_{\theta})\hat{y}_{f, i}|_{\theta^{EMA}}, & p_{f, i} \in U \end{cases} θminf=1∑Fi=1∑∣Pf∣Gi,f={H(y^f,i∣θ,yf,i),log(y^f,i∣θ)y^f,i∣θEMA,pf,i∈Spf,i∈U
✍️其中,
S
S
S 是有标注的点,
U
U
U 是未标注的点,
H
H
H 是损失函数(通常为 cross-entropy),
F
F
F 为点云帧数,
∣
P
f
∣
|P_f|
∣Pf∣ 为某一帧点的数量,
y
^
f
,
i
∣
θ
\hat{y}_{f, i}|_{\theta}
y^f,i∣θ 为学生网络的预测值,
y
f
,
i
y_{f, i}
yf,i 为真实值,
y
^
f
,
i
∣
θ
E
M
A
\hat{y}_{f, i}|_{\theta^{EMA}}
y^f,i∣θEMA 为教师网络的预测值,
p
f
,
i
p_{f, i}
pf,i 为第 f 帧的第 i 个点
😿尽管 mean teacher 对未标注点进行监督,但由于教师网络性能(performance)的影响,其获取到的信息仍是有限的。即使教师网络正确预测了一个点的标签,但由于软伪标签(soft pseudo-labeling)本身的原因,其他类标签的置信度仍会影响学生网络的输出。
Class-range-balanced Self-training (CRB-ST)
😸为了应对上面所说注入的不确定性并更直接地利用未标注点预测的置信度,论文扩展了标注数据集并使用了 self-training。论文通过将 self-training 与 mean teacher 一起引入,目的是保持 mean teacher 对不确定预测的软伪标签指导(guidance),同时强化某些预测的伪标签。通过使用教师网络中预测出的最大置信度那一类,可为未标注的点生成一组目标标签
L
L
L。
😸由于激光雷达传感器本身的性质,局部点密度随光束半径的变化而变化,稀疏度随距离的增加而增加。这导致伪标签主要从密度较大的区域采样,其估计置信度往往较高。为了减少伪标签生成中的这种问题,论文提出了一种修正的 self-training 方案并与类范围平衡( CRB) 组合使用。论文首先粗略地将横平面划分为以 ego-vehicle 为中心宽度为 B 的 R 个环,每个环点都包含在一定距离范围内的点,从这些点我们可以伪标(pseudo-label)出每个类别的全局最高置信度预测。这确保我们获得可靠的标签,同时在不同的范围和所有类中按比例分布它们。其损失函数如下:
min θ , y ^ ∑ f = 1 F ∑ i = 1 ∣ P f ∣ [ G i , f − ∑ c = 1 C ∑ r = 1 R F i , f , c , r ] F i , f , c , r = { ( l o g ( y ^ f , i ( c ) ∣ θ E M A ) + k ( c , r ) ) y ^ f , i ( c ) , r = ⌊ ∥ ( p x , y ) f , i ∥ / B ⌋ 0 , o t h e r w i s e \begin{aligned} &\min_{\theta, \hat{y}}\sum_{f=1}^{F}\sum_{i=1}^{|P_f|} [G_{i, f} - \sum_{c=1}^C \sum_{r=1}^R F_{i, f, c, r}] \\ & F_{i, f, c, r} = \begin{cases} (log(\hat{y}_{f, i}^{(c)}|_{\theta^{EMA}})+k^{(c, r)})\hat{y}_{f, i}^{(c)}, \quad &r = \lfloor \parallel(p_{x, y})_{f, i} \parallel/B \rfloor \\ 0, & otherwise\end{cases} \end{aligned} θ,y^minf=1∑Fi=1∑∣Pf∣[Gi,f−c=1∑Cr=1∑RFi,f,c,r]Fi,f,c,r={(log(y^f,i(c)∣θEMA)+k(c,r))y^f,i(c),0,r=⌊∥(px,y)f,i∥/B⌋otherwise
✍️其中, k ( c , r ) k^{(c, r)} k(c,r) 是类环(class-annulus)配对的负对数阈值(negative log-threshold), R R R 为环的个数
😸为了求解非线性整数优化(nonlinear integer optimization)问题,论文采用了下面的求解器:
y
^
f
,
i
(
c
)
∗
=
{
1
,
i
f
c
=
a
r
g
m
a
x
y
^
f
,
i
∣
θ
E
M
A
,
y
^
f
,
i
∣
θ
>
e
x
p
(
−
k
(
c
,
r
)
)
w
i
t
h
r
=
⌊
∥
(
p
x
,
y
)
f
,
i
∥
/
B
⌋
0
,
o
t
h
e
r
w
i
s
e
