前言
人脸识别,是基于人的脸部特征信息进行身份识别的一种生物识别技术。用摄像机或摄像头采集含有人脸的图像或视频流,并自动在图像中检测和跟踪人脸,进而对检测到的人脸进行脸部识别的一系列相关技术,通常也叫做人像识别、面部识别。
人脸识别是机器学习热门领域之一,在 github 上有很多项目实现了各种人脸识别功能,以下面6个测试软件使用
- https://github.com/ageitgey/face_recognition
- https://github.com/PaddlePaddle/PaddleDetection
- https://github.com/serengil/deepface
- https://github.com/deepinsight/insightface
- https://github.com/seetaface/SeetaFaceEngine
- https://github.com/TadasBaltrusaitis/OpenFace
一、face_recognition
face_recognition 是世界上最简洁的人脸识别库,可以使用 Python 和命令行工具提取、识别、操作人脸。
face_recognition 项目的人脸识别是基于业内领先的C++开源库 dlib中的深度学习模型,用Labeled Faces in the Wild人脸数据集进行测试,有高达99.38%的准确率。但对小孩和亚洲人脸的识别准确率尚待提升。
Labeled Faces in the Wild是美国麻省大学安姆斯特分校(University of Massachusetts Amherst)制作的人脸数据集,该数据集包含了从网络收集的13,000多张面部图像。
1.1 安装
pip install face_recognition
1.2 检测人脸位置
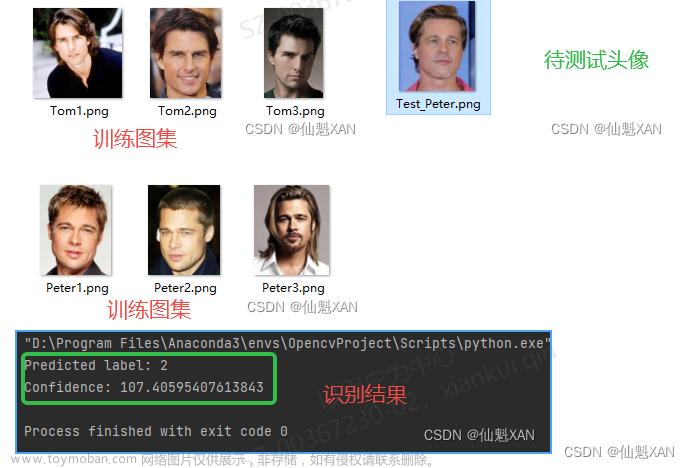
可以使用命令行命令 face_detection 来识别人脸,下面以胡歌照片为例,来演示具体使用

face_detection faces/huge.jpg
# 输出:faces/huge.jpg,101,221,173,149
使用命令行只显示了位置的具体坐标,不能准确的用肉眼查看,可以使用 python 来标记
import face_recognition
from PIL import Image, ImageDraw
image = face_recognition.load_image_file("huge.jpg")
face_locations = face_recognition.face_locations(image)
pil_image = Image.fromarray(image)
draw = ImageDraw.Draw(pil_image)
for (top, right, bottom, left) in face_locations:
draw.rectangle(((left, top), (right, bottom)), outline=(0, 0, 255))
del draw
pil_image.save("huge_face.jpg")

多张人脸检测
原始照片

标记人脸位置照片

1.3 识别人脸
face_recognition 不仅支持识别人脸所在照片位置,更能识别人脸所代表的人
将 [‘刘诗诗.jpg’, ‘唐嫣.jpg’, ‘杨幂.jpg’, ‘胡歌.jpg’, ‘霍建华.jpg’, ‘黄志玮.jpg’] 照片放在一个文件夹下,例如我的是 known 文件夹下,再将仙剑三海报 all.jpg 放在和脚本同一目录下,开始识别人脸
测试的6张照片都是从网上找的,链接如下
- 刘诗诗
- 唐嫣
- 杨幂
- 胡歌
- 霍建华
- 黄志玮
import face_recognition
import os
from PIL import Image, ImageDraw, ImageFont
import numpy as np
font = ImageFont.truetype("C:\\Windows\\Fonts\\simsun.ttc", 40, encoding="utf-8")
known_path = "../known"
known_face_names = []
known_face_encodings = []
images = os.listdir(known_path)
print(images)
for image in images:
if image.endswith('jpg'):
known_face_names.append(os.path.basename(image).split(".")[0])
image_data = face_recognition.load_image_file(os.path.join(known_path, image))
known_face_encodings.append(face_recognition.face_encodings(image_data)[0])
all_face_path = "all.jpg"
all_image = face_recognition.load_image_file(all_face_path)
all_face_locations = face_recognition.face_locations(all_image)
all_face_encodings = face_recognition.face_encodings(all_image, all_face_locations)
pil_image = Image.fromarray(all_image)
draw = ImageDraw.Draw(pil_image)
for (top, right, bottom, left), face_encoding in zip(all_face_locations, all_face_encodings):
matches = face_recognition.compare_faces(known_face_encodings, face_encoding, tolerance=0.5)
name = "未知"
face_distances = face_recognition.face_distance(known_face_encodings, face_encoding)
best_match_index = np.argmin(face_distances)
if matches[best_match_index]:
name = known_face_names[best_match_index]
draw.rectangle(((left, top), (right, bottom)), outline=(0, 0, 255))
text_width, text_height = draw.textsize(name, font=font)
draw.text((left + 6, bottom - text_height - 5), name, fill=(255, 255, 255, 255), font=font)
del draw
pil_image.save("all_faces.jpg")

