HDFS 的Java API操作
1、环境搭建
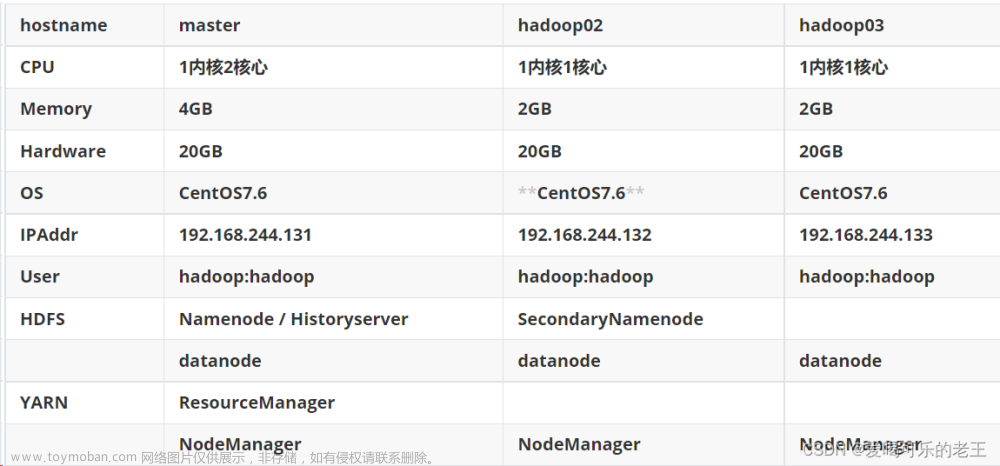
基于Linux的Hadoop(2.7.4)集群
windowsp平台的hadoop
JDK
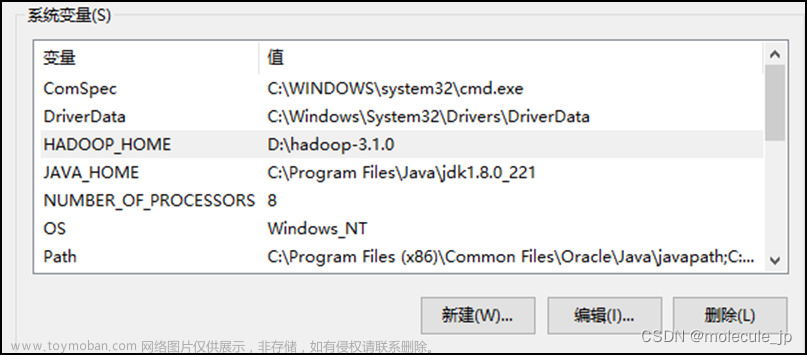
hadoop和jdk的环境变量
IDEA
2、下载windowsp平台的hadoop,版本要与Linux下的一致
可以使用下载的Linux平台的Hadoop解压。然后在/bin目录下添加Windows相关依赖winutils.exe、winutils.pdb、hadoop.dll
然后在目录hadoopwhadoop-2.7.4etchadoop下更改Java路径
注意:要把C:Program Files 目录该为PROGRA1,因为PROGRA1是 C:Program Files 目录的dos文件名模式下的缩写 。长于8个字符的文件名和文件夹名,都被简化成前面6个有效字符,后面~1,有重名的就 ~2
set JAVA_HOME=C:Program FilesJavajdk-16.0.2
set JAVA_HOME=C:PROGRA~1Javajdk-16.0.2

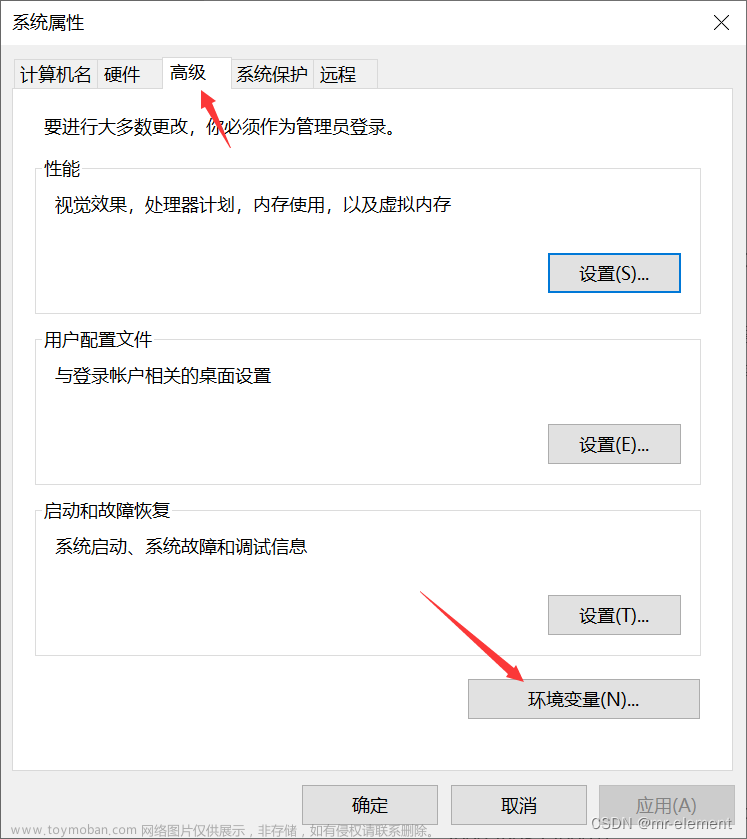
3、环境变量配置
此电脑右键属性–>高级系统设置–>环境变量
系统环境变量,添加(不能有空格) 找到
找到path,编辑 测试一下如下成功:
测试一下如下成功:
4、打开IDEA创建一个Maven工程 下一步,下一步,完成就行
下一步,下一步,完成就行
5、在pom.xml配置文件中引入hadoop-common、hadoop-hdfs、haddop-client3中依赖,同时引入junit的单元测试包:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>hdfs-api</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>16</maven.compiler.source>
<maven.compiler.target>16</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
</dependencies>
</project>
添加相关依赖后,Hadoop相关包就会自动下载:
6、初始化客户端对象
public class HDFS_CRUD {
FileSystem fs = null;
@Before
public void init() throws Exception{
Configuration conf=new Configuration();
conf.set( "fs.defaultFS", "hdfs://hadoop01:9000");
System.setProperty("HADOOP_USER_NAME","root");
fs = FileSystem.get(conf);
}
7、上传文件,先准备一个要上传的文件
上传文件:
// 上传文件
@Test
public void upload() throws Exception{
//要上传的文件路径
Path src=new Path("D:/1.txt");
//上传到HDFS的目标路径
Path dst=new Path("/testFile");
fs.copyFromLocalFile(src,dst);
fs.close();
}
执行
执行结果:
上传文件成功: 打开看一下,是前面我们编辑好的1.txt内容
打开看一下,是前面我们编辑好的1.txt内容
