一、硬件准备
(一)集群配置
本次利用云服务器搭建Hadoop集群, 在开始之前,你需要3台云服务器,可以在同一家购买也可以在不同家购买。此次教程采用百度云产品,可以换不同账号新手免费试用几个月,具体配置如下:
| 服务器名称 | 配置 | 磁盘容量 |
|---|---|---|
| master | 2cpu 内存4GB | 40G |
| slave1 | 1cpu 内存2GB | 60G |
| slave2 | 1cpu 内存2GB | 60G |
(二)集群规划
| 服务器IP | 180.76.231.240 | 180.76.53.4 | 106.12.160.115 |
|---|---|---|---|
| 主机名 | master | slave1 | slave2 |
| NameNode | 是 | 否 | 否 |
| SecondaryManager | 是 | 否 | 否 |
| DateNode | 是 | 是 | 是 |
| RecourceManager | 是 | 否 | 否 |
| Nodemanager | 是 | 是 | 是 |
(三)Hadoop、Zookeeper、Java、CentOS版本
| Hadoop | Zookeeper | Java | CentOS |
|---|---|---|---|
| 2.7.7 | 3.4.14 | 1.8.0_171 | 8.4 x86_64(64bit) |
二、基础环境配置
(一)关闭防火墙
systemctl stop firewalld
systemctl status firewalld

(二)修改主机名
hostnamectl set-hostname master
hostname
(三)主机映射
3个虚拟机均需要修改hosts文件
vi /etc/hosts

使其生效
source /etc/hosts
注意,因为是云服务器,会有两个ip,一个是内网IP,一个是外网IP,我们在设置hosts时,对于要设置的服务器,IP为内网,而对于其他服务器,要设置外网IP。
测试三台机器,是否ping通
ping master

ping slave1

ping slave2

(四)时间同步
1.查看主机时间
date
2.选择时区
tzselect
echo "TZ='Asia/Shanghai'; export TZ" >> /etc/profile && source /etc/profile
3.时间同步协议NTP
yum install -y ntp//三台机器安装ntp
master作为ntp服务器,修改ntp配置文件
vim /etc/ntp.conf//master执行
屏蔽掉默认的server,设置master作为时钟源,设置时间服务器的层级为10。
#注释掉server 0 ~ n,新增
server 127.127.1.0
fudge 127.127.1.0 stratum 10
重启ntp服务(master上执行)
/bin/systemctl restart ntpd.service
slave1,slave2操作
ntpdate master
(五)定时任务crontab
crontab -e
输入i,添加定时任务
*/30 8-17 * * */usr/sbin/ntpdate master //早8晚五时间段每隔半个小时同步
*/10 * * * */usr/sbin/ntpdate master //每隔10分钟同步一次
*/30 10-17 * * */usr/sbin/ntpdate master //早十晚五时间段每隔半个小时同步
查看定时任务列表
crontab –l
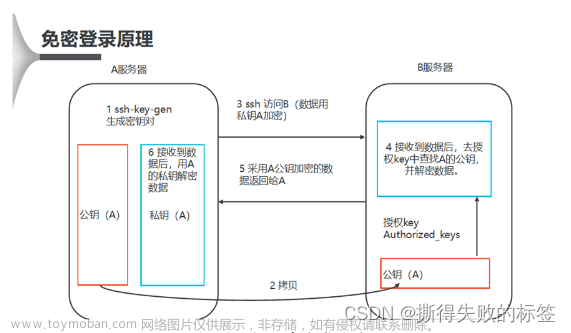
(六)配置ssh免密
生成公钥和私钥:
ssh-keygen -t rsa //三台都要