二、PaddleDetection
PaddleDetection为基于飞桨 PaddlePaddle 的端到端目标检测套件,内置30+模型算法及250+预训练模型,覆盖目标检测、实例分割、跟踪、关键点检测等方向,其中包括服务器端和移动端高精度、轻量级产业级SOTA模型、冠军方案和学术前沿算法,并提供配置化的网络模块组件、十余种数据增强策略和损失函数等高阶优化支持和多种部署方案,在打通数据处理、模型开发、训练、压缩、部署全流程的基础上,提供丰富的案例及教程,加速算法产业落地应用。
2.1 安装
下载源码,根据readme安装,注意下载源码版本需要根 paddlepaddle 版本对应。
安装过程中,安装cython bbox 失败,解决方法:windows下安装cython-bbox失败。下载资源:cython+bbox-0.1.3
2.2 运行
PaddleDetection 内置一个高效、高速的人脸检测解决方案,包括最先进的模型和经典模型
python tools/infer.py -c configs/face_detection/blazeface_1000e.yml -o weights=https://paddledet.bj.bcebos.com/models/blazeface_1000e.pdparams --infer_img=C:\Users\supre\Desktop\faces\all.jpg --output_dir=infer_output/ --draw_threshold=0.6

三、DeepFace
Deepface 是一个轻量级的人脸面部识别和面部属性分析(年龄、性别、情感和种族)框架。它是一个混合的人脸识别框架,包装了最先进的模型:VGG-Face, Google FaceNet, OpenFace, Facebook DeepFace, DeepID, ArcFace, Dlib and SFace.
实验表明,人类在面部识别任务上的准确率为97.53%,而这些模型已经达到并通过了这个准确率水平。
3.1 安装
pip install deepface
3.2 检测人脸位置
from deepface import DeepFace
from deepface.detectors import FaceDetector
import cv2
img_path = "C:\\Users\\supre\\Desktop\\faces\\all.jpg"
detector_name = "opencv"
img = cv2.imread(img_path)
detector = FaceDetector.build_model(detector_name) #set opencv, ssd, dlib, mtcnn or retinaface
obj = FaceDetector.detect_faces(detector, detector_name, img)
faces = []
regions = []
for o in obj:
face, region = o
faces.append(face)
regions.append(region)
for (x, y, w, h) in regions:
cv2.rectangle(img, (x, y), (x+w, y + h), (0, 0, 255), 2)
cv2.imwrite("all_deep_face.jpg", img)
cv2.imshow('faces', img)
cv2.waitKey(0)
print("there are ",len(obj)," faces")

