1. 分词器介绍
•IKAnalyzer 是一个开源的,基于java语言开发的轻量级的中文分词工具包
•是一个基于Maven构建的项目
•具有60万字/秒的高速处理能力
•支持用户词典扩展定义
2. ik 分词器安装
IK 分词器安装
3. 分词器的使用
IK分词器有两种分词模式:ik_max_word 和 ik_smart 模式。
1、ik_max_word
会将文本做最细粒度的拆分,比如会将“秦始皇陵兵马俑”拆分为很多词。
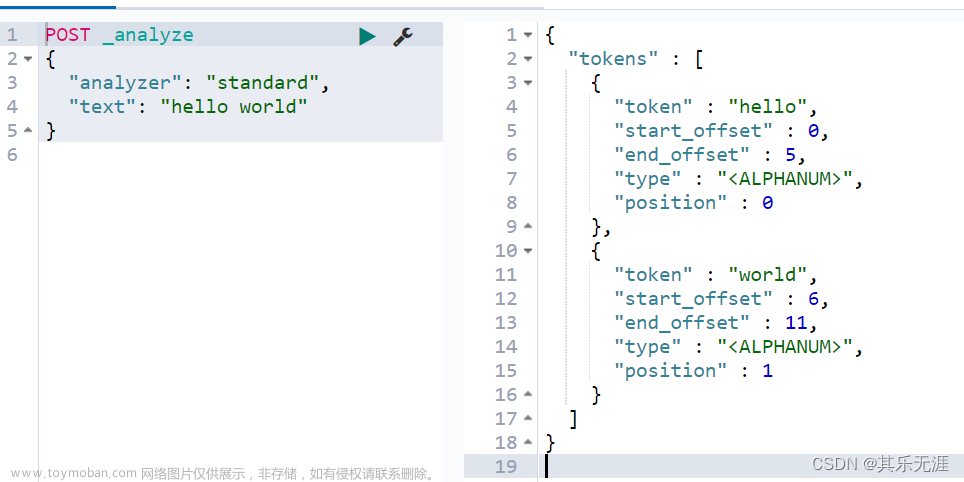
#方式一ik_max_word
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "秦始皇陵兵马俑"
}
ik_max_word分词器执行如下:
{
"tokens" : [
{
"token" : "秦始皇陵",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "秦始皇",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "始皇",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "皇陵",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "兵马俑",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "兵马",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "俑",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 6
}
]
}

2、**ik_smart **会做最粗粒度的拆分,比如会将“秦始皇陵兵马俑”拆分为只有两个词。
#方式二ik_smart
GET /_analyze
{
"analyzer": "ik_smart",
"text": "秦始皇陵兵马俑"
}
ik_smart分词器执行如下:
{
"tokens" : [
{
"token" : "秦始皇陵",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "兵马俑",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 1
}
]
}
 文章来源:https://www.toymoban.com/news/detail-444645.html
文章来源:https://www.toymoban.com/news/detail-444645.html
我们可以根据业务不同 选择具体的分词方式。文章来源地址https://www.toymoban.com/news/detail-444645.html
到了这里,关于【ElasticSearch】分词器(ElasticSearchIK分词器)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!