连续按3次Enter键,会在当前用户家目录下生成隐藏目录.ssh,里面包含私钥id_rsa和公钥id_rsa.pub
将公钥复制到要免密登录的服务器上:ssh-copy-id 服务器名
ssh-copy-id master
ssh-copy-id slave1

ssh-copy-id slave2

会让你确认是否要连接,输入yes
再输入对方主机的密码即可。在这里,我选择将各台服务器都相互免密登录,大家在实际过程中可按需求选择要免密的主机。
验证免密效果,分别测试免密效果:ssh 想要登录的主机名
ssh master

ssh slave1

ssh slave2

退出:
exit
三、安装jdk
在官网下载好相关文件,利用xftp传入主机
(一)创建安装目录和软件包存放目录
创建文件夹
在主机master先创建两个文件夹:/opt/module 和/opt/softs,我所有软件都安装在/opt/module下,软件安装包均放在/opt/softs下,命令为:
mkdir /opt/module/
mkdir /opt/softs/
利用xftp连接上传相关软件到/opt/softs
解压至/opt/module
tar -zxvf jdk-8u171-linux-x64.tar.gz
‐C /opt/modle/
将文件传入主机slave1和slave2
scp -r /opt/softs slave1:/opt/softs
scp -r /opt/softs slave2:/opt/softs
scp -r /opt/module slave1:/opt/module
scp -r /opt/module slave2:/opt/module
(二)修改环境变量
vi /etc/profile
添加内容如下:
export JAVA_HOME=/opt/module/jdk1.8.0_171
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
使其生效:
source /etc/profile
删除slave1和slave2的/etc/profile文件:
rm -rf /etc/profile
将文件传入主机slave1和slave2
scp -r /etc/profile slave1:/etc/profile
scp -r /etc/profile slave2:/etc/profile
(三)查看java版本,确认安装成功:
java -version

四、Zookeeper安装
(一)安装Zookeeper
tar -zxvf zookeeper-3.4.14.tar.gz -C /opt/module/
(二)配置系统环境变量
vi /etc/profile
添加如下信息
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.4.14
export PATH=$ZOOKEEPER_HOME/bin:$PATH
使得配置的环境变量生效:
source /etc/profile
修改配置文件
进入zookeeper的安装目录下的 conf目录 ,拷贝配置样本并进行修改:
cd /opt/module/zookeeper-3.4.14/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
修改dataDir,增加dataLogDir如下:
dataDir=/opt/module/zookeeper-3.4.14/zookeeper-cluster/data
dataLogDir=/opt/module/zookeeper-3.4.14/zookeeper-cluster/log
#server.1 这个1是服务器的标识,可以是任意有效数字,标识这是第几个服务器节点,这个标识要写到dataDir目录下面myid文件里
server.1=sleve1:2777:3888
server.2=sleve2:2777:3888
server.3=master:2777:3888

(三)标识节点
分别在三台主机的 dataDir 目录下新建 myid 文件:
mkdir -vp /opt/module/zookeeper-3.4.14/zookeeper-cluster/data/
写入对应的节点标识。Zookeeper 集群通过 myid 文件识别集群节点,并通过上文配置的节点通信端口和选举端口来进行节点通信,选举出 Leader 节点。
slave1上执行
echo "1" > /opt/module/zookeeper-3.4.14/zookeeper-cluster/data/myid
slave2上执行
echo "2" > /opt/module/zookeeper-3.4.14/zookeeper-cluster/data/myid
master上执行
echo "3" > /opt/module/zookeeper-3.4.14/zookeeper-cluster/data/myid
(四)启动集群
进入各台服务器${ZOOKEEPER_HOME}/bin,然后执行zkServer.sh start 启动集群,并用zkServer.sh status查看状态:(这里也可以不进入bin目录启动因为在/etc/profile设置了系统环境变量,但是如果每次在不同目录下启动每次启动会生成一个启动日记文件:zookeeper.out文件,zookeeper.out也可以用来查看启动时的错误)
cd $ZOOKEEPER_HOME/bin
查看当前目录:
pwd

