GitHub项目地址:https://github.com/HarmoniaLeo/Face-Recognizer。若该项目帮助到了你,请点个star,谢谢!
模型介绍
MTCNN
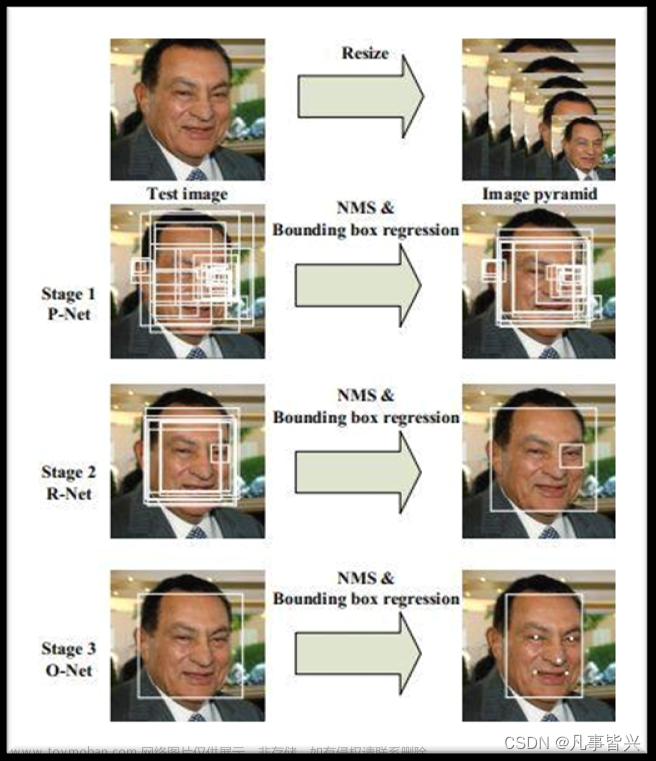
多任务卷积神经网络(Multi-task convolutional neural network,MTCNN)是在Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks[1]中提出的网络。MTCNN采用级联卷积神经网络(convolutional neural network,CNN)结构,通过多任务学习,能够同时完成人脸检测和人脸对齐两个任务,输出人脸的中心点坐标、尺度及特征点位置。MTCNN采用图像金字塔+3阶段级联CNN(P-Net、R-Net、O-Net) 方式进行人脸检测,其检测框架如图所示:

图像金字塔将图像尺度进行变换,在不同尺度上进行人脸的检测。级联CNN完成对人脸由粗到细(coarse-to-fine) 的检测,前者的输出是后者的输入,快速将不是人脸的区域剔除,对于可能包含人脸的区域交给后面更复杂的网络,利用更多信息进一步筛选,在保证召回率的情况下可以大大提高筛选效率。下图为MTCNN中级联的3个神经网络(P-Net、R-Net、O-Net),每层级联网络的网络层数逐渐加深,输入图像的感受野逐渐变大,最终输出的特征维数也在增加,意味着利用的信息越来越多。

