在网上溜了一圈,发现使用微软语音服务(Azure)的文章好少,为之感叹,在国内,百度语音、讯飞语音算是前沿语音技术,使用的公司和人自然不少,不过,在国际语言,小语种这块,还需要努力。刚开始,我也想使用百度语音翻译来着,后面发现集成好麻烦,API请求参数看懵逼了,不要友好,讯飞语音也想要集成了,看了一些demo,仔看看价格,和百度差不多,一直没动手集成,直到后面看到网上说白嫖微软语音合成文章后,大为受惊,操作一番,确实可以哈!一只白嫖一时爽,连续白嫖两周后,啊哈!网站上直接没有体验的入口了,就在不久前,也就是3月16号,俺一看,傻眼了,没了。
好吧!使用两周,感觉语音合成听着挺逼真的,那就注册一个账号,搞起来吧!至于费用什么的,后面再说。
一:注册一个微软账号
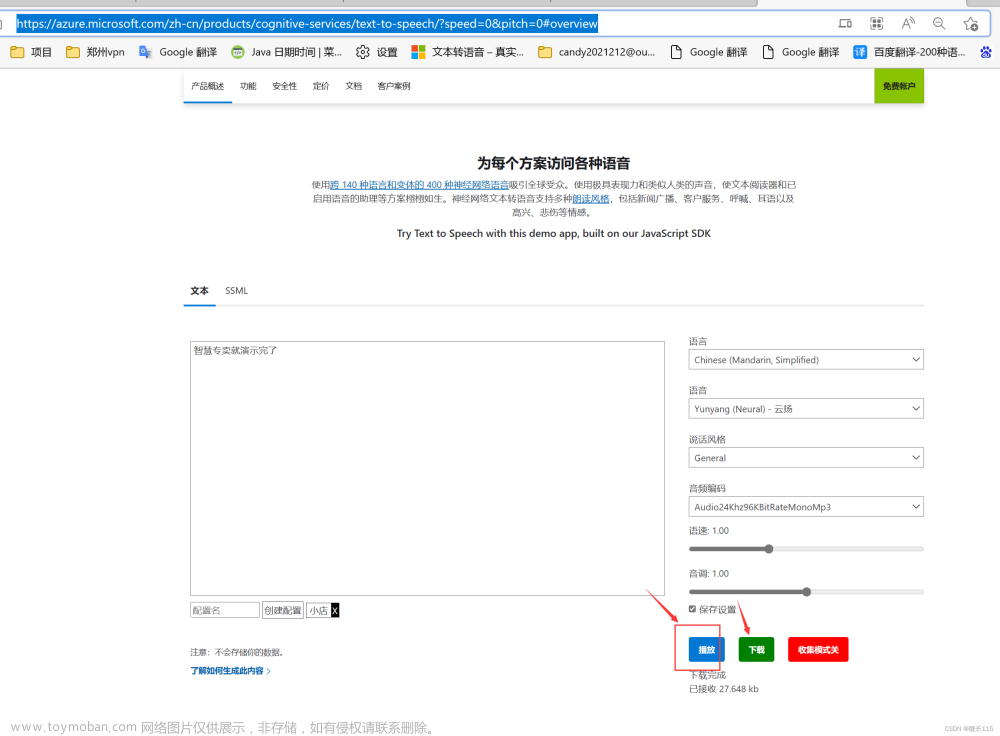
1、打开官网语音合成注册一个免费账号
如果打不开,可能需要科学上网,另外需要一个邮箱,最好是谷歌邮箱,其他邮箱如QQ邮箱没试过,不清楚,另外最最最最重要的是要有一张信用卡且支持Visa
2、开通认知服务中的语音Azure 服务
注册账号成功之后来到这个界面
点击左上角+号添加语音服务,获取密钥和位置/区域,推荐亚洲区(East Asia
二:集成语音SDK
1、GitHub示例代码
2、看官方文档,安装语音 SDK
跟着文档走,总结一下就是添加语音依赖库
implementation 'com.microsoft.cognitiveservices.speech:client-sdk:1.26.0'
3、文档中的示例我测试处理,下面放经过我优化调整后的代码,直接可用
import android.util.Log;
import com.microsoft.cognitiveservices.speech.*;
import com.xxx.config.Constants;
/**
* @author 小红妹
* @date 2023/3/16
* @email L22~3535@163.com
* @package com.xxx.speech
* @describe AzureSpeech
* @copyright
*/
public class SpeechSynthesis {
private SpeechConfig speechConfig;
private SpeechSynthesizer speechSynthesizer;
private SpeechSynthesisResult speechSynthesisResult;
public void azureSpeak() {
// This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION"
speechConfig = SpeechConfig.fromSubscription(Constants.SPEECH_KEY1, Constants.SPEECH_REGION);
// Required for WordBoundary event sentences.
speechConfig.setProperty(PropertyId.SpeechServiceResponse_RequestSentenceBoundary, "true");
// Set either the `SpeechSynthesisVoiceName` or `SpeechSynthesisLanguage`.
speechConfig.setSpeechSynthesisVoiceName(Constants.SPEECH_NAME);//"en-US-JennyNeural"
String ssml = String.format("<speak version='1.0' xml:lang='en-US' xmlns='http://www.w3.org/2001/10/synthesis' xmlns:mstts='http://www.w3.org/2001/mstts'>"
.concat(String.format("<voice name='%s'>", Constants.SPEECH_NAME))
.concat("<mstts:viseme type='redlips_front'/>")
.concat("The rainbow has seven colors: <bookmark mark='colors_list_begin'/>Red, orange, yellow, green, blue, indigo, and violet.<bookmark mark='colors_list_end'/>.")
