第一部分:被动信息收集
1、简介
在信息收集这块区域,我将其分为两部分:第一部分即被动信息收集,第二部分即主动信息收集。
对于标准的渗透测试人员来说,当明确目标做好规划之后首先应当进行的便是信息收集,那么在收集的过程中就需要考虑是否应该被目标发现。对于企业安全管理来说,他会无时无刻的监管着企业的服务器,保持企业的正常的运行,所以当如果企业的服务器出现异常访问、或者大量的信息请求等等不是正常的流量的情况下,企业的安全运维人员便会对访问者即使作出应急响应,比如:限制访问次数、拒绝响应请求、封锁IP等等。那么这无疑会增大渗透测试者的攻击难度,为了避免这种情况的发生,最好的办法就是在此之前避免与之直接交互先收集足够的信息,不被目标发现,当我们无法再收集有用的信息之后,主动收集便是我们才要进行的步骤。
当然,在被动信息收集的时候,我们应当注意被动信息收集的三个基本要求:
- 公开渠道可获得的信息
- 与目标系统不产生直接交互
- 尽量避免留下一切痕迹
总之一句话,被动信息收集的过程中,保持最大的隐蔽性,防止目标发现,不予目标产生直接的交互,也可以理解为,在目标看来一切的收集过程都是正常的访问过程。
2、信息收集的内容
在这一阶段,信息收集的内容可能会很多,例如:
IP地址段、域名信息、邮件地址、文档图片数据、公司地址、公司组织架构、联系电话/传真号码、人员姓名/职务、目标系统使用的技术架构、公开的商业信息等等。
上面所说的内容,仅仅只是我们常用的一些内容,在这一阶段,针对目标所有的一些信息都可能成为我们利用的信息。有一点很重要,对于一个良好的渗透测试人员来说,没有什么信息是没有用处的,如果有,那就是可能漏了什么。
3、信息收集的用途
当我们收集到信息之后,我们的信息是很杂乱的,那么这就需要对这些信息做一些整理,例如:
域名查询到的信息为一类,具体到可为:
子域名
真实IP
...
各种搜索引擎查询到的信息为一类,如:
- Google hacking
- fofa
- ZoomEye
- shodan
DNS解析记录(whois)查询为一类,如:
域名所有者的姓名
联系人电话
邮箱地址
...
当然,实际情况并不是像上面一样一个一个列,一个一个记录,在真实的渗透测试信息收集环境中,一般不会是独自完成,那么这样收集的信息就会更乱,所以,很多时候都会用到信息统计工具,将我们所收集的信息分类录入上去,这样,团队信息收集完成后,这样的信息便会一目了然。
对我们来说,我们的目的是利用收集的信息,所以当对我们手中所掌握的信息有了一个足够的了解之后,我们就应该开始进行信息利用了,那么实际情况中信息利用的方向就很广,并不局限。
例如以下用途:
1、用信息描述目标:
这个目标的真实IP地址是什么,它具有的子域名有什么,曾经是否发生过信息威胁记录等等。
2、发现:
目标网站的技术框架是什么、哪个版本、目标时候具有防火墙或者CDN、C段查询、站点真实IP对应的开放端口有哪些,提供什么服务等等。
3、社会工程学攻击:
在一些DNS解析中,可能会收集到目标站点的注册者的相关信息,那么有了这些信息,通常就会利用邮件钓鱼等方式。
注:请在目标用户的许可和符合法律的情况之下进行,否则切勿操作。
4、物理缺口:
这种利用就不再是网络操作而已,更多的就是实地考察等。
4、二级域名或IP收集
1).DNS信息收集
dns信息收集的意义:dns信息中包含了很多对渗透人员来说有用的信息,这些信息能为接下来的渗透行为提供思路,比如攻击dns服务器、域名劫持、子域渗透等。对渗透目标进行dns信息的收集通常是被动的形式,不会对被渗透目标产生影响也不会在被渗透目标上留下任何痕迹。
dns需要收集的信息:
A记录:记录域名和服务器的对应关系
cname记录:别名记录,把一个域名解析到另一个域名
ns记录:记录解析该域名的dns服务器
mx记录:邮件交换记录,对应邮件服务器
txt记录:一般为验证记录
bind信息:域名服务器所使用的bind版本信息
这里说明两个工具:nslookup、dig、dnsenum
新版kali不再包含nslookup工具,需要使用如下命令:
