目录
前言
课题背景和意义
实现技术思路
一、协同过滤算法的概念
二、旅游景点推荐系统设计与实现
三、总结
实现效果图样例
最后
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯毕业设计-基于协同过滤算法的旅游推荐系统
课题背景和意义
随着互联网技术的飞速发展和信息资源的日益丰富, 信息量的增长速度远远超过了我们所能处理的速度。如何 在如此庞大的信息量中找出我们感兴趣的信息是非常困 难的。推荐系统的研究和发展已经成为电子商务行业中不 可缺少的方法。它能够通过对用户的历史行为数据进行分 析找到用户比较感兴趣的商品或项目,达到对用户实现个 性化的推荐的目的。其中,使用协同过滤算法是推荐系统 中应用最成功、应用最广泛的技术之一。它的主要特点是 不依赖于产品的内容,而是完全取决于一类用户所表达的 喜好。 目前旅游行业信息化程度越来越高,各个旅游景点的 相关信息在各类系统中存储的数据量越来越大,用户查找 自己感兴趣的旅游景区信息越来越困难。在旅游行业 使用推荐系统进行各种信息的推荐方法还没有广泛使用, 旅游景区网站或主流的旅游网只提供旅游景点信息发布、 查询以及实现了在线旅游景点门票的购买服务等,而对旅 游景区景点、促销等服务的推荐工作还没有广泛的应用, 为此本文将推荐算法应用于旅游景区的推荐服务中。
实现技术思路
一、协同过滤算法的概念
协同过滤算法是推荐算法中比较经典常用的一种,它 主要包括基于内存的协同过滤和基于模型的协同过滤两 种算法。前者主要根据用户的历史数据进行相关的推荐, 它使用领域的方法又可以分为基于用户的协同过滤算法 和基于项目的协同过滤算法。
基于内存的协同过滤算法
基于内存的协同过滤算法一般采用最近邻方法,该算 法首先利用用户的历史偏好信息来计算出用户之间的距 离,其次利用目标用户的邻居用户对产品的评价的加权值 来预测目标用户对特定产品的偏好。推荐系统根据偏好程 度推荐目标用户。该方法包括基于用户的协同过滤算法和 基于项目的协同过滤算法。基于用户的方法根据用户之 间的评分行为的相似性来预测用户的评分。这两种方法 的原理是不同的,因此在不同的应用场景下,它们的表现 也不同。
1、基于用户的协同过滤算法
基于用户的协同过滤(User-based CF)主要思想是以 往具有相似评分的用户应该具有相似的兴趣,这样就可以 根据相似用户评分数据估算目标用户对某一项目的未评 分数据值,原理示例如图 所示。

在图中,箭头指向用户 指向该项目表示用户喜欢引用该项目,并且该项目指向用户代表以向目标用户推荐该项目。对于这三个用户,用户 A 和用户 C 喜欢 A 项和 C 项在一起,而用户 B 的偏好与 其他两个用户相交不大,因此我们可以得到用户 A 和用 户 C 的兴趣偏好相似,因此根据推荐原则,用户 C 喜欢但 用户 A 没有评分的 D 项可以推荐给用户 A。
2、基于项目的协同过滤算法
而基于项目的协同过滤算法(Item-basing CF)根据项 目考虑问题,但算法本身并不是根据项目本身的特性来判 断项目之间的相似性,而是通过用户行为来判断项目之间 的相似性。如图所示,用户 A 和用户 C 首选的项目中的 公共项目是项目 A 和项目 D。根据算法本身的原理,可以 得到 A 项与 D 项相似,因此与 A 项相似的 D 项可以在用 户 B 喜欢 A 项时相对推荐。

基于模型的协同过滤算法
基于模型的协同过滤算法和基于内存的协同过滤算 法有着本质区别。前者倾向于在寻找关联的协作邻居用户 之前建立模型(建立用户浏览、点击、购买等信息的综合用 户偏好模型),将模型与协作邻居用户进行比较,预测用户 的偏好,将项目集合划分为多个模块,根据用户的模型,对 协作邻居用户的模块单元进行分类,筛选出与用户模型最 匹配的模块集,并向用户推荐内容。它使用机器学习和数 据挖掘技术从训练数据中确定模型,并使用模型来预测未 知的商品得分。常见的模型有聚类模型、贝叶斯模型、矩阵 分解等。
聚类算法广泛应用于多个研究领域。在使用聚类算法的推荐系统 中,系统会将相似兴趣的用户或相似特征的物品聚集到同 一类簇之中,相似度计算在目标对象最终所属的类簇中进 行,同样基于相似度由高到低的规则在所属类簇中选取邻 近集合,形成最终的推荐。除了使用聚类模型外,通常还可 以使用贝叶斯模型、矩阵分解、回归模型等来快速预测用 户在某个项目上对应的评分。