zkServer.sh start
zkServer.sh status



常见问题解决措施:
1 检查是否创建data目录
2 检查conf/zoo.cfg文件中是否配置了正确的数据缓存路径(data文件夹位置)
3 检查data中是否创建了myid文件,其内容是否正确如果myid文件中的数字不和zoo.cfg中的数字对应,也会造成错误!
4 检查conf/zoo.cfg文件中是否配置了服务/投票/选举端口,形式为:
server.x(x为myid中的id)=ip地址:端口号:端口号
举例:
server.1=192.168.70.143:2881:3881
5 是否关闭了防火墙(需要关闭,或者开放相关端口)
6 检查data目录下是否有*.pid文件,若有将其全部删除
7 端口占用:
netstat -nltp | grep 2181//查看指定端口
jps//查看java进程端口
kill -9 37884// 彻底杀死进程
8.主机映射问题,在配置zoo.cfg时最好是直接写ip地址,不写主机名称
9.启动顺序,需要按配置文件启动具体错误查看zookeeper.out文件
五、Hadoop安装
进入/opt/softs/目录:
cd /opt/softs/
安装hadoop:
tar -zxvf hadoop-2.7.7.tar.gz -C /opt/module//表示将hadoop安装到/opt/module/
配置系统环境变量:
vim /etc/profile
添加如下信息
export HADOOP_HOME=/opt/module/hadoop-2.7.7
export PATH=$PATH:${HADOOP_HOME}/bin
export PATH=$PATH:${HADOOP_HOME}/sbin//可选,这里导入后面可以不进入sbin目录启动服务
使得配置的环境变量生效:
source /etc/profile
进入 ${HADOOP_HOME}/etc/hadoop 目录下,修改几个配置文件:
cd ${HADOOP_HOME}/etc/hadoop

(一)修改hadoop-env.sh
指定JDK的安装位置
export JAVA_HOME=/opt/module/jdk1.8.0_171

(二)修改yarn-env.sh
进入${HADOOP_HOME}/etc/hadoop下配置:
cd ${HADOOP_HOME}/etc/hadoop
vim yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_171

(三)修改主要配置
由于其方便性,这里使用notepad++修改
除了直接在文档修改,我们还可以利用notepad++的插件通过FTP实现远程编辑项目的文档。采用这个方法虽然一次只能编辑一个文档。
notepad++是一款开源免费软件,到处都有得下载
安装NppFTP插件
选择 「插件」 --> 「Plugin Manager」 --> 「Show Plugin Manager」,在弹出的窗口中找到 「NppFTP」 ,打上勾并点击 「Install」,之后一路「Yes」 就可以了。
安装完毕之后,在 「插件」 菜单中即可看到 「NppFTP」 。我们也可以将这个插件以窗口的形式显示在主窗口侧边。
选择 「插件」 --> 「NppFTP」 --> 「Show NppFTP Window」
下面就可以通过Notepad++的NppFTP插件来连接虚拟机了。点击NppFTP插件栏的小齿轮选择 「profile settings」:
在「profile settings」 里,点击 「add new」 创建一个新的连接,然后右侧填入相应的信息,再点击 「close」 退出。
点击NppFTP插件栏左侧的闪电那个图标,选择刚刚创建的连接,即可连接到虚拟机。之后再打开需要编辑的文档就可以尽情的玩耍了。
进入/opt/module/hadoop-2.7.7/etc/hadoop目录