apt-get install bind9-utils
利用nslookup
这里能看到域名解析之后的CName以及对应的IP地址,下面再举几个例子:
通过这几个域名的解析我们能够看到DNS解析后能够得到的IP地址,如果在以前可能这就是真实的IP地址,但现在来说一般企业都会用到CDN加速自己的网站,那么这样解析得到的IP地址就变得作用甚微,因为CDN就像类似代理一样,你并不知道目前获得的IP地址是否是真实的IP地址,比如:
多次进行:nslookup 域名、ping 域名
能够清楚的看到,这一次的解析与上一次的解析完全不同,这就是做了CDN的网站,那么如何绕过这种CDN找到真实的IP地址呢?稍后会说明
补充:我这里用到百度对应的域名服务器的IP地址119.29.29.29且对应的服务端口号就是53端口(DNS服务的通信端口),那么对于一个服务器来说,53端口的开放就能做到很多事,比如像利用DNS53端口绕过校园网认证 (百度就别想了)。有关端口的一些利用和所对应的服务并不在这里详述。
当然,nslookup并不是只有此用法,还有如获取不同类型的记录,a、mx、ns、any等。
更多的可用法可以使用man nslookup查询。
利用dig
上面已经描述了相关的DNS解析,那么这里就直接说明工具的用法了。
用法:
dig @server name type
这里用Google的DNS服务器去解析百度的mx记录,效果如下:
解析百度any:
dig能够反向查询DNS服务器的IP地址,如:
dig能够进行DNS追踪,如:(这里的dig查询过程是值得探究的,至于具体的可以抓包⽐比较递归查询、迭代查询过程的区别)
2).DNS域传送漏洞
这里会用到三个工具:dnsenum、dig、host
dnsenum是一款强大的域名信息收集工具,它除了能查询常用的dns记录外,还能使用google搜索和使用字典爆破子域名。
Dns是整个互联网公司业务的基础,越来越多的互联网公司开始自己搭建DNS服务器做解析服务,同时由于DNS服务是基础性服务非常重要,因此很多公司会对DNS服务器进行主备配置而DNS主备之间的数据同步就会用到dns域传送,但如果配置不当,就会导致任何匿名用户都可以获取DNS服务器某一域的所有记录,将整个企业的基础业务以及网络架构对外暴露从而造成严重的信息泄露,甚至导致企业网络被渗透。
如果存在,不仅能搜集子域名,还能轻松找到一枚洞,这样子的好事百试不厌。
利用dig
利用host
也可以利用host去进行域传送漏洞查询:
利用dnsenum
dnsenum工具可以获取dns域中的域名,如:
dnsenum参数说明:
` -h 查看工具使用帮助
--dnsserver 指定域名服务器
--enum 快捷选项,相当于"--threads 5 -s 15 -w"
--noreverse 跳过反向查询操作
--nocolor 无彩色输出
--private 显示并在"domain_ips.txt"文件结尾保存私有的ips
--subfile 写入所有有效的子域名到指定文件
-t, --timeout tcp或者udp的连接超时时间,默认为10s(时间单位:秒)
--threads 查询线程数
-v, --verbose 显示所有的进度和错误消息
-o ,--output 输出选项,将输出信息保存到指定文件
-e, --exclude 反向查询选项,从反向查询结果中排除与正则表达式相符的PTR记录,在排查无效主机上非常有用
-w, --whois 在一个C段网络地址范围提供whois查询
-f dns.txt 指定字典文件,可以换成 dns-big.txt 也可以自定义字典`
3).备案号查询
在我国,每一个网站都会进行备案,那么在同一个备案号下就可能查到其他的相关公司域名。
http://www.beianbeian.com、http://icp.bugscaner.com/
以CSDN为例:
上面就能清楚的看到在这个备案号下面还有多少域名,然后做出相关域名收集整理
4).SSL查询
目前一般的企业站点都会具备HTTPS协议的能力,那么通过这一项也能查找出一些相关的子域名。