三层级联网络的解释如下:
- P-Net:其实是个全卷积神经网络 (FCN),前向传播得到的特征图在每个位置是个32维的特征向量,用于判断每个位置处约12×12大小的区域内是否包含人脸,如果包含人脸,则回归出人脸的Bounding Box,进一步获得Bounding Box对应到原图中的区 域,通过NMS(Non-maximum suppression) 保留分数最高的Bounding box以及移除重叠区域过大的Bounding Box
- R-Net:是单纯的卷积神经网络(CNN),对输入进行细化选择,并且舍去大部分的错误输入,并再次使用边框回归和面部特征点定位器进行人脸区域的边框回归和特征点定位,最后将输出较为可信的人脸区域,供O-Net使用。对比与P-Net使用全卷积输出的1132的特征,R-Net使用在最后一个卷积层之后使用了一个128的全连接层,保留了更多的图像特征,准确度性能也优于P-Net
- O-Net :也是纯粹的卷积神经网络(CNN),将R-Net认为可能包含人脸的Bounding Box 双线性插值 到48×48,输入给O-Net,进行人脸检测和特征点提取
在训练阶段,3个网络都会将关键点位置作为监督信号来引导网络的学习, 但在预测阶段,P-Net和R-Net仅做人脸检测,不输出关键点位置,关键点位置仅在O-Net中输出。各级神经网络输出解释如下:
- face classification 采用softmax判断是否为人脸,因此输出为二维
- bounding box regression输出左上角和右下角的偏移量 ,因此输出为四维
- facial landmark localization定位左眼、右眼、鼻子、左嘴角、右嘴角共5个点的位置,因此输出为十维
FaceNet
FaceNet是谷歌于FaceNet: A Unified Embedding for Face Recognition and Clustering](FaceNet: A Unified Embedding for Face Recognition and Clustering[2]提出的一个对识别 (这是谁)、验证(是否为同一个人)、聚类(在多张面孔中找到同一个人)等问题的统一解决框架。FaceNet认为上述问题都可以放到特征空间里统一处理,难点在于如何将人脸更好的映射到特征空间。其本质是通过卷积神经网络学习人脸图像到128维欧几里得空间的映射,该映射将人脸图像映射为128维的特征向量,使用特征向量之间的距离的倒数来表征人脸图像之间的相似度。对于相同个体的不同图片,其特征向量之间的距离较小,对于不同个体的图像,其特征向量之间的距离较大。最后基于特征向量之间的相似度来解决人脸图像的识别、验证和聚类等问题,FaceNet算法的主要流程为:
-
将图像通过深度卷积神经网络映射到128维的特征空间(欧几里得空间)中,得到对应的128维特征向量
-
对特征向量进行L2正则化,筛选出有效特征
-
使用正则化后的特征向量,计算Triplets Loss
Triplets的意思是三元组,区别于神经网络的双参数计算(预测标签和真实标签),Triplet Loss是通过三个参数来计算的。三元组具体指anchor,positive,negative三部分,三者都是经过L2正则化后的特征向量。具体来说,anchor和positive 指的两个匹配的脸部缩略图,其中anchor是模型训练时的基准图片,positive 指的是与anchor相同个体的图片,negative指的是与anchor不同个体的图片。
FaceNet使用深度卷积神经网络来学习映射 并进一步设计了Triplets Loss训练该网络,之所以称之为三元组是因为该损失函数包含了两个匹配脸部缩略图和一个非匹配的脸部缩略图,其目标是通过距离边界来区分样本中的正负类,其中的脸部缩略图指裁剪后的人脸图片,除了缩放和平移之外,没有2D或3D对齐。三元组损失函数尝试将不同个体的人脸图像区分开来,使卷积网络能更好的学习、逼近 。
FaceNet的目的是将人脸图像嵌入到128维的欧氏空间 中。在该向量空间中,单个个体特征向量 (anchor)和该个体的其它特征向量距离 (positive)小,与其它个体的特征向量 (negative)距离大,如下图所示:

使用数学语言描述为: ∣ ∣ f ( x i a ) − f ( x i p ) ∣ ∣ 2 2 + α < ∣ ∣ f ( x i a ) − f ( x i n ) ∣ ∣ 2 2 , ∀ ( x i a , x i p , x i n ) ∈ R 128 ||f(x_i^a)-f(x_i^p)||_2^2+\alpha<||f(x_i^a)-f(x_i^n)||_2^2,\forall(x_i^a,x_i^p,x_i^n)\in\mathbb R^{128} ∣∣f(xia)−f(xip)∣∣22+α<∣∣f(xia)−f(xin)∣∣22,∀(xia,xip,xin)∈R128
即存在一个边界值 使得对于任意个体其所有特征向量之间的距离恒小于该个体任意特征向量与其它个体特征向量之间的距离。进一步即可定义出Triplets Loss: L l o s s = ∑ i N [ ∣ ∣ f ( x i a ) − f ( x i p ) ∣ ∣ 2 2 − ∣ ∣ f ( x i a ) − f ( x i n ) ∣ ∣ 2 2 + α ] + L_{loss}=\displaystyle\sum_{i}^N[||f(x_i^a)-f(x_i^p)||_2^2-||f(x_i^a)-f(x_i^n)||_2^2+\alpha]_+ Lloss=i∑N[∣∣f(xia)−f(xip)∣∣22−∣∣f(xia)−f(xin)∣∣22+α]+,其中 [ x ] + = max { 0 , x } [x]_+=\max\{0,x\} [x]+=max{0,x}
Triplets 的选择对模型的收敛非常重要。对于 x i a x_i^a xia,在实际训练中,需要选择同一个体的不同图片 x i p x_i^p xip,满足 arg max x i p ∣ ∣ f ( x i a ) − f ( x i p ) ∣ ∣ 2 2 \displaystyle\arg\max_{x_i^p}||f(x_i^a)-f(x_i^p)||_2^2 argxipmax∣∣f(xia)−f(xip)∣∣22,同时还要选择不同个体的图片 x i n x_i^n xin,满足 arg min x i n ∣ ∣ f ( x i a ) − f ( x i n ) ∣ ∣ 2 2 \displaystyle\arg\min_{x_i^n}||f(x_i^a)-f(x_i^n)||_2^2 argxinmin∣∣f(xia)−f(xin)∣∣22
在实际训练中,跨越所有训练样本来计算以上两者是不现实的,还会由于错误标签图像导致训练收敛困难。因此常用两种方法来进行筛选:
- 每隔 n n n步,计算子集的 x i p x_i^p xip和 x i n x_i^n xin
- 在线生成Triplets,即在每个mini-batch中进行筛选positive/negative样本
本项目采用在线生成Triplets方法进行筛选
基于MTCNN和FaceNet的实时人脸检测识别系统
MTCNN是强大的人脸特征提取器,我们采用MTCNN提取图像的特征,并利用FaceNet将图像特征映射到128维特征空间,随后在特征空间中比较人脸的相似性,进行人脸检测与识别。人脸检测识别系统的主要流程如下:
- 采用opencv实现从摄像头采集图像
- 通过MTCNN人脸检测模型,从照片中提取人脸图像
- 把人脸图像输入到FaceNet,计算embedding的特征向量
- 使用knn算法,比较特征向量间的欧式距离,判断是否为同一人,实现人脸识别

