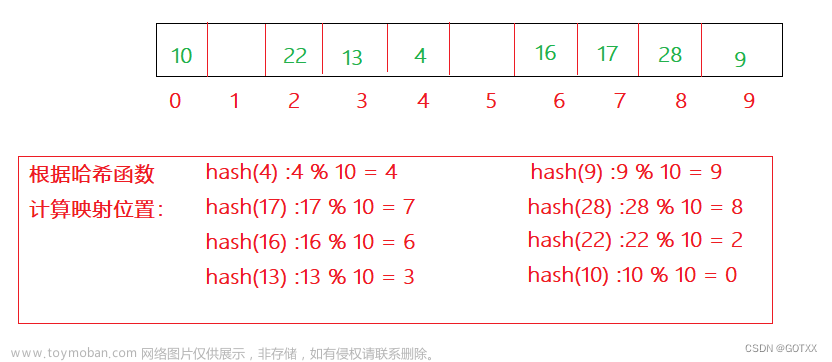
什么是哈希
哈希(Hash)是一种算法,它接受一个输入(或“消息”),并返回一个固定大小的字符串。这个输出字符串的大小通常以字节为单位,输出的内容看起来是随机的且整个过程是单向的。
哈希的一些关键特性包括:
不管你输入的信息有多大,哈希值的大小总是固定的。
即使只改变输入的一点点信息,对应的哈希值也会有很大的变化。
从哈希值是无法恢复原始的输入信息的,这就是为什么说哈希函数是单向的。
哈希在很多领域都有应用,比如在密码学中用来保存密码,或者在数据结构中用来快速查找元素(比如哈希表或者哈希映射)。在密码学应用中,一个重要的特性是哈希冲突的可能性需要非常低,也就是说,两个不同的输入得到相同的哈希值的可能性需要非常低。
哈希的底层原理是如何实现的
哈希的底层原理是基于“哈希函数”和“哈希表”的。
哈希函数:哈希函数是一种将输入(通常是字符串)映射到固定大小输出的函数,其输出称为哈希值。该哈希值是原始数据的索引,存储在哈希表中。良好的哈希函数应具有以下属性:相同的输入产生相同的输出;不同的输入尽可能产生不同的输出(避免碰撞);哈希函数应尽可能快。
哈希表:哈希表是一个数组,用于存储数据,以便可以快速找到。当需要查找或插入一个元素时,哈希表使用哈希函数将这个元素映射到数组的某个索引。然后,元素就存储在这个索引位置。理想情况下,这个映射过程使得每个索引位置都只有一个元素,从而实现查找、插入和删除操作的时间复杂度都是O(1)。
然而,碰撞是哈希表中一个重要问题。当两个元素的哈希值相同,他们就需要在同一个索引位置存储,这就是所谓的“碰撞”。解决碰撞的常见方法有开放寻址法和链地址法。
为什么哈希查找是O(1)的复杂度?
哈希查找的时间复杂度是O(1)的原因在于,通过哈希函数,可以直接计算出元素的存储地址,而不需要从头到尾逐一查找,所以查找速度非常快。但这是在理想情况下,即不存在哈希冲突的情况下。如果有哈希冲突,那么时间复杂度就不再是O(1)。
C++ STL库中的哈希实现
现在来看C++ STL库中的哈希表和树的实现。
unordered_set和unordered_map:
- 这两个容器在C++ STL库中的实现使用的是哈希表,所以它们的查找、插入和删除操作的平均时间复杂度都是O(1)。但如果出现哈希冲突,最坏的情况可能需要O(n)的时间复杂度。
set和map:
- 这两个容器在C++ STL库中的实现使用的是红黑树(一种自平衡二叉查找树),所以它们的查找、插入和删除操作的平均时间复杂度都是O(log n)。
不同哈希实现的优缺点
请注意,哈希表和红黑树都有其优点和缺点。
-
哈希表在查找、插入和删除操作上非常快,但是不支持顺序操作(例如,按顺序遍历所有元素)。同时,哈希表也可能因为哈希冲突导致某些操作的时间复杂度达到O(n)。
-
红黑树,作为一种平衡搜索树,虽然它的查找、插入和删除操作的时间复杂度是O(log n),但是它支持顺序操作,并且它的时间复杂度在所有情况下都是确定的,不会像哈希表那样因为哈希冲突而有所变化。
所以在选择使用哪种容器时,你需要根据你的具体需求来决定。如果你需要快速查找,插入和删除,并且不关心元素的顺序,那么unordered_set或unordered_map可能是更好的选择。如果你需要保持元素的顺序,那么set或map可能是更好的选择。
哈希类型题型的做题思路与技巧
在解决哈希表相关的题目时,可以遵循以下思路和技巧:
-
识别问题:首先要判断题目是否适合使用哈希表来解决。通常,如果题目涉及到需要在较短时间内完成的查找、插入或删除操作,那么哈希表可能是一个合适的选择。
-
设计哈希函数:选择或设计一个合适的哈希函数是解决哈希表问题的关键。哈希函数应具有良好的分布特性,以便将输入均匀地映射到哈希表的不同位置。在某些情况下,可以使用默认的哈希函数;而在其他情况下,可能需要自定义哈希函数。
-
选择键值对:确定如何将输入数据表示为键值对。这可能涉及到提取特定属性作为键,或者将多个属性组合起来生成唯一的键。在某些情况下,值可能只是一个计数器,而在其他情况下,它可能是一个更复杂的数据结构,如列表、集合或其他哈希表。
-
处理冲突:冲突是哈希表中的一个常见问题,它发生在不同的输入数据被映射到哈希表的相同位置时。处理冲突的方法有多种,如链地址法(将具有相同哈希值的元素存储在链表中)和开放地址法(寻找下一个可用的位置)。在实际编程中,哈希表库通常已经实现了冲突处理机制,但了解这些概念有助于更好地理解哈希表的工作原理。
-