SSL状态检测
例如:
5).APP提取(可能)
在这一个内容中,前提就是目标站点具有安卓app,如果没有,那么就只能忽略。同时,现在很多app都会具有加壳手段,那么直接反编译就不再具备效果,需要脱壳处理,前提是具有汇编和逆向的能力;如果没有加壳技术,那么这就是一个很好的查找子域名的思路,毕竟APP里面有大量的接口IP和内网 IP,可以获取不少安全漏洞。
这里就不再详细举例子介绍了,如果有去壳的app那么就可以用反汇编工具尝试一下,像AndroidKiller反编译工具等。
6).微信公众号
如果目标具有相关公众号,那么渗透相关公众号,绝对会有意外收获,比如获取不少漏洞+域名,可以参考 Burp APP抓包抓取微信公众号数据。
7).暴力破解/字典枚举
所谓暴力破解即利用一个已经生成的数字组合不断尝试与目标匹配,直到找出相符的目标单位。
暴力破解可以用很多工具,如DNSReconcile、Layer子域名挖掘机、DirBuster、fierce、dnsdict6、dnsenum、dnsmap、dnsrecon、等等
下面举个几个例子,同时这里的字典就用工具自带的字典了。
用Demon:
利用dnsdict6
安装:dnsdict6
`https://src.fedoraproject.org/lookaside/pkgs/thc-ipv6/thc-ipv6-2.7.tar.gz/2975dd54be35b68c140eb2a6b8ef5e59/thc-ipv6-2.7.tar.gz
tar -zxvf thc-ipv6-2.7.tar.gz
cd thc-ipv6-2.7/
apt-get install -y libpcap-dev libssl-dev
make
cp dnsdict6 /usr/bin/
dnsdict6`
利用dnsenum
8).DNS历史记录解析
像这种历史记录解析,一般都可以查到以前域名拥有着的相关信息,例如:
注:像通常所谓的钓鱼攻击,一般都会去收集这些历史信息。
9).威胁情报查询
像华为、360都拥有威胁情报查询的能力:360威胁情报中心
比如以前站点出现过哪些漏洞、相关内容,都可能在情报中查到:
10).证书序列号获取域名与IP
一个网站都会具有相关的证书,那么对证书的序列号进行查询,也会有意外的收获:
转为十进制后,就可以用fofa去搜一搜:
11).搜索引擎(重点)
在信息收集中,搜索引擎能够提供给我们很大的帮助,几乎很大的程度的帮助都来自于搜索引擎,而普遍的搜索引擎有:
- shodan
- fofa
- ZoomEye(知道创宇)
还有很多好用的搜索引擎就不再多介绍了这里就说说常用的搜索引擎。
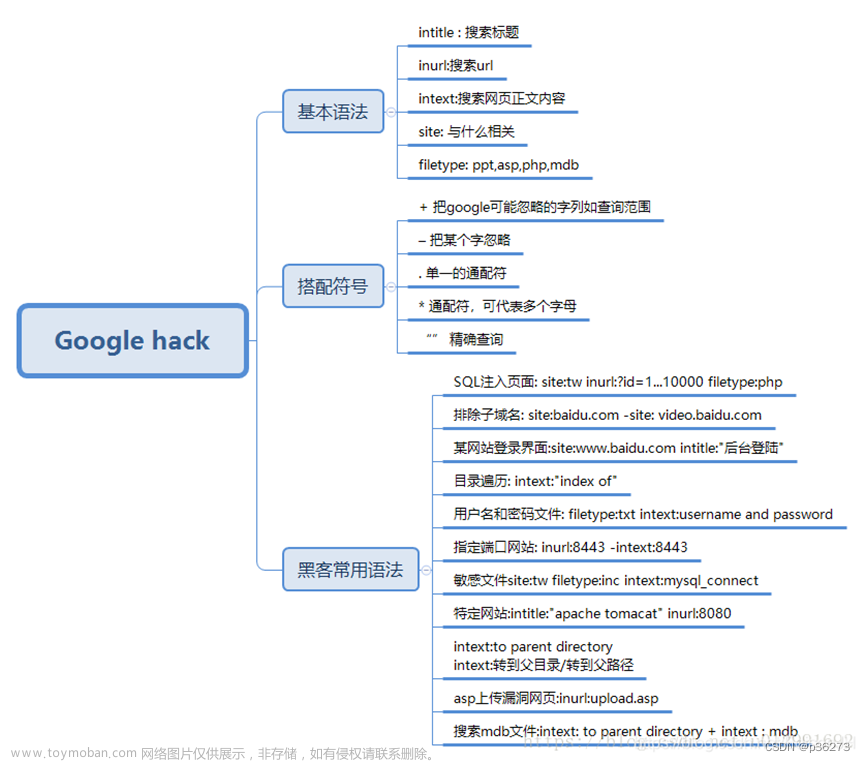
一般使用Google进行搜索的话,也叫Googlehacking,简单说明几个例子,关于搜索引擎的用法其实有很多,可以任意搭配,不可能说的完。
1、搜索含有管理员登录页面的URL
语法:inurl:/admin/login.php
2、搜索文件类型为xls且包含username、password字段的内容
语法:filetype:xls "username | password"
3、搜索含有充值字符没有支付制服的页面
语法:+充值 -支付
关于Google搜索引擎的用法,可以去https://www.exploit-db.com/google-hacking-database这个页面浏览,然后根据自己情况写出适合自己的。
shodan
据说shodan是一个很强大的搜索引擎,用于搜索联⽹的设备,传言只要有联网的设备都会被搜索到,其原始开发者有msf框架的开发者参与。
Shodan Search Engine
常见的过滤规则就是:
net、city、country、port、os、hostname
语法比如:os:windows country:CN city:neijing
语法可以自己构造,也可以参考:https://www.shodan.io/explore看看别人怎么构造语句的。