.concat("</voice>")
.concat("</speak>"));
assert(speechConfig != null);
//将合成语音输出到当前活动输出设备(例如扬声器)
AudioConfig audioConfig = AudioConfig.fromDefaultSpeakerOutput();
speechSynthesizer = new SpeechSynthesizer(speechConfig, audioConfig);
assert(speechSynthesizer != null);
// Subscribe to events
speechSynthesizer.BookmarkReached.addEventListener((o, e) -> {
System.out.println("BookmarkReached event:");
System.out.println("\tAudioOffset: " + ((e.getAudioOffset() + 5000) / 10000) + "ms");
System.out.println("\tText: " + e.getText());
});
speechSynthesizer.SynthesisCanceled.addEventListener((o, e) -> {
System.out.println("SynthesisCanceled event");
});
//ok
speechSynthesizer.SynthesisCompleted.addEventListener((o, e) -> {
SpeechSynthesisResult result = e.getResult();
byte[] audioData = result.getAudioData();
System.out.println("SynthesisCompleted event:");
System.out.println("\tAudioData: " + audioData.length + " bytes");
System.out.println("\tAudioDuration: " + result.getAudioDuration());
result.close();
});
speechSynthesizer.SynthesisStarted.addEventListener((o, e) -> {
System.out.println("SynthesisStarted event");
});
speechSynthesizer.Synthesizing.addEventListener((o, e) -> {
SpeechSynthesisResult result = e.getResult();
byte[] audioData = result.getAudioData();
System.out.println("Synthesizing event:");
System.out.println("\tAudioData: " + audioData.length + " bytes");
result.close();
});
speechSynthesizer.VisemeReceived.addEventListener((o, e) -> {
System.out.println("VisemeReceived event:");
System.out.println("\tAudioOffset: " + ((e.getAudioOffset() + 5000) / 10000) + "ms");
System.out.println("\tVisemeId: " + e.getVisemeId());
});
speechSynthesizer.WordBoundary.addEventListener((o, e) -> {
System.out.println("WordBoundary event:");
System.out.println("\tBoundaryType: " + e.getBoundaryType());
System.out.println("\tAudioOffset: " + ((e.getAudioOffset() + 5000) / 10000) + "ms");
System.out.println("\tDuration: " + e.getDuration());
System.out.println("\tText: " + e.getText());
System.out.println("\tTextOffset: " + e.getTextOffset());
System.out.println("\tWordLength: " + e.getWordLength());
});
// Synthesize the SSML
System.out.println("SSML to synthesize:");
System.out.println(ssml);
try {
//speechSynthesisResult = speechSynthesizer.SpeakSsmlAsync(ssml).get();
speechSynthesisResult = speechSynthesizer.SpeakText("おはようございます, 朝食を食べましょう!");
assert(speechSynthesisResult != null);
if (speechSynthesisResult.getReason() == ResultReason.SynthesizingAudioCompleted) {
System.out.println("SynthesizingAudioCompleted result");
}
else if (speechSynthesisResult.getReason() == ResultReason.Canceled) {
SpeechSynthesisCancellationDetails cancellation = SpeechSynthesisCancellationDetails.fromResult(speechSynthesisResult);
System.out.println("CANCELED: Reason=" + cancellation.getReason());
if (cancellation.getReason() == CancellationReason.Error) {
System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode());
System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails());
System.out.println("CANCELED: Did you set the speech resource key and region values?");
}
}
} catch (Exception ex) {
Log.e("SpeechSDKDemo", "unexpected " + ex.getMessage());
assert(false);
}
System.exit(0);
}
//onDestroy
public void closeSpeech() {
// Release speech synthesizer and its dependencies
speechSynthesizer.close();
speechConfig.close();
}
}
这里,将密钥和位置改成你自己的,Constants.SPEECH_KEY1, Constants.SPEECH_REGION替换成自己的,Constants.SPEECH_NAME这个是设置语言,代码中我写的是日语,其他的你们自己改。
官方文档将语音合成到文件中
总结一下
在写之前雄心勃勃,要写一篇网上较好的微软语音合成文章,写着写着没劲了!
哈哈哈哈哈哈哈哈哈哈哈哈哈哈红红火火恍恍惚惚 ~哈哈哈哈哈哈哈哈哈文章来源:https://www.toymoban.com/news/detail-443236.html
好吧~
该总结一下,只说关键词
1、注册微软账号,Visa信用卡
2、开通语音服务
3、复制示例代码,修改密钥等参数
4、运行搞定文章来源地址https://www.toymoban.com/news/detail-443236.html
到了这里,关于Android快速集成微软语音服务(Azure认知服务)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[Unity+OpenAI TTS] 集成openAI官方提供的语音合成服务,构建海王暖男数字人](https://imgs.yssmx.com/Uploads/2024/02/761897-1.png)