基于协同过滤的旅游推荐系统
在基于协同过滤的旅游推荐系统中,主要通过计算各 个项目之间的相似度,根据用户之间的相似度对项目进行 预测。主要利用“用户-项目评分矩阵”进行推荐。旅游推荐 系统主要针对用户信息和景区信息进行计算。基于用户信 息主要从历史用户数据中寻找与其爱好相似、兴趣相投的 用户,找到相似用户集之后,通过分析这些历史用户的历 史行为来挖掘他们的其他喜好和行为信息,并根据这些信 息来完成对目标用户的喜好和行为预测给出推荐。
二、旅游景点推荐系统设计与实现
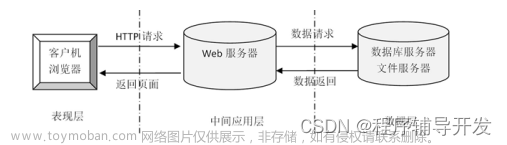
总体架构设计
该系统充分利用景区旅游资源,为游客提供特色旅游 服务,是实现个性化信息服务的有效手段。系统采用协同 过滤算法为核心部分,根据用户的需求信息和产生的历史 记录,向游客推荐符合用户需求的旅游资源信息。采用基 于数据库的方式实现以网络技术为核心的 B/S 模式,设计 了业务应用层、模型层和数据采集层三个结构层次。系统 结构层次如表所示。

主要功能
该旅行推荐系统使用 Struts 来实现视图层和控制器 层之间的交互,而 Hibernate 用于数据持久化。前台页面使 用 JSP 技术来制作,后台系统使用 JAVA 语言来实现,推 荐算法部分用 python 脚本来实现,服务器采用 tomcat, MySQL 为数据库。

推荐系统算法的实现
系统中推荐系统算法采用基于用户 (User-based)的 协同过滤算法。其主要思想是首先在用户集合中寻找与目 标用户的爱好相似相近的相邻用户,接着使用目标用户的 相邻用户对目标项目的评分来预测目标用户对目标项目 的评分。其算法流程图如图所示。

算法的核心部分执行的具体步骤如下: ①查找相邻用户 N:首先计算目标用户与其他用户的 相似度,相似度计算方法有很多种,常用的有皮尔逊 (Pearson)相关系数, 杰卡德(Jaccard)相似度以及余弦相 似度几种传统的方法。算法中采用皮尔逊相关系数 (Pearson)用来衡量旅游景点、用户之间的线性相关程度, 取值范围在 1 和-1 之间。皮尔逊相关系数的计算如公式所示。

其中,Xi 表示用户 X 对景区 i 的评分,Yi 表示用户 Y 对项目 i 的评分,X !表示用户 X 所有评分的平均值,Y !表示用户 Y 所有评分的平均值。
其次从中选择相似度大于预定阈值的用户作为目标 用户的相邻用户。
②得分预测:用户 u 对景区 s 的预测公式如下:

其中 U 为目标用户 u 在景区 s 上有得分且相似度超 过一定阈值的相邻用户集合,v 为其中一个邻近用户,rv,s 为用户 v 对景区 s 的评分,rv 为用户 v 的平均评分。
③推荐阶段:在预测目标用户对所有未评级景区的得 分后,可采用 Top-K 方法将得分值最高的 K 个景区推荐 给相应的用户。
三、总结
目前旅游行业信息化程度越来越高,各个旅游景点的 相关信息在各类系统中存储的数据量越来越大,本文将推 荐算法应用于旅游景区的推荐系统中,提出了一种基于协 同过滤算法的旅游信息推荐系统。该系统给用户提供更加 个性化和人性化的旅游线路推荐,同时,也为旅游景区加 强景区服务质量,提升旅游景区的品质起到了促进作用。
实现效果图样例
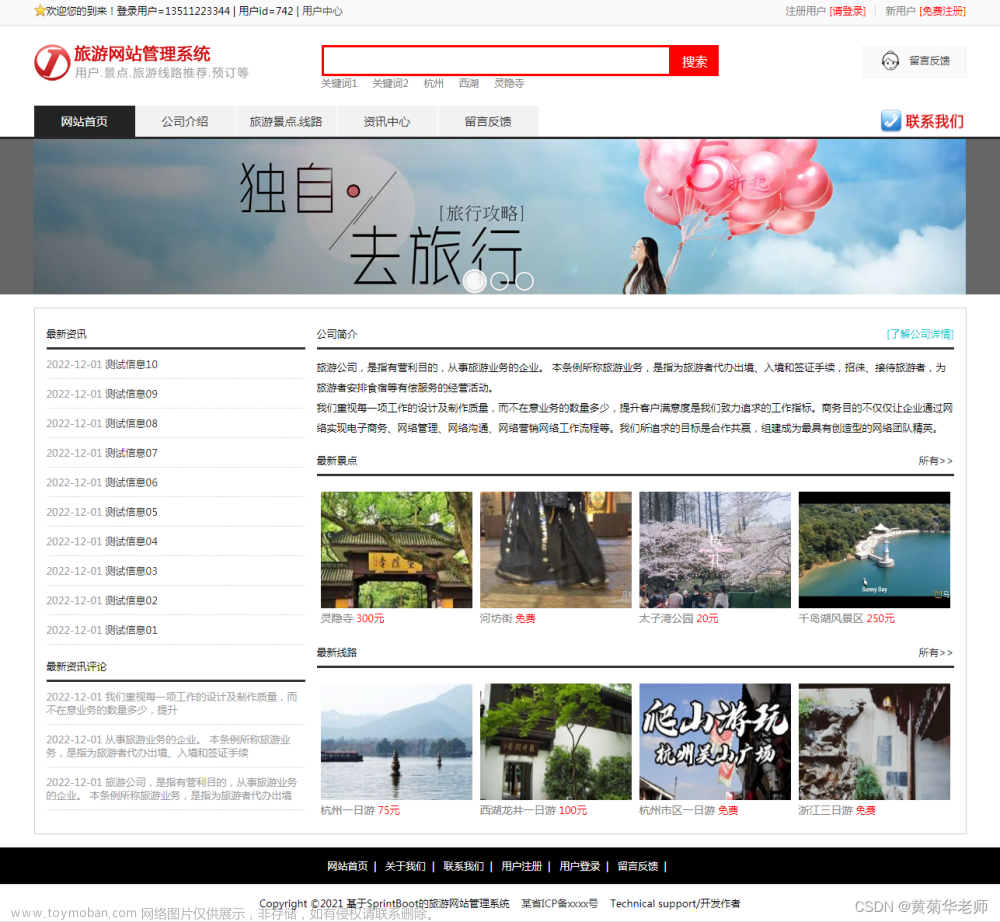
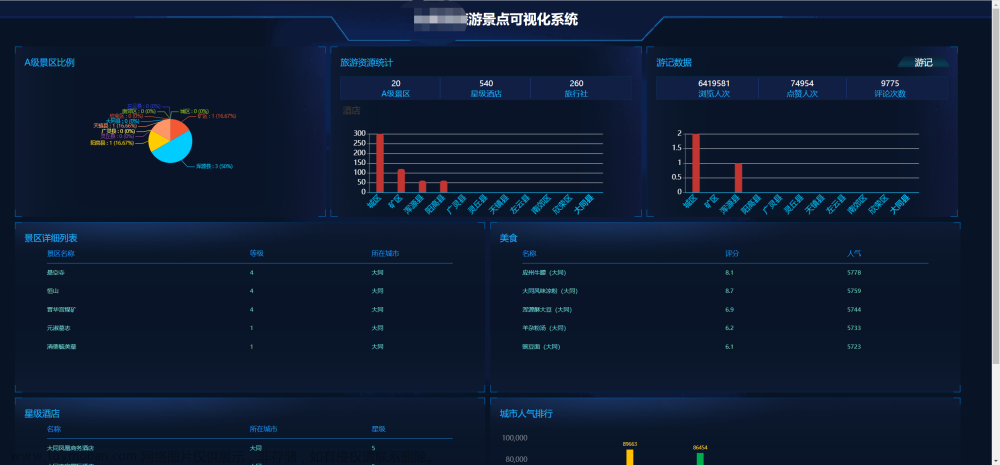
旅游推荐系统:

我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。文章来源:https://www.toymoban.com/news/detail-443894.html
毕设帮助,疑难解答,欢迎打扰!文章来源地址https://www.toymoban.com/news/detail-443894.html
最后
到了这里,关于毕业设计-基于协同过滤算法的旅游推荐系统的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!