fofa
https://fofa.so/
想必到了这里搜索引擎的语句构造就不需要再赘述了,那么简单说两个例子:
1、查询C段
ip="10.0.0.0/24"
2、查询网站名(可列出钓鱼网站)
title="网站名"
其他的可以自行参考文档:https://fofa.so/help
`查询语法
直接输入查询语句,将从标题,html内容,http头信息,url字段中搜索
title="abc" 从标题中搜索abc。例:标题中有北京的网站
header="abc" 从http头中搜索abc。例:jboss服务器
body="abc" 从html正文中搜索abc。例:正文包含Hacked by
domain="qq.com" 搜索根域名带有qq.com的网站。例: 根域名是qq.com的网站
host=".gov.cn" 从url中搜索.gov.cn,注意搜索要用host作为名称。例: 政府网站, 教育网站
port="443" 查找对应443端口的资产。例: 查找对应443端口的资产
ip="1.1.1.1" 从ip中搜索包含1.1.1.1的网站,注意搜索要用ip作为名称。例: 查询IP为220.181.111.1的网站; 如果想要查询网段,可以是:ip="220.181.111.1/24",例如查询IP为220.181.111.1的C网段资产
protocol="https" 搜索指定协议类型(在开启端口扫描的情况下有效)。例: 查询https协议资产
city="Hangzhou" 搜索指定城市的资产。例: 搜索指定城市的资产
region="Zhejiang" 搜索指定行政区的资产。例: 搜索指定行政区的资产
country="CN" 搜索指定国家(编码)的资产。例: 搜索指定国家(编码)的资产
cert="google" 搜索证书(https或者imaps等)中带有google的资产。例: 搜索证书(https或者imaps等)中带有google的资产
banner=users && protocol=ftp 搜索FTP协议中带有users文本的资产。例: 搜索FTP协议中带有users文本的资产
type=service 搜索所有协议资产,支持subdomain和service两种。例: 搜索所有协议资产
os=windows 搜索Windows资产。例: 搜索Windows资产
server=="Microsoft-IIS/7.5" 搜索IIS 7.5服务器。例: 搜索IIS 7.5服务器
app="HIKVISION-视频监控" 搜索海康威视设备,更多app规则。例: 搜索海康威视设备
after="2017" && before="2017-10-01" 时间范围段搜索。例: 时间范围段搜索,注意: after是大于并且等于,before是小于,这里 after="2017" 就是日期大于并且等于 2017-01-01 的数据,而 before="2017-10-01" 则是小于 2017-10-01 的数据
asn="19551" 搜索指定asn的资产。例: 搜索指定asn的资产
org="Amazon.com, Inc." 搜索指定org(组织)的资产。例: 搜索指定org(组织)的资产
base_protocol="udp" 搜索指定udp协议的资产。例: 搜索指定udp协议的资产
is_ipv6=true 搜索ipv6的资产,只接受true和false。例: 搜索ipv6的资产
is_domain=true 搜索域名的资产,只接受true和false。例: 搜索域名的资产
ip_ports="80,443" 或者 ports="80,443" 搜索同时开放80和443端口的ip资产(以ip为单位的资产数据)。例: 搜索同时开放80和443端口的ip
ip_ports"80,443" 或者 ports"80,443" 搜索同时开放80和443端口的ip资产(以ip为单位的资产数据)。例: 搜索只开放80和443端口的ip
ip_country="CN" 搜索中国的ip资产(以ip为单位的资产数据)。例: 搜索中国的ip资产