时间与空间权衡:在解决哈希表问题时,通常需要在时间复杂度和空间复杂度之间进行权衡。使用哈希表可以加快查找和修改操作,但这通常需要额外的空间来存储数据。在编写代码时,请注意分析时间和空间复杂度,并根据具体问题和限制进行优化。
-
边界条件与错误处理:在处理哈希表相关的题目时,请注意处理边界条件,例如空输入、重复值等。此外,确保正确处理哈希表中不存在的键,以避免运行时错误。
-
选择合适的哈希表实现:在编程语言库中,通常有多种哈希表实现可供选择,如 C++ 中的 unordered_map 和 unordered_set。了解这些实现的特性和优缺点,以便在不同场景下选择合适的哈希表实现。例如,有些实现会自动处理冲突,有些实现是有序的,而有些实现则适用于特定类型的键。
-
熟悉哈希表操作:掌握常用的哈希表操作,如插入、删除、查找和更新。了解这些操作的时间复杂度,以便在解决问题时做出合理的估算。
-
多种解决方案的比较:在解决哈希表问题时,尝试比较不同的解决方案。分析各种方案的时间和空间复杂度,以找到最优解。
-
练习与总结:通过大量练习来提高解决哈希表问题的能力。在解决问题后,总结所学到的技巧和经验,并将其应用到未来的问题中。
总之,在解决哈希表相关的题目时,要熟练掌握哈希表的基本概念、操作和实现,关注时间与空间复杂度的权衡,设计合适的哈希函数和键值对表示,处理冲突和边界条件,以及比较不同解决方案的优缺点。通过大量练习和总结,可以不断提高解决哈希表问题的能力。
哈希表题目清单
- 《程序员面试金典(第6版)》面试题 02.01. 移除重复节点(unordered_set)
- 《程序员面试金典(第6版)》面试题 02.07. 链表相交(unordered_set)
- 《程序员面试金典(第6版)》面试题 02.08. 环路检测(unordered_set)
- 《程序员面试金典(第6版)》面试题 10.02. 变位词组(unordered_map)
- 《程序员面试金典(第6版)》面试题 16.02. 单词频率(unordered_map)
- 《程序员面试金典(第6版)》面试题 16.20. T9键盘(unordered_map,优化后可用vector)
- 《程序员面试金典(第6版)》面试题 16.21. 交换和(unordered_set)
- 《程序员面试金典(第6版)》面试题 16.22. 兰顿蚂蚁(嵌套unordered_map,高难度映射,反复映射)
- 《程序员面试金典(第6版)》面试题 16.24. 数对和(unordered_map)
- 《程序员面试金典(第6版)》面试题 16.25. LRU 缓存(unordered_map)
总结
-
哈希的底层原理基于哈希函数和哈希表。哈希函数将输入映射到固定大小的输出,即哈希值。哈希表是一个数组,用哈希值作为索引来存储数据。
-
查找、插入和删除操作的平均时间复杂度是O(1),因为可以直接通过哈希值找到元素的存储地址,无需逐一查找。但在哈希冲突(两个元素哈希值相同)的情况下,时间复杂度可能变为O(n)。
-
C++ STL库中,unordered_set和unordered_map基于哈希表实现,set和map基于红黑树(一种自平衡二叉查找树)实现。
-
unordered_set和unordered_map在查找、插入和删除操作上非常快,但不支持顺序操作,且可能因哈希冲突导致时间复杂度变化。
-
set和map的查找、插入和删除操作的时间复杂度是O(log n),但支持顺序操作,并且时间复杂度在所有情况下都是确定的。
-
在选择使用哪种容器时,应根据具体需求决定。如果需要快速查找、插入和删除,并不关心元素顺序,那么选择unordered_set或unordered_map;如果需要保持元素顺序,那么选择set或map。文章来源:https://www.toymoban.com/news/detail-443277.html
最后的最后,如果你觉得我的这篇文章写的不错的话,请给我一个赞与收藏,关注我,我会继续给大家带来更多更优质的干货内容。文章来源地址https://www.toymoban.com/news/detail-443277.html
到了这里,关于全面理解哈希,哈希的底层原理是如何实现的,哈希题型的做题思路与题目清单(不断更新)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[深入理解NAND Flash (原理篇)] Flash(闪存)存储器底层原理 | 闪存存储器重要参数](https://imgs.yssmx.com/Uploads/2024/02/735174-1.png)