目录
特征选择
特征选择
树的生成
树的剪枝
特征如何选择
计算信息增益
样本集的基尼值
决策树生成
三种算法对比
决策树剪枝
预剪枝(pre-pruning)
后剪枝(post-pruning)
案例—红酒分类
案例—带噪正弦曲线拟合
前言
本次实验是由python语言为基础学习网站分享给大家
点击右边链接进行学习牛客网学习python跳转链接

特征选择
决策树学习通常包括三个步骤(过程)或称三要素:特征选择、树的生成(构造)、树的剪枝。
特征选择
选择最优的划分特征与条件。父结点(根结点和中间结点)把待分数据集按照选定的特征和测试条件切分成若干数据子集分别进入若干子结点。从根结点到每个叶结点对应一个判定测试序列,如何选择每次测试采用的特征呢,优先测试哪个特征呢?
树的生成
按照特征选择标准,采用递归方式、按照一定策略生成决策树。
树的剪枝
决策树容易发生过拟合,需要采用的一定的剪枝策略来防止过拟合。
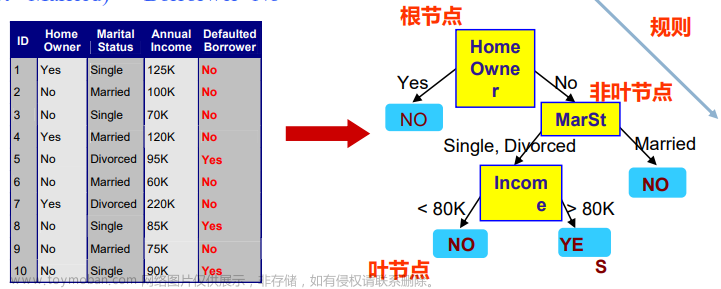
特征如何选择
一棵决策树包括一个根结点、若干内部结点、若干叶结点;叶结点对应于决策结果,其它每个结点则对应于一个属性测试;每个父结点所包含的样本集根据属性测试的结果,被划分到子结点中;根结点包含样本全集,从根结点到每个叶结点对应一个判定测试序列。
决策树学习的关键之一是如何选择最优划分特征,对于连续型特征还要找到最优切分点。随着划分过程不断进行,希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的“纯度”(purity)越来越高。
信息熵(information entropy)和基尼指数(Gini index)是度量样本集合不纯度(impurity)的常用指标。假设当前样本集合D中第k类样本所占比例为 ( k=1,2,3,......,K ),则D 的信息熵定义为

上述定义中的概率由数据估计得到,故称为样本集的经验熵。样本的类别分布越均匀,熵越大,样本集越混杂,纯度越低,不纯度越高;当样本属于每个类别的比例相同时,熵值最大,当所有样本都属于同一类别时,熵值为0。


使用特征A对于对样本集D进行划分所获得的信息增益定义为

计算信息增益

原始样本集共8个样本,标签“是”有3个,标签“否”有5个

原始样本集8个样本,按照特征“拥有房产” ,可划分成2个子集

列表如下:


使用房产特征划分原始样本集后所得信息增益=0.9544-0.6068= 0.3476
决策树学习算法ID3(Iterative Dichotomizer 3)就是按信息增益最大准则来选取划分特征。
信息增益最大准则倾向于选择具有大量不同取值的特征,从而产生许多小而纯的子集。例如,若把客户ID作为划分特征,切分后的条件信息熵为零,能获得最大信息增益,但是这样做毫无意义。但信息增益比最大准则对可取值数目较少的特征有所偏好。因此,C4.5算法先从候选划分属性中找出信息增益高于平均水平的特征,再从中选择增益比最高的特征作为划分特征。
样本集的基尼值