ip_region="Zhejiang" 搜索指定行政区的ip资产(以ip为单位的资产数据)。例: 搜索指定行政区的资产
ip_city="Hangzhou" 搜索指定城市的ip资产(以ip为单位的资产数据)。例: 搜索指定城市的资产
ip_after="2019-01-01" 搜索2019-01-01以后的ip资产(以ip为单位的资产数据)。例: 搜索2019-01-01以后的ip资产
ip_before="2019-01-01" 搜索2019-01-01以前的ip资产(以ip为单位的资产数据)。例: 搜索2019-01-01以前的ip资产
高级搜索:可以使用括号 和 && || !=等符号,如
title="powered by" && title!=discuz
title!="powered by" && body=discuz
( body="content="WordPress" || (header="X-Pingback" && header="/xmlrpc.php" && body="/wp-includes/") ) && host="gov.cn"
新增完全匹配的符号,可以加快搜索速度,比如查找qq.com所有host,可以是domain"qq.com"
关于建站软件的搜索语法请参考:组件列表
`
ZoomEye
ZoomEye - Cyberspace Search Engine
相关搜索语句可以见帮助然后自行构造。
12).JSFinder
这里的方法就是利用开源的Python脚本,从js文件里面提取二级域名以及ip。
参考:GitHub - Threezh1/JSFinder: JSFinder is a tool for quickly extracting URLs and subdomains from JS files on a website.
13).用户信息收集
这里利用的theharvester与metagoofil工具对用户的一些信息进行搜集,例子:
theharvester -d sina.com -l 300 -b google
metagoofil -d baidu.com -t pdf -l 300 -o test -f test.html
其他的参数可以查看手册:man
14).MELTAGO
这是一个非常好用的域名、ip等等信息收集的工具,既可以在linux上运行,也可以在Windows上运行,举个例子:
15).C段旁站
什么是旁站?旁站是和目标网站在同一台服务器上的其它的网站。
什么是C段?C段是和目标服务器ip处在同一个C段的其它服务器。
旁站
旁站指的是网站所在服务器上部署的其他网站
旁注的意思就是从同台服务器上的其他网站入手,提权,然后把服务器端了,就自然把那个网站端了
C段
C段指的是例如192.168.1.4,192是A段,168是B段,1是C段,4是D段
C段嗅探指的是拿下同一C段下的服务器,也就是说是D段1-255中的一台服务器
即:
旁注:同服务器不同站点的渗透方案
C段:同网段不同服务器的渗透方案
C段/旁站(前提条件要获取到网站的真实ip)即:当知晓目标真实IP后;一般来说主页面很难存在可利用点,那么这时候就可以通过嗅探此IP段内其他的主机服务器来实现C段利用,或者从此服务器上的其他网站入手。
像ARP攻击等。
那么下面就会用到一些工具,如搜索引擎或者工具扫描:
上面已经说了shodan、fofa、ZoomEye等扫网段,那么下面就说两个例子工具:
总结
1、网站域名有没有CDN,CND是做网站加速的,也是间接的隐藏了真实IP地址的作用的,真实IP在CND之后。(相当于网站"代理")
判断CND方法:ping、dns解析等查看有没有双重.com或者ip变换就能知道有没有CDN
绕过CDN:fofa引擎(title="网站标题")、有CDN可采用国外节点ping测试,或者就是shodan引擎、包括它的插件。还有子域名,DNS历史解析,邮件、SSL证书签名,网站ico等方法绕过CDN2、没有DNS区域传送漏洞如何获取二级域名?