1.修改core-site.xml
<configuration>
<property>
<!-- 指定 namenode 的 hdfs 协议文件系统的通信地址 -->
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<!-- 指定 hadoop 集群存储临时文件的目录 -->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
<property>
<!-- ZooKeeper 集群的地址 -->
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<property>
<!-- ZKFC 连接到 ZooKeeper 超时时长 -->
<name>ha.zookeeper.session-timeout.ms</name>
<value>10000</value>
</property>
</configuration>
若中文出现乱码现象,点击[编码],使用UTF-8编码
2.修改hdfs-site.xml
<configuration>
<property>
<!-- 指定 HDFS 副本的数量 -->
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<!-- namenode 节点数据(即元数据)的存放位置,可以指定多个目录实现容错,多个目录用逗号分隔 -->
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/namenode/data</value>
</property>
<property>
<!-- datanode 节点数据(即数据块)的存放位置 -->
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/datanode/data</value>
</property>
<property>
<!-- 集群服务的逻辑名称 -->
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<!-- 块的大小(128M),下面的单位是字节-->
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<property>
<!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<property>
<!-- secondarynamenode守护进程的http通信地址:主机名和端口号。参考守护进程布局-->
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<!-- NameNode 元数据在 JournalNode 上的共享存储目录 -->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485/mycluster</value>
</property>
<property>
<!-- Journal Edit Files 的存储目录 -->
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/journalnode/data</value>
</property>
<property>
<!-- 配置隔离机制,确保在任何给定时间只有一个 NameNode 处于活动状态 -->
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<!-- 使用 sshfence 机制时需要 ssh 免密登录 -->
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<!-- SSH 超时时间 -->
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<!-- 访问代理类,用于确定当前处于 Active 状态的 NameNode -->
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!-- 开启故障自动转移 -->
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
3.修改yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<!--配置 NodeManager 上运行的附属服务。需要配置成 mapreduce_shuffle 后才可以在Yarn 上运行 MapReduce 程序。-->
<!-- 指定yarn的shuffle技术-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!-- 是否启用日志聚合 (可选) -->
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<!-- 聚合日志的保存时间 (可选) -->
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<property>
<!-- 启用 RM HA -->
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<!-- RM 集群标识 -->
<name>yarn.resourcemanager.cluster-id</name>
<value>my-yarn-cluster</value>
</property>
<property>
<!-- 指定resourcemanager的主机名-->
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<!--配置resourcemanager的内部通讯地址-->
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<!--配置resourcemanager的scheduler的内部通讯地址-->
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<!--配置resoucemanager的资源调度的内部通讯地址-->
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<!--配置resourcemanager的管理员的内部通讯地址-->
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<!--配置resourcemanager的web ui 的监控页面-->
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<!-- ZooKeeper 集群的地址 -->
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<property>
<!-- 启用自动恢复 -->
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<!-- 用于进行持久化存储的类 -->
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
4.修改mapred-site.xml
生成mapred-site.xml:
cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<!-- 指定mapreduce使用yarn资源管理器-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<!-- 配置作业历史服务器的地址-->
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<!-- 配置作业历史服务器的http地址-->
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
5.修改slaves
配置所有节点的主机名或 IP 地址,每行一个,所有从属节点上的 DataNode 服务和NodeManager 服务都会被启动。
master
slave1
slave2

再将slave1和slave2的文件修改
六、启动集群
(一)启动Zookeeper
启动集群之前需要先启动zookeeper
cd $ZOOKEEPER_HOME/bin
zkServer.sh start
zkServer.sh status
(二)初始化NameNode
首先进入${HADOOP_HOME}/sbin
cd ${HADOOP_HOME}/sbin//若前面导入环境变量,可不用进入
在namenode节点上初始化集群,在master上进行,命令为:
hdfs namenode -format
(三)初始化HA状态
在namenode节点上初始化集群,在master上进行,命令为:
hdfs zkfc -formatZK
(四)启动HDFS
在namenode节点上初始化集群。进入master的 ${HADOOP_HOME}/sbin (若前面导入环境变量无需进入)目录下,启动 HDFS。此时 master 和的 NameNode 服务和3台服务器上的 DataNode 服务都会被启动:
./start-dfs.sh
start-dfs.sh//若前面导入环境变量可直接用这个命令
(五)启动YARN
在namenode节点上初始化集群。进入到 master 的${HADOOP_HOME}/bin 目录下,启动 YARN。此时 master上的ResourceManager 服务和3台服务器上的 NodeManager 服务都会被启动:
./start-yarn.sh
start-yarn.sh//若前面导入环境变量可直接用这个命令
(六)查看集群
1.启动HDFS查看集群
通过在每台机器上输入命令:
jps
查看集群各服务开启情况。如下图,发现所有服务正常开启。