取V个离散值的特征A对于数据集D的基尼指数

基尼指数越大,样本的不确定性也就越大。决策树学习算法CART(Classification And Regression Tree)根据基尼指数最小来选择最优划分特征
决策树生成
三种算法对比
ID3决策树:使用信息增益作为特征选择标准
C4.5决策树在ID3决策树基础上有三点改进,其它部分相同。
(1)ID3容易偏向于优先选取取值种类较多的特征。为此,C4.5先从候选划分特征中找出信息增益高于平均水平的特征,再从中选择信息增益比最高的特征作为划分特征。
(2)ID3不能处理连续型特征。为此,C4.5对连续型特征的取值排序后按区间和阀值进行离散化。
(3)ID3决策树容易过拟合。决策树分叉过细会导致最后生成的决策树模型对训练集数据拟合特别好,但是对新数据的预测效果较差,即模型泛化能力不好。为此,C4.5引入了正则化系数进行初步的剪枝来缓解过拟合问题。CART(Classification And Regression Tree分类回归树)
(1)ID3和C4.5计算熵值时需要计算对数,CART采用基尼系数,简化了计算。
(2)ID3和C4.5采用多叉树进行特征划分,即特征有几种类别取值就划分几棵子树,并且该特征在后续算法执行过程中被排除在候选特征之外,这种划分方式过于粗糙,特征信息的利用率较低;C4.5对连续值采用区间离散化,或多或少会损失一部分信息。CART采用二叉树对每个特征进行划分
例如某离散特征取值{1,2,3},则分别对{1}和{2,3},{2}和{1,3},{3}和{1,2}三种情况计算,从中选择基尼系数最小的组合进行二切分,生成两个二叉子树。对于连续特征,对其n个取值排序后,依次取每两个相邻值的中间值作为划分点,比较这n-1次划分对应的基尼系数,选最小基尼系数对应的划分点生成二叉子树。因此,每次进行特征选择的最小单位是某个特征下的某个最优二切分点,使得CART可以对同一特征进行多次利用。
(3)ID3和C4.5只能用于分类任务。CART则可用于分类和回归。CART用于回归预测时,采用平方误差最小的划分为最优划分
给定数据集D,m个样本,每个样本n个特征。对于每个特征,计算每种二叉划分对应的平方误差,取最小者对应的划分点;在所有特征上,选择最小者,从而得到最佳划分特征及其划分点。(4)CART预测输出
分类预测:每个叶子结点所含全部样本中标签类别占多数者作为它对应的标签类别预测输出。
回归预测:每个叶子结点所含全部样本对应标签值的平均值或中位数作为它对应的标签值预测输出。
决策树剪枝
如果不限制树的规模,决策树将会一直分裂下去,直到每个叶子结点只包含一个样本为止。在理想情况下,这样做能够把训练集中的所有样本完全分开,因为每个样本各自占据一个叶子结点。这样的决策树出现完全过拟合,在测试集上的效果会很差。
剪枝策略对决策树影响巨大,是优化决策树算法的核心。有两种常见方法
预剪枝(pre-pruning)
在生成决策树的过程中提前停止树的增长。
预剪枝思想:在树中结点进行分裂之前,先计算当前划分是否能够带来模型泛化能力的提升,如果不能,则不再继续生长。此时结点中可能包括不同类别的样本,按照多数投票的原则判断该结点所属类别。停止决策树生长的常用判断条件有:树达到一定深度;当前结点的样本数量小于某个阀值;计算每次分裂对测试集的准确率提升,当小于某个阀值时,不再继续扩展。
后剪枝(post-pruning)
在已生成的过拟合决策树上进行剪枝,得到简化版的剪枝决策树。
后剪枝思想:生成一颗完全生长的决策树后,从最底层向上计算是否剪枝。剪枝过程就是把子树删除,用一个叶结点替代,该结点的类别同样按多数投票原则确定。若剪枝后在测试集上准确率有所提升,则进行剪枝。
案例—红酒分类






调参没有固定方法,一切都是看数据本身。
如果数据集非常巨大,你已经预测到无论如何都是要剪枝的,那提前设定这些参数来控制树的复杂性和大小会比较好。
案例—带噪正弦曲线拟合
Sklearn回归树衡量最佳结点和分枝的指标有
(1)criterion= “ mse ” ,使用均方误差MSE,父节点和子节点之间的均方误差的差额被用来作为划分特征选择的标准,这种方法通过使用叶子节点的均值来最小化L2损失。(不填该参数,则默认mse)
(2)criterion= " friedman_mse " ,使用费尔德曼均方误差(针对潜在分枝中的问题改进后的均方误差)
(3)criterion= " mae "使用平均绝对误差MAE,使用叶节点的中值来最小化L1损失。


 文章来源:https://www.toymoban.com/news/detail-444266.html
文章来源:https://www.toymoban.com/news/detail-444266.html
跟博主一起来学习吧点击跳转文章来源地址https://www.toymoban.com/news/detail-444266.html
到了这里,关于【人工智能】机器学习中的决策树的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!