Cross-Attention in Transformer Architecture
最近,CrossViT让我所有思考,这种能过够跨膜态的模型构建?浅学一下吧!
目录
1.Cross attention概念
2.Cross-attention vs Self-attention
3.Cross-attention算法
4.Cross-Attention 案例-感知器IO
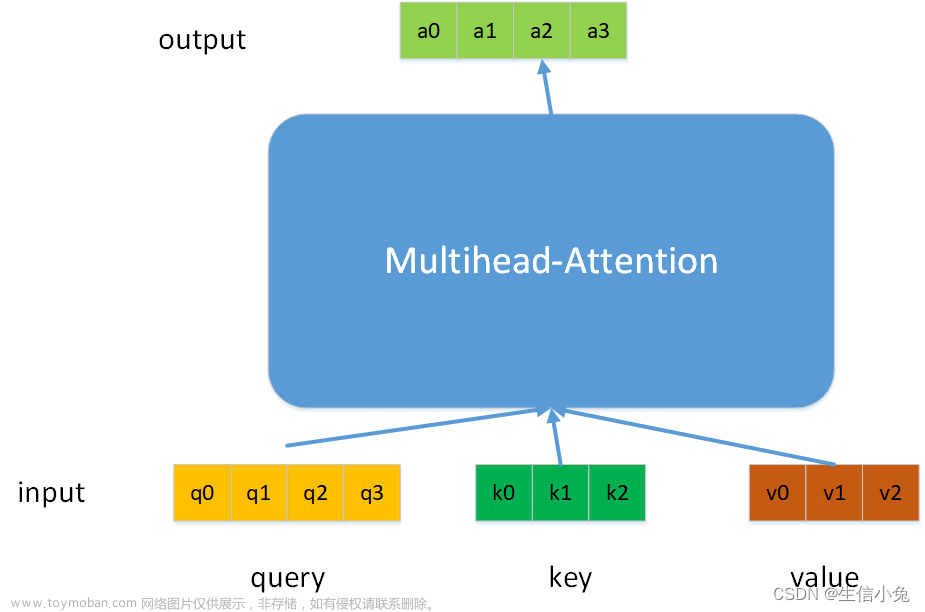
1.Cross attention概念
- Transformer架构中混合两种不同嵌入序列的注意机制
- 两个序列必须具有相同的维度
- 两个序列可以是不同的模式形态(如:文本、声音、图像)
- 一个序列作为输入的Q,定义了输出的序列长度,另一个序列提供输入的K&V
- ps:不知道QKV的先去普及一下Attention的基础、更专业的学习资源here吧!
2.Cross-attention vs Self-attention
Cross-attention的输入来自不同的序列,Self-attention的输入来自同序列,也就是所谓的输入不同,但是除此之外,基本一致。
具体而言,
self-attention输入则是一个单一的嵌入序列。
Cross-attention将两个相同维度的嵌入序列不对称地组合在一起,而其中一个序列用作查询Q输入,而另一个序列用作键K和值V输入。当然也存在个别情况,在SelfDoc的cross-attention,使用一个序列的查询和值,另一个序列的键。总而言之,QKV是由两序列拼凑的,不单一。
3.Cross-attention算法
- 拥有两个序列S1、S2
- 计算S1的K、V
- 计算S2的Q
- 根据K和Q计算注意力矩阵
- 将V应用于注意力矩阵
- 输出的序列长度与S2一致
4.Cross-Attention 案例-感知器IO

感知器IO是一个通用的跨域架构,可以处理各种输入和输出,广泛使用交叉注意:文章来源:https://www.toymoban.com/news/detail-443659.html
- 将非常长的输入序列(如图像、音频)合并到低维潜在嵌入序列中
- 合并“输出查询”或“命令”来解码输出值,例如我们可以让模型询问一个掩码词
这样做的好处是,通常可以处理很长的序列。层次感知器能够处理更长的序列,将它们分解成子序列,然后合并它们。层次感知器也学习位置编码与一个单独的训练步骤,重建的损失。文章来源地址https://www.toymoban.com/news/detail-443659.html
到了这里,关于【科研】浅学Cross-attention?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!