\hat{y}_{f, i}^{(c)*} = \begin{cases} 1, if &c= argmax\hat{y}_{f, i}|_{\theta^{EMA}},\\ &\hat{y}_{f, i}|_{\theta} \gt exp(-k^{(c, r)}) \\ &with \ r = \lfloor \parallel (p_{x, y})_{f, i} \parallel / B \rfloor\\ 0, &otherwise\end{cases}
y^f,i(c)∗=⎩
⎨
⎧1,if0,c=argmaxy^f,i∣θEMA,y^f,i∣θ>exp(−k(c,r))with r=⌊∥(px,y)f,i∥/B⌋otherwise
Pyramid Local Semantic-context (PLS)
😸为了保证更高质量的伪标记,论文进一步引入一个新的描述子(descriptor),其利用可用的涂鸦(scribbles)来丰富(enrich)初始点的特征。
🙀论文发现类标签在 3D 空间中存在空间平滑(spatial smoothness)约束和语义模式(semantic pattern)约束,空间平滑约束指空间中的一个点可能至少与其相邻的一个点具有相同的类标签,而语义模式约束指支配类之间空间关系的一套复杂的高级规则(high-level rules)。因此,论文认为可以使用局部语义先验(local semantic prior)作为丰富的点描述子(rich point descriptor)来封装空间平滑约束和语义模式约束,且提出在缩放分辨率(scaling resolutions)下使用局部语义上下文(semantic-context)来减少标注点和未标注点(labeled-unlabeled point)之间传播信息的歧义并提高生成伪标签的质量。
😸论文最初将空间离散为粗略的体素(coarse voxels),这一步可避免过度描述(over-descriptive)的特征导致网络在涂鸦标注下过拟合,从而使其泛化能力和理解有意义的几何关系的能力更强。为了在不同分辨率下符合激光雷达传感器的固有点分布,我们在柱坐标系中使用了多种尺寸的 bins,对于每个 bin
b
i
b_i
bi 再计算一个粗略的直方图,然后再将这些 normalized 直方图拼接在一起(如上面 Figure 6 所示),其计算公式如下:
h
i
=
[
h
i
(
1
)
,
⋯
,
h
i
(
C
)
]
∈
R
C
h
i
(
c
)
=
#
{
y
j
=
c
∀
j
∣
p
j
∈
b
i
}
P
L
S
=
[
h
i
1
/
m
a
x
(
h
i
1
)
,
⋯
,
h
i
s
/
m
a
x
(
h
i
s
)
]
∈
R
s
C
\begin{aligned} \pmb{h}_i &= [h_i^{(1)}, \cdots, h_i^{(C)}] \in R^C \\ h_i^{(c)} &= \#\{y_j = c \forall j | p_j \in b_i \} \\ \pmb{PLS} &= [\pmb{h}_i^1/max(\pmb{h}_i^1), \cdots, \pmb{h}_i^s/max(\pmb{h}_i^s)] \in R^{sC} \end{aligned}
hhihi(c)PLSPLS=[hi(1),⋯,hi(C)]∈RC=#{yj=c∀j∣pj∈bi}=[hhi1/max(hhi1),⋯,hhis/max(hhis)]∈RsC
✍️其中, h i \pmb{h}_i hhi 是某一分辨率下所有直方图拼接在一起的结果, h i ( c ) h_i^{(c)} hi(c) 是某一类的直方图, P L S PLS PLS 是所有分辨率下所有 normalized 直方图拼接一起的结果, s s s 指分辨率?
✍️将
P
L
S
PLS
PLS 添加到输入的特征中,并将输入的激光雷达点云重新定义为点的增广集
P
a
u
g
=
{
p
∣
p
=
(
x
,
y
,
z
,
I
,
P
L
S
)
∈
R
s
C
}
P_{aug} = \{p|p=(x, y, z, I, PLS) \in R^{sC}\}
Paug={p∣p=(x,y,z,I,PLS)∈RsC},
x
,
y
,
z
x, y, z
x,y,z 对应点 3D 坐标,而
I
I
I 为反射强度。在训练时,使用
P
a
u
g
P_{aug}
Paug 来代替原先数据集可在 pseudo-labeling 阶段生成更高质量的伪标签。
😻论文:https://arxiv.org/pdf/2203.08537.pdf
😻代码:https://github.com/ouenal/scribblekitti文章来源:https://www.toymoban.com/news/detail-442947.html
📖补充:深度学习(七十四)半监督Mean teachers、半监督学习之self-training文章来源地址https://www.toymoban.com/news/detail-442947.html
到了这里,关于3D 语义分割——Scribble-Supervised LiDAR Semantic Segmentation的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!