3.3 人脸属性分析
运行下面代码会从 github 下载训练好的模型文件,如果下载太慢可手动下载:https://github.com/serengil/deepface_models/releases/
from deepface import DeepFace
obj = DeepFace.analyze(img_path = "faces/huge.jpg",
actions = ['age', 'gender', 'race', 'emotion']
)
print(obj)
输出:
{'age': 31, 'region': {'x': 141, 'y': 90, 'w': 92, 'h': 92}, 'gender': 'Man', 'race': {'asian': 86.62416855240873, 'indian': 0.2717677898641103, 'black': 0.025535856615095234, 'white': 11.001530200334203, 'middle eastern': 0.36970814565319693, 'latino hispanic': 1.707288910883004}, 'dominant_race': 'asian', 'emotion': {'angry': 4.005255788877951, 'disgust': 1.1836746688898558e-05, 'fear': 91.75890038960578, 'happy': 1.023393651002267, 'sad': 0.9277909615809299, 'surprise': 2.081933555420253, 'neutral': 0.20271948350039026}, 'dominant_emotion': 'fear'}
四、insightface
insightface 是一个开源的二维和三维深度面部分析工具箱,主要基于 PyTorch 和 MXNet。实现了很多人脸识别、人脸检测和人脸对齐算法,为训练和部署进行了优化。
4.1 安装
pip install insightface
4.2 运行
运行出现报错:TypeError: __init__() got an unexpected keyword argument 'provider_options'
查找资料Error “got an unexpected keyword argument ‘provider_options’” when running quick example of insightface得知:是由于onnxruntime 版本过低导致,更新版本
pip install onnxruntime==1.6.0
import cv2
import numpy as np
import insightface
from insightface.app import FaceAnalysis
from insightface.data import get_image as ins_get_image
app = FaceAnalysis(providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
app.prepare(ctx_id=0, det_size=(640, 640))
img = ins_get_image('C:\\Users\\supre\\Desktop\\faces\\all')
faces = app.get(img)
rimg = app.draw_on(img, faces)
cv2.imwrite("./all_output.jpg", rimg)

五、SeetaFaceEngine
SeetaFaceEngine 是一个开源的C++人脸识别引擎,由中科院计算所山世光研究员带领的人脸识别研究组研发。代码基于C++实现,且不依赖于任何第三方的库函数,开源协议为BSD-2,可供学术界和工业界免费使用它可以运行在CPU上。它包含人脸检测、人脸对准和人脸识别三个关键部分,是构建真实人脸识别应用系统的必要和充分条件
5.1 编译
SeetaFaceEngine 包含三部分,所以需要使用 cmake 编译三次,编译方法见 readme
5.2 人脸检测
#include <cstdint>
#include <fstream>
#include <iostream>
#include <string>
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "face_detection.h"
using namespace std;
int main(int argc, char** argv) {
const char* img_path = "C:\\Users\\supre\\Desktop\\faces\\all.jpg";
seeta::FaceDetection detector("E:\\tmp\\SeetaFaceEngine-master\\FaceDetection\\model\\seeta_fd_frontal_v1.0.bin");
detector.SetMinFaceSize(40);
detector.SetScoreThresh(2.f);
detector.SetImagePyramidScaleFactor(0.8f);
detector.SetWindowStep(4, 4);
cv::Mat img = cv::imread(img_path, cv::IMREAD_UNCHANGED);
cv::Mat img_gray;
if (img.channels() != 1)
cv::cvtColor(img, img_gray, cv::COLOR_BGR2GRAY);
else
img_gray = img;
seeta::ImageData img_data;
img_data.data = img_gray.data;
img_data.width = img_gray.cols;
img_data.height = img_gray.rows;
img_data.num_channels = 1;
long t0 = cv::getTickCount();
std::vector<seeta::FaceInfo> faces = detector.Detect(img_data);
long t1 = cv::getTickCount();
double secs = (t1 - t0)/cv::getTickFrequency();
cout << "Detections takes " << secs << " seconds " << endl;
cout << "Image size (wxh): " << img_data.width << "x"
<< img_data.height << endl;
cv::Rect face_rect;
int32_t num_face = static_cast<int32_t>(faces.size());
for (int32_t i = 0; i < num_face; i++) {
face_rect.x = faces[i].bbox.x;
face_rect.y = faces[i].bbox.y;
face_rect.width = faces[i].bbox.width;
face_rect.height = faces[i].bbox.height;
cv::rectangle(img, face_rect, CV_RGB(0, 0, 255), 4, 8, 0);
}
cv::namedWindow("Test", cv::WINDOW_AUTOSIZE);
cv::imwrite("all_1.jpg", img);
cv::imshow("Test", img);
cv::waitKey(0);
cv::destroyAllWindows();
}