我们为本项目制作了一个简易UI,其可通过摄像头获取人脸视频、保存视频中人脸的特征以及加载已经保存的特征。运行main.py文件,可得到一个对话框:

点击Open camera开启摄像头,此时摄像头中检测到人脸,但未能识别人脸分类

我们获取人脸,并对该人脸命名,随后将人脸的特征添加至数据集中。

点击Save dataset将数据集以.npy格式保存。
随后,我们点击Load dataset载入保存的数据集重新进行人脸识别。可以看到,人脸检测系统现已能区分人脸。

此外,若摄像头中同时出现多张人脸,该人脸检测识别系统也能将人脸正确区分。我们按照上述步骤将人脸特征添加至数据集,随后开启摄像头进行人脸检测识别。

可见人脸检测识别系统准确地识别出了所有的人脸。
在LFW数据集上测试
我们另外还在LFW (Labled Faces in the Wild)[3]人脸数据集上进行了算法测试。LFW是目前人脸识别的常用测试集,其中提供的人脸图片均来源于生活中的自然场景,因此识别难度会增大,尤其由于多姿态、光照、表情、年龄、遮挡等因素影响导致即使同一人的照片差别也很大。并且有些照片中可能不止一个人脸出现,对这些多人脸图像仅选择中心坐标的人脸作为目标,其他区域的视为背景干扰。LFW数据集共有13233张人脸图像,每张图像均给出对应的人名,共有5749人,且绝大部分人仅有一张图片。每张图片的尺寸为250X250,绝大部分为彩色图像,但也存在少许黑白人脸图片。

在GitHub项目目录中,lfw_funneled文件夹包含LWF图像数据集,model包含MTCNN与FaceNet的网络架构与预训练好的权重。当需要在LWF数据集上进行测试时,可运行ctrUi.py文件
我们选取LWF数据集中所有人物照片大于两张的数据集,共有1681个数据集满足此条件。我们从1681个数据集中采用随机形式抽取数据集,每个数据集中随机抽取一对人脸,将其中一张输入数据系统,另一张用于匹配测试,计算测试准确率和测试时间。数据集结构如下图所示。


实验中选取 n = 10 , 20 , 40 , 60 , 80 , 120 n=10,20,40,60,80,120 n=10,20,40,60,80,120。对于每个 n n n,我们进行10次实验并记录准确率和时间。随后,我们取10次实验的平均值作为实验结果。运行时间与准确率表格与曲线绘制如下:
| n=1 | Accuracy | t(s)/sample |
|---|---|---|
| 10 | 0.94 | 0.089 |
| 20 | 0.945 | 0.087 |
| 40 | 0.903 | 0.086 |
| 60 | 0.9 | 0.086 |
| 80 | 0.882 | 0.087 |
| 100 | 0.88 | 0.086 |
| 120 | 0.877 | 0.089 |

如图所示,随着 n n n数值的增加,平均准确率基本保持下降(除 n = 20 n=20 n=20处略有上升)。在 n = 20 n=20 n=20时准确率最高,为0.945; n = 120 n=120 n=120时准确率最低,为0.877。我们推测随着该现象出现的原因为:由于FaceNet特征空间维度过高(128维度),因此少许偏差就会导致测试图像的特征 向量与其匹配向量的产生较大偏移,而接近于其它图像的特征向量。随着 n n n的增加,偏差后与其它点接近的可能性更大了,因此测试准确率随着 n n n增加而下降。
参考文献
[1] Zhang, Kaipeng, et al. “Joint face detection and alignment using multitask cascaded convolutional networks.” IEEE signal processing letters 23.10 (2016): 1499-1503.
[2] Schroff, Florian, Dmitry Kalenichenko, and James Philbin. “Facenet: A unified embedding for face recognition and clustering.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.文章来源:https://www.toymoban.com/news/detail-443625.html
[3] Huang, Gary B., et al. “Labeled faces in the wild: A database forstudying face recognition in unconstrained environments.” Workshop on faces in’Real-Life’Images: detection, alignment, and recognition. 2008.文章来源地址https://www.toymoban.com/news/detail-443625.html
到了这里,关于基于MTCNN和FaceNet的实时人脸检测识别系统的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!