证书查找:通过有没有https(SSL证书)什么的反推
备案号查找:通过备案号反推二级域名3、APP中去壳反编译可提取到内网的地址,做后期的内网IP确定
4、暴力破解中,泛域名解析会规避暴力破解,暴力几乎无效
5、DNS解析直接取公网IP,DNS记录(域名反查)
6、fofa比zoomeye强一些,fofa通过title标签能够绕过CDN拿到真实IP,或者证书的序列号前去查询
7、C段搜集,就是通过一个(必须真实的)ip查找这个ip的网段里面其他ip有没有能够收集的漏洞等,通过fofa就是ip="ip.0/24"(主要就是C段了)
8、威胁情报查询:有如历史whois的信息中可能有QQ、手机号等信息然后钓鱼攻击
(通过域名查真实IP地址,C段漏洞搜集、扫端口服务,)9、具有CND的域名使用whois是查不出来的,但是能够查到这个CDN下有哪些域名
10、本网站的友情链接中如果那些网站有的被挂马了,那么在本网站中点击被挂马的网站,那么就相当于本网站被挂马了。(这就是API调用出的问题)
5、敏感信息收集
在这一部分中我们主要就是收集的关于一些泄露的信息,即我能可能直接利用的一些信息,大致将其划为以下内容:
-
WEB源代码泄露(可以用7kb)
在很多时候,一些有关网站的源代码会被上传到相关的网站中,比如github、gitee等等,那么在这些网站中我们就可以对这些泄露的代码进行审计,也许能找到其相关的信息。
比如:.hg源代码泄露、.git源代码泄露、cvs源代码泄露、svn源代码泄露(当然这里的svn现在在扫描器中就能爆出来)、.DS_store文件泄露、网站的备份文件泄露:rar/zip/tar.gz/7z/bak/tar
下面举个例子:
打包了部分代码:
换了一个备份文件字典后,开始扫描
-
github信息泄露
在github上面会存有很多的源码信息,那么如果目标的源码可能存在于上面,那么在github上面输入相应的关键字,也许就能匹配到关于目标的结果,然后分析有没有利用的价值,比如:IP、用户名密码、数据、网站过滤规则等等。
举个例子:
注:与github这样的网站有很多的类似,如:https://searchcode.com/、https://gitee.com/、gitcafe.com、code.csdn.net
-
Google hack
前面已经介绍过了,有关Google的语法需要自行匹配。那么很有可能就爆出一些目标后台的相关内容,可能是数据表等。
无非就是:filetype:xls 或者 filetype:docx等等
-
接口信息泄露
所谓接口信息泄露,无非就是一些程序调用的API导致目标相关的一些数据或者文件内容暴露,那么这就是一个采集点。(有没有能够利用的未授权访问等)
-
社工信息泄露
在这方面的信息泄露,可能就包含了目标的个人信息,像一些普通的社交网站、新闻组、论坛、招聘网等等凡是能够应用到的信息,存在可能进行社工的信息都是可采集点。
比如可以 去天眼查:https://www.tianyancha.com/、https://www.instantcheckmate.com/、http://www.uneihan.com/
-
邮箱地址信息泄露
收集的一般都是目标注册域名时候可能使用的邮箱,有时候会进行钓鱼攻击等方式都需要邮箱等重要信息点。
可以使用theHarvester工进行邮箱收集(一般在引擎、DNS反查等手段中都可能查到。)
-
历史漏洞收集
仔细分析,大胆验证,发散思维,对企业的运维、开发习惯了解绝对是有很大的帮助。可以把漏洞保存下来,进行统计,甚至炫一点可以做成词云展示给自己看,看着看着或者就知道会有什么漏洞。(主要是看一些企业是否有暴露出来的漏洞没有去修补)
wooyun 历史漏洞库:乌云网 – 白帽子丨乌云知识库丨Wooyun丨乌云漏洞平台 、乌云网镜像丨乌云知识库丨Wooyun镜像丨乌云漏洞平台
漏洞银行:BUGBANK 官方网站 | 领先的网络安全漏洞发现品牌 | 开放安全的提出者与倡导者 | 创新的漏洞发现平台
360补天:补天 - 企业和白帽子共赢的漏洞响应平台,帮助企业建立SRC