5.3 face alignment
face alignment 指 通过一定量的训练集(人脸图像和每个图像上相对应的多个landmarks),来得到一个model,使得该model再输入了一张任意姿态下的人脸照片后,能够对该照片中的关键点进行标记.
#include <cstdint>
#include <fstream>
#include <iostream>
#include <string>
#include "cv.h"
#include "highgui.h"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "face_detection.h"
#include "face_alignment.h"
int main(int argc, char** argv)
{
// Initialize face detection model
std::string MODEL_DIR = "E:\\tmp\\SeetaFaceEngine-master\\FaceAlignment\\model\\";
std::string DATA_DIR = "E:\\tmp\\SeetaFaceEngine-master\\FaceAlignment\\data\\";
std::string IMG_PATH = DATA_DIR + "all.jpg";
int pts_num = 5;
seeta::FaceDetection detector("E:\\tmp\\SeetaFaceEngine-master\\FaceDetection\\model\\seeta_fd_frontal_v1.0.bin");
detector.SetMinFaceSize(40);
detector.SetScoreThresh(2.f);
detector.SetImagePyramidScaleFactor(0.8f);
detector.SetWindowStep(4, 4);
// Initialize face alignment model
seeta::FaceAlignment point_detector((MODEL_DIR + "seeta_fa_v1.1.bin").c_str());
//load image
cv::Mat img = cv::imread(IMG_PATH, cv::IMREAD_UNCHANGED);
cv::Mat img_gray;
if (img.channels() != 1)
cv::cvtColor(img, img_gray, cv::COLOR_BGR2GRAY);
else
img_gray = img;
seeta::ImageData img_data;
img_data.data = img_gray.data;
img_data.width = img_gray.cols;
img_data.height = img_gray.rows;
img_data.num_channels = 1;
std::vector<seeta::FaceInfo> faces = detector.Detect(img_data);
int32_t face_num = static_cast<int32_t>(faces.size());
std::cout<<"face_num:"<<face_num;
if (face_num == 0)
{
return 0;
}
cv::Rect face_rect;
for (int32_t i = 0; i < face_num; i++) {
face_rect.x = faces[i].bbox.x;
face_rect.y = faces[i].bbox.y;
face_rect.width = faces[i].bbox.width;
face_rect.height = faces[i].bbox.height;
cv::rectangle(img, face_rect, CV_RGB(0, 0, 255), 4, 8, 0);
// Detect 5 facial landmarks
seeta::FacialLandmark points[5];
point_detector.PointDetectLandmarks(img_data, faces[i], points);
for (int i = 0; i< pts_num; i++)
{
cv::circle(img, cvPoint(points[i].x, points[i].y), 2, CV_RGB(0, 255, 0), CV_FILLED);
}
}
cv::namedWindow("Test", cv::WINDOW_AUTOSIZE);
cv::imwrite("test.jpg", img);
cv::imshow("Test", img);
cv::waitKey(0);
cv::destroyAllWindows();
return 0;
}