8、下载文件到本地:
@Test
public void testDownloadFileToLocal() throws IllegalArgumentException,IOException{
fs.copyToLocalFile(new Path("/wordcount/input/word.txt"),new Path("E:/hadoopw"));
fs.close();
}
 9、目录操作:
9、目录操作:
@Test
public void catalogOperration() throws Exception{
//创建目录
fs.mkdirs(new Path("a/b/c"));
fs.mkdirs(new Path("a2/b2/c2"));
//重命名文件或文件夹
fs.rename(new Path("testFile"),new Path("521.txt"));
//删除文件夹
fs.delete(new Path("/a2"),true);
}

10、查看目录中的文件信息:文章来源:https://www.toymoban.com/news/detail-444064.html
// 打印指定路径下的文件信息
@Test
public void listFile() throws FileNotFoundException, IllegalArgumentException, IOException{
// true表示是否递归 返回的是迭代器对象
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while(listFiles.hasNext()){
LocatedFileStatus file = listFiles.next();
System.out.println("owner:"+file.getOwner());
System.out.println("filename:"+file.getPath().getName());
System.out.println("blocksize:"+file.getBlockSize());
System.out.println("replication:"+file.getReplication());
System.out.println("permission:"+file.getPermission());
BlockLocation[] blockLocations = file.getBlockLocations();
for (BlockLocation b : blockLocations) {
System.out.println("块的起始偏移量:"+b.getOffset());
System.out.println("块的长度:"+b.getLength());
String[] hosts = b.getHosts();
for (String host : hosts) {
System.out.println("块所在的服务器:"+host);
}
}
System.out.println("=========================================");
}
}
程序运行结果: 文章来源地址https://www.toymoban.com/news/detail-444064.html
文章来源地址https://www.toymoban.com/news/detail-444064.html
到了这里,关于HDFS 的Java API操作的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!