教育行业漏洞报告平台(Beta)https://src.edu-info.edu.cn/login/
-
其他
微步在线:VirusTotal 、网盘搜索:http://www.pansou.com/或https://www.lingfengyun.com/ 网盘密码破解可参考:提示信息 - 吾爱破解 - LCG - LSG |安卓破解|病毒分析|www.52pojie.cn
6、信息整理
1).指纹识别
所谓指纹识别,即发现当前目标所处的环境框架是什么、哪个版本等,当我们拿到这些信息之后,我们应该做的就是查询这个框架有没有漏洞,曾经出现过什么漏洞,然后我们查找这些漏洞的使用方法,验证目标是否存在这些漏洞,如果打了补丁那么就跳过这个思路,如果没有那么就利用漏洞达成突破。
相关指纹识别的在线站点可以有:
http://whatweb.bugscaner.com/look/
yunsee.cn-2.0
TideFinger 潮汐指纹 TideFinger 潮汐指纹
相关的指纹识别工具:
御剑WEB指纹识别、wappalyzer(浏览器插件)
当然不止这些方法,像我常用的shodan、fofa等也能快速识别:
2).waf识别
所谓的waf识别即安全狗,防火墙,通过检查汇报,可能识别端口是否经过防火墙过滤,即需要对安全狗检测,所使用的工具到https://github.com/EnableSecurity/wafw00f下载下来之后记得在本机安装好py,用py执行python setup.py install 执行完后cd进行C:\wafw00f-master\wafw00f目录,执行main.py www.safedog.cn就可以了。
或者:使用scapy、nmap等工具
nmap有系列防火墙过滤检测功能
nmap -sA 1.1.1.1 -p 22
nmap www.sina.com --script=http-waf-detect.nse
3).CDN识别(绕过,获取真实IP)
1、通过ping一个不存在的二级域名获取真实ip或没有挂cdn的域名
2、通过fofa语法title标签获取真实ip
3、DNS历吏记录
4、在线网站查找:What's that site running? | Netcraft
5、phpinfo(可以忽略):如果目标网站存在phpinfo泄露等,可以在phpinfo中的SERVER_ADDR或_SERVER[“SERVER_ADDR”]找到真实ip。
6、shodan搜索引擎查询
7、挂国外节点再ping目标网站
4).旁注与C段(获取真实IP情况下)
1、站长之家http://stool.chinaz.com/same
2、网络搜索引擎 www.fofa.so、www.shodan.io、www.ZoomEye.org等
3、Nmap,Msscan扫描C段(nmap建议之后主动信息收集的时候使用)
nmap常用说明:
nmap -p 80,443,8000,8080 -Pn 1.1.1.0/24
简单ping扫描探测主机是否在线:nmap -sn 1.1.1.1
采用TCP与UDP端口扫描:nmap -sS -sU 1.1.1.1
–sV 指定版本探测:nmap -sV 1.1.1.1
-O 探测系统类型版本号:nmap -O 1.1.1.1
绕过ping扫描参数为:nmap -Pn 1.1.1.1
漏洞检测可直接:nmap 1.1.1.1--script=auth,vuln
总结:
你平时常去那些网站进行学习:
seebug、cnvd、freebuf、吾爱破解、微信公众号
你平时挖漏洞提交到那些平台:
奇安信补天、cnvd、教育漏洞平台、漏洞银行、wooyun、漏洞盒子众测平台
# 第二部分 主动信息收集
直接与目标系统交互通信
无法避免留下访问的痕迹
使用受控的第三方电脑进行探测
使用代理或已经被控制的主机
做好被封杀的准备
使用噪声迷惑目标,淹没真实的探测流量
扫描
发送不同的探测,根据返回结果判断目标状态
1、二层发现
二层发现是基于ARP协议来进行的探测发现,ARP协议的数据包不可路由,其到达路由端口会被过滤,通过这样的发现能够清晰知道目标是否存活,其优点就是扫描的速度快、结果可靠。