5.4 人脸检测相似率
#include <opencv/cv.h>
#include <opencv/highgui.h>
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "face_identification.h"
#include "recognizer.h"
#include "face_detection.h"
#include "face_alignment.h"
#include "math_functions.h"
#include <vector>
#include <string>
#include <iostream>
#include <algorithm>
using namespace seeta;
using namespace std;
std::string DATA_DIR = "E:\\tmp\\SeetaFaceEngine-master\\FaceIdentification\\data\\";
std::string MODEL_DIR = "E:\\tmp\\SeetaFaceEngine-master\\FaceIdentification\\model\\";
int main(int argc, char* argv[]) {
// Initialize face detection model
seeta::FaceDetection detector("E:\\tmp\\SeetaFaceEngine-master\\FaceDetection\\model\\seeta_fd_frontal_v1.0.bin");
detector.SetMinFaceSize(40);
detector.SetScoreThresh(2.f);
detector.SetImagePyramidScaleFactor(0.8f);
detector.SetWindowStep(4, 4);
// Initialize face alignment model
seeta::FaceAlignment point_detector("E:\\tmp\\SeetaFaceEngine-master\\FaceAlignment\\model\\seeta_fa_v1.1.bin");
// Initialize face Identification model
FaceIdentification face_recognizer((MODEL_DIR + "seeta_fr_v1.0.bin").c_str());
std::string test_dir = DATA_DIR + "test_face_recognizer/";
//load image
cv::Mat gallery_img_color = cv::imread(test_dir + "images/liushishi_1.jpg", 1);
cv::Mat gallery_img_gray;
cv::cvtColor(gallery_img_color, gallery_img_gray, CV_BGR2GRAY);
cv::Mat probe_img_color = cv::imread(test_dir + "images/liushishi_2.jpg", 1);
cv::Mat probe_img_gray;
cv::cvtColor(probe_img_color, probe_img_gray, CV_BGR2GRAY);
ImageData gallery_img_data_color(gallery_img_color.cols, gallery_img_color.rows, gallery_img_color.channels());
gallery_img_data_color.data = gallery_img_color.data;
ImageData gallery_img_data_gray(gallery_img_gray.cols, gallery_img_gray.rows, gallery_img_gray.channels());
gallery_img_data_gray.data = gallery_img_gray.data;
ImageData probe_img_data_color(probe_img_color.cols, probe_img_color.rows, probe_img_color.channels());
probe_img_data_color.data = probe_img_color.data;
ImageData probe_img_data_gray(probe_img_gray.cols, probe_img_gray.rows, probe_img_gray.channels());
probe_img_data_gray.data = probe_img_gray.data;
// Detect faces
std::vector<seeta::FaceInfo> gallery_faces = detector.Detect(gallery_img_data_gray);
int32_t gallery_face_num = static_cast<int32_t>(gallery_faces.size());
std::vector<seeta::FaceInfo> probe_faces = detector.Detect(probe_img_data_gray);
int32_t probe_face_num = static_cast<int32_t>(probe_faces.size());
if (gallery_face_num == 0 || probe_face_num==0)
{
std::cout << "Faces are not detected.";
return 0;
}
// Detect 5 facial landmarks
seeta::FacialLandmark gallery_points[5];
point_detector.PointDetectLandmarks(gallery_img_data_gray, gallery_faces[0], gallery_points);
seeta::FacialLandmark probe_points[5];
point_detector.PointDetectLandmarks(probe_img_data_gray, probe_faces[0], probe_points);
for (int i = 0; i<5; i++)
{
cv::circle(gallery_img_color, cv::Point(gallery_points[i].x, gallery_points[i].y), 2,
CV_RGB(0, 255, 0));
cv::circle(probe_img_color, cv::Point(probe_points[i].x, probe_points[i].y), 2,
CV_RGB(0, 255, 0));
}
cv::imwrite("gallery_point_result.jpg", gallery_img_color);
cv::imwrite("probe_point_result.jpg", probe_img_color);
// Extract face identity feature
float gallery_fea[2048];
float probe_fea[2048];
face_recognizer.ExtractFeatureWithCrop(gallery_img_data_color, gallery_points, gallery_fea);
face_recognizer.ExtractFeatureWithCrop(probe_img_data_color, probe_points, probe_fea);
// Caculate similarity of two faces
float sim = face_recognizer.CalcSimilarity(gallery_fea, probe_fea);
std::cout << "相似率:"<<sim <<endl;
return 0;
}
使用两张刘诗诗照片对比:相似率为 0.679915

六、OpenFace
OpenFace, 一个旨在为计算机视觉和机器学习研究人员、情感计算社区和有兴趣构建基于面部行为分析的交互式应用程序的人使用的工具。OpenFace是第一个能够进行面部地标检测、头部姿态估计、面部动作单元识别和眼睛-注视估计的工具包,它具有可用的源代码,可用于运行和训练模型。代表 OpenFace 核心的计算机视觉算法在上述所有任务中都展示了最先进的结果。此外,我们的工具能够实时性能,并能够运行在非专业的硬件上, 例如一个简单的网络摄像头。
6.1 安装
- window
- 32位:https://github.com/TadasBaltrusaitis/OpenFace/releases/download/OpenFace_2.2.0/OpenFace_2.2.0_win_x86.zip
- 64位:https://github.com/TadasBaltrusaitis/OpenFace/releases/download/OpenFace_2.2.0/OpenFace_2.2.0_win_x64.zip
- Linux:https://github.com/TadasBaltrusaitis/OpenFace/wiki/Unix-Installation
- Mac:https://github.com/TadasBaltrusaitis/OpenFace/wiki/Mac-Installation
6.2 运行
OpenFace windows 版安装完成后还需要下载模型数据:https://github.com/TadasBaltrusaitis/OpenFace/wiki/Model-download,放在安装目录\model\patch_experts下面。
OpenFace 还提供了一些工具用于在命令行实现人脸识别
-
FaceLandmarkImg 从照片中识别人脸,还是以仙剑3海报做例子放在samples下面,再新建输出文件夹out_dir,开始识别人脸
FaceLandmarkImg.exe -f "samples/all.jpg" -out_dir "out_dir"输出结果为:

-
FaceLandmarkVid 从视频中识别人脸
-
FaceLandmarkVidMulti 从多个视频中识别人脸文章来源:https://www.toymoban.com/news/detail-443316.html
-
FeatureExtraction 用于包含单个人脸的分析文章来源地址https://www.toymoban.com/news/detail-443316.html
参考
- windows下安装cython-bbox失败
到了这里,关于6款人脸识别开源软件的简单使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!