英杰社区https://bbs.csdn.net/topics/617804998
导读
OpenAI最近发布了一款名为ChatGPT的聊天机器人模型,它受到了广泛的关注和赞誉。ChatGPT以一种更贴近人类对话方式进行交互,可以回答问题、承认错误、挑战不正确的前提、拒绝不适当的请求等。它提供高质量的回答,并且与用户的交流具有上瘾性,让人沉浸其中。这款模型引起了圈内外的人们的惊叹和兴趣。
ChatGPT是什么?
ChatGPT是一种基于大型预训练模型的强大对话生成器。它采用了Transformer架构,通过在海量数据上进行训练,能够生成自然流畅的对话回复。ChatGPT可以应用于智能客服、聊天机器人、问答系统等场景,为用户提供实时的对话交互服务。它能理解输入的文本,并生成与之相关的有意义的回复。
简介
ChatGPT是一种基于大型预训练模型的强大对话生成器。它基于通用语言模型(GLM)和ChatGLM等国内开源大模型,并训练于海量中文数据,旨在实现自然流畅的对话交互。
模型架构
ChatGPT采用了基于Transformer的架构,这是一种深度学习中常用的序列到序列模型。它包含多个编码器层和解码器层,以及自注意力机制,使其能够有效地捕捉输入序列之间的依赖关系。
import torch
import torch.nn as nn
from transformers import ChatGPTModel, ChatGPTTokenizer
# 初始化模型和分词器
model = ChatGPTModel.from_pretrained("binjie09/ChatGPT")
tokenizer = ChatGPTTokenizer.from_pretrained("binjie09/ChatGPT")
# 编码器输入
inputs = tokenizer.encode("你好,我有一个问题...")
inputs = torch.tensor(inputs).unsqueeze(0) # 添加批处理维度
# 解码器输出
outputs = model.generate(inputs, max_length=50)
decoded_outputs = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded_outputs)
训练数据
ChatGPT的训练数据来源于多个领域的中文对话文本,包括社交媒体、电子邮件、新闻、维基百科等。这些数据经过处理和清洗,以确保模型能够学习到准确、通用的语言知识。
注意事项
-
虽然ChatGPT在许多情况下能够提供有用的回答,但它并不拥有实际的理解能力。因此,在与ChatGPT进行对话时,应谨慎对待其输出结果,并避免将其视为完全准确或可信赖的。
-
ChatGPT的回答受限于其训练数据,如果问题涉及专业或高度技术性的领域,建议寻求相关专家的意见。
-
考虑到ChatGPT的庞大参数量和计算资源需求,建议在强大的GPU设备上运行模型训练或推理。
ChatGPT一些有趣的体验
作为一个聊天机器人,我们体验发现相比传统的机器人在连贯性问答中更加流畅自然。微信上已经有很多的小程序可以体验,或者直接讲ChatGPT接入了微信中,下面体验一下已经接入到企业微信的ChatGPT。
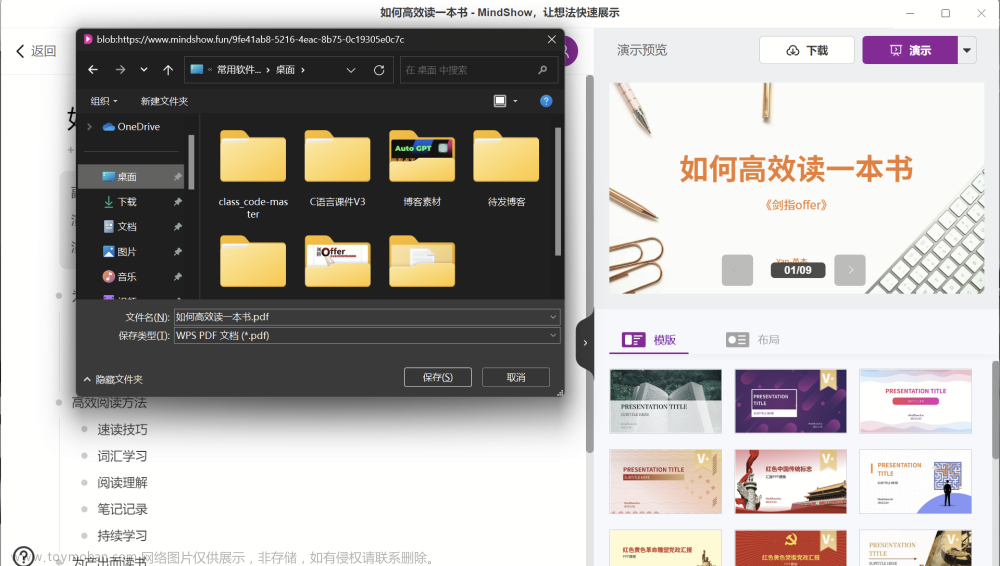
1. ChatGPT可在三分钟内生成PPT
我之前写过的文章,可以利用ChatGPT在三分钟内生成PPT
【ChatGPT】ChatGPT+MindShow三分钟生成PPT
 文章来源:https://www.toymoban.com/news/detail-443023.html
文章来源:https://www.toymoban.com/news/detail-443023.html
结论
通过使用ChatGPT,我们可以构建一个功能强大的中文对话生成系统,为用户提供智能化的问答交互服务。然而,在使用ChatGPT时仍需谨慎,将其作为辅助工具,并结合其他信息来源进行判断和决策。文章来源地址https://www.toymoban.com/news/detail-443023.html
到了这里,关于【ChatGPT】ChatGPT国内镜像网站集合的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!