访问:http://180.76.231.240:50070/
2.启动YARN后查看集群



访问:http://180.76.231.240:8088/
(七)跑一个wordcount 案例
需求:在一堆给定的文本文件中统计输出每一个单词出现的总次数
数据准备:wc.input
hadoop yarn
hadoop mapreduce
atguigu
atguigu
创建在hadoop-2.7.7文件下面创建一个wcinput文件夹
[root@master hadoop-2.7.7]$ mkdir wcinput
在wcinput文件下创建一个wc.input文件
[root@master hadoop-2.7.7]$ cd wcinput
[root@master hadoop-2.7.7]$ touch wc.input
编辑wc.input文件
[root@master hadoop-2.7.7]$ vi wc.input#输入一下内容
hadoop yarn
hadoop mapreduce
atguigu
atguigu
:wq #保存退出
回到Hadoop目录/opt/module/hadoop-2.7.7
执行程序
[root@master hadoop-2.7.7]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount wcinput wcoutput
查看结果
[root@master hadoop-2.7.7]$ cat wcoutput/part-r-00000
atguigu 2
hadoop 2
mapreduce 1
yarn 1
七、问题汇总
(一)虚拟机上不了网
解决方法
-
使用ping 命令ping网关是否能通
- 能通则进行下一步,不通则说明虚拟网络编辑器中的网关和虚拟机网关配置不一致或者网络没有设置为 自动连接
-
使用ping 命令ping www.baidu.com是否能通
- 不通说明网关或者IP地址,或者DNS配置错误
-
终极解决方法:查看虚拟网络编辑器中的网关和子网掩码是否和虚拟机中配置的网络的网关和子网掩码 一致,另外还要查看DNS是否配置正确,再查看IP段是否配置正确。
+ 如果全部正确就说明网卡服务或者 网络适配器有问题,对应服务重启或者重置再修改即可。
(二)命令不可用
- 大多数命令变为不可用,说明 /etc/profile 文件中的 PATH 环境变量配置有误。进入到 /usr/bin 目 录,使用 vi 编辑 /etc/profile 文件,重新修改 PATH 环境变量即可。
(三)Hadoop格式化出错
- 格式化出错一般是由于配置文件有误引起的,查看错误信息,根据错误信息提示修改即可。一般错误信 息上都会提示有哪个配置文件的哪一行哪一列有误。
(四)Windows 主机无法通过IP地址访问HDFS
- 防火墙未关闭或者使用的是传统的Edge浏览器,那么请关闭虚拟机所有节点的防火墙,并使用谷歌浏览 器
(五)Hadoop启动报错
-
通过 tail -100 /opt/apps/hadoop-3.1.4/logs/hadoop-root-datanode-node01.log 查看日志信 息
-
注意: 如果是 namenode 未启动,则查看 hadoop-root-namenode-node01.log 如果是 datanode 未 启动,则查看 hadoop-root-datanode-node01.log ,哪个节点上的这个没启动就查看哪个节点上的日 志文件信息
-
如果是 resourceManager 未启动,则查看 hadoop-root-resourcemanager-node02.log 如果是 NodeManager 未启动,则查看 hadoop-root-nodemanager-node02.log
-
注意:格式化只能格式化一次,如果多次格式化,则删除 Hadoop 目录下的 dfs 目录,然后重新格式化即可
八、本地eclipse连接集群
说明:云服务器上提供Hadoop集群,本地客户端只需要解压⼯具、安装插件,即可连接集群,提交任 务到集群
(一)工具说明
由于Eclipse不同版本之间和Hadoop对应插件的兼容性并不是很好,不推荐下载最新的Eclipse。

Eclipse下载版本参考(Java EE 2019-12)如下,请结合⾃⼰的系统进⾏下载。
(二)插件安装
1)本次使⽤的安装包为Hadoop2.7.7,因此对应的插件为 hadoop-eclipse-plugin-2.7.7.jar ,放在 eclipse安装包下的plugins⽬录下,也可以直接放在dropins⽬录下(较为便捷)。
2)解压Hadoop安装包 选择⼀个路径解压缩hadoop-2.7.7.tar.gz,在eclipse的Windows->Preferences的Hadoop Map/Reduce中设置对应的安装⽬录(仅做解压,不做修改)

3)打开Windows->Perspective->Open Perspective-> Other 中的Map/Reduce,在此perspective下 进⾏hadoop程序开发。 打开Windows->Show View->Other -> MapReduce Tools中的Map/Reduce Locations,添加Hadoop 视图
4)右键选择New Hadoop location…新建hadoop连接

5)确认完成以后如下,eclipse会连接hadoop集群。

(三)配置⽂件log4j.properties
打印出在linux下hadoop的⽇志信息,便于差错,进⾏代码修改,在项⽬的src⽬录下,新建⼀个⽂件 new->other->general->file,命名为“log4j.properties”即可。
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
执⾏程序,打印⽇志:

(四)执⾏程序Run on Hadoop

(五)拓展:本地集群运⾏模式
客户端本地搭建Hadoop集群,提交任务到本地集群。这⾥就需要本地的Hadoop去执⾏程序了。
对⽐以上步骤2.2如要进⾏以下修改:
-
选择⼀个路径解压Hadoop-2.7.7.tart.gz,推荐解压⾄C盘下,同时添加环境变 量%HADOOP_HOME%。
-
另外为了防⽌报错,将百度云中⽂件hadoop.dll和winutils放置在C盘hadoop安装包的bin⽬录下。如 果Hadoop没有安装在C盘下,则需要将两个⽂件存放⾄C://windows/system32/⽬录下文章来源:https://www.toymoban.com/news/detail-443180.html
-
也可以浏览器访问https://github.com/dafuu123/winutils,进⼊对应版本⽂件下载全部内容直接替换 bin⽬录下所有内容,或者将winutils和hadoop.dll⽂件拿出来放到bin⽬录下。文章来源地址https://www.toymoban.com/news/detail-443180.html
九、Eclipse连接Hadoop
1 # 查看测试文本
2 [root@master ~]# cat workspace/TestMapReduceAPI/src/MapReduce/Word.txt
3 The ASF provides an established framework
4 for intellectual property and financial
5 contributions that simultaneously limits
6 potential legal exposure for
7 our project committers
8 The ASF provides an established framework
9 for intellectual property and financial
10 contributions that simultaneously limits
11 potential legal exposure for
12 our project committers
13 # Mapper
14 package MapReduce;
15 import java.io.IOException;
16 import org.apache.hadoop.io.LongWritable;
17 import org.apache.hadoop.io.Text;
18 import org.apache.hadoop.mapreduce.Mapper;
19 public class WordCountMapper extends Mapper<LongWritable , Text , Text ,
LongWritable> {
20 @Override
21 protected void map(LongWritable key,Text value, Mapper<LongWritable, Te
xt, Text, LongWritable>.Context context) throws IOException,InterruptedExce
ption{
22 // 接收数据,分割数据,循环计数
23 String valueString = value.toString();
24 String wArr[] = valueString.split("");
25 for (int i=0;i<wArr.length;i++) {
26 context.write(new Text(wArr[i]),new LongWritable(1));
27 }
28 }
29 }
30
31 # Reducer
32 package MapReduce;
33 import java.io.IOException;
34 import java.util.Iterator;
35 import org.apache.hadoop.io.LongWritable;
36 import org.apache.hadoop.io.Text;
37 import org.apache.hadoop.mapreduce.Reducer;
38 public class WordCountReducer extends Reducer<Text ,LongWritable , Text
, LongWritable> {
39 @Override
40 protected void reduce(Text key ,Iterable<LongWritable>
v2s,Reducer<Text,LongWritable, Text, LongWritable>.Context context)throws I
OException,InterruptedException{
41 Iterator<LongWritable> it = v2s.iterator();
42 long sum = 0;
43 while (it.hasNext()) {
44 sum += it.next().get();
45 }
46 context.write(key,new LongWritable(sum));
47 }
48 }
49
50 #
51 package MapReduce;
52 import org.apache.hadoop.conf.Configuration;
53 import org.apache.hadoop.fs.Path;
54 import org.apache.hadoop.io.LongWritable;
55 import org.apache.hadoop.io.Text;
56 import org.apache.hadoop.mapreduce.Job;
57 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
58 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
59 public class WordCountTest {
60 public static void main(String[] args) throws Exception {
61 Configuration conf = new Configuration();
62 Job job=Job.getInstance(conf);
63 job.setJarByClass(WordCountTest.class);
64 job.setMapperClass(WordCountMapper.class);
65 job.setReducerClass(WordCountReducer.class);
66 job.setMapOutputKeyClass(Text.class);
67 job.setMapOutputValueClass(LongWritable.class);
68 job.setOutputKeyClass(Text.class);
69 job.setOutputValueClass(LongWritable.class);
70 FileInputFormat.setInputPaths(job, new Path("file:///root/workspace/Tes
tMapReduceAPI/src/MapReduce/Word.txt"));
71 FileOutputFormat.setOutputPath(job, new Path("hdfs://180.76.231.240:900
0/output2"));
72 job.waitForCompletion(true);
73 }
74 }
到了这里,关于用三台云服务器搭建hadoop完全分布式集群的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!