这里用三个工具来说明举例:arping、nmap、Netdiscover
arping //只能ping一个
arping 1.1.1.1 -c 1 //指定一个包
arping 1.1.1.1 -d //-d可以查看是否重复,即ARP欺骗
arping -c 1.1.1.1 | grep "bytes from" | cut -d" " -f 5
nmap 1.1.1.1-254或者1.1.1.0/24 -sn //可支持地址段
nmap -iL iplist.txt -sn //调用存好的文本文档ping
主动
netdiscover -i eth0 -r 1.1.1.0/24
netdiscover -l iplist.txt
被动 (被动方式主要是等待其他主机溢出ARP包,在本机监听然后采集)
netdiscover -p
还可以用scapy进行构造ARP数据包然后发送数据包进行探测:
apt-get install python-gnuplot(安装)
2、三层发现
三层发现是基于IP、ICMP协议进行的,优点就是可路由,速度比较快,缺点就是速度比二层慢,经常被防火墙过滤。
这里用五个工具来说明举例:ping、scapy、nmap、fping、hping
举例:
3、四层发现
优点:
可路由且结果可靠
不太可能被防火墙过滤
甚至可以发现所有端口都被过滤的主机
缺点:
基于状态过滤的防火墙可能过滤扫描
全端口扫描速度慢
TCP:
未经请求的ACK——RST
SYN——SYN/ACK RST //通过我们发的包确定他是否在线,会回一个rst包
UDP:
ICMP端口不可达 一曲不复返
这里可以用一些工具,类似如:nmap、scapy、hping等进行实操。
附录1:nmap常用
端口扫扫描:
nmap -sU 1.1.1.1
nmap 1.1.1.1 -sU -p 53
nmap -iL iplist.txt -sU -p 1-200
隐蔽端口扫描:
nmap -sS 1.1.1.1 -p 80,21,25,110,443
nmap -sS 1.1.1.1 -p 1-65535 --open
nmap -sS 1.1.1.1 -p- --open
nmap -sS -iL iplist.txt -p 80,21,22,23
全连接端口扫描:
nmap -sT 1.1.1.1 -p 80
nmap -sT 1.1.1.1 -p 80,21,25
nmap -sT 1.1.1.1 -p 80-2000
nmap -sT -iL iplist.txt -p 80
服务扫描:
nmap -sT 1.1.1.1 -p 22 --script=banner
服务识别:
nmap 1.1.1.1 -p 80 -sV
操作系统识别:
nmap 1.1.1.1 -O
SMB扫描:
nmap -v -p139,445 192.168.60.1-20
nmap 192.168.60.4 -p139,445 --script=smb-os-discovery.nse
nmap -v -p139,445 --script=smb-check-vulns --script-args=unsafe=1 1.1.1.1
nbtscan -r 192.168.60.0/24
enum4linux -a 192.168.60.10
SMTP扫描:
nmap smtp.163.com -p25 --script=smtp-enum-users.nse --script-args=smtp-enum-users.methods={VRFY}
nmap smtp.163.com -p25 --script=smtp-open-relay.nse文章来源:https://www.toymoban.com/news/detail-444218.html
防火墙识别:文章来源地址https://www.toymoban.com/news/detail-444218.html
到了这里,关于网络安全之信息收集的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!