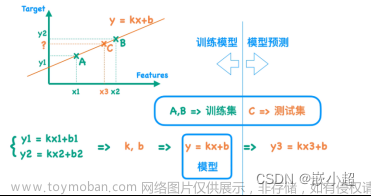
一、learning rate 简述
lr全称learning rate(一下简称lr),是机器学习和深度学习中最为重要的超参数之一,会影响模型训练结果的好坏,有时候甚至会直接导致整个模型无法使用。
lr最直接的可观测的影响就是loss值的变化,较大的学习率会更容易收敛也更容易出现陷入局部最优解的情况,而过大的学习率会导致loss无法收敛甚至出现nan的情况;较小的学习率更容易找到全局最优解但是loss下降和收敛的速度也更慢,过小的学习率甚至会出现在可接收的训练epoch内无法收敛到“最优值”的情况。具体见图一。所以找到一个合适的学习率对于在较少的epoch内训练到一个较好模型中至关重要。

图一 不同学习率下loss的变化(图片来源于网络,侵删)
二、learining rate 调参技巧
可用的方法主要有经验调参、网格搜索自动调参、智能优化算法调参、贝叶斯优化、lr range test调参等等。
经验调参
调过lr的都知道lr目前主要是靠经验来选择,一般有效的学习率是  ,通常设置多个不同量级的lr来初步筛选较为合适的lr,当loss收敛较慢时则适当调高lr、当loss不收敛或者收敛到的loss较大时则适当调低lr等等。但是当训练数据量较大或者模型较大时将是一个比较耗费计算机资源的过程。
,通常设置多个不同量级的lr来初步筛选较为合适的lr,当loss收敛较慢时则适当调高lr、当loss不收敛或者收敛到的loss较大时则适当调低lr等等。但是当训练数据量较大或者模型较大时将是一个比较耗费计算机资源的过程。
网格搜索自动调参
网格搜索算是一个遍历的过程,通过设置一系列的各种超参数的值,然后组合出所有的超参数对进行训练,同时选出最优的参数组合,属于是一种暴力遍历方法,在训练数据量较大或者模型较大时一般就没办法使用,毕竟太耗费资源了,就是一个暴力搜索算法。不是本博客的重点,如有需要自己去了解。
智能优化算法调参
智能优化算法调参可以是一个网格搜索的改进,通常有遗传算法、粒子群算法等,在一个超参数区间内以一种优化策略找到最合适的学习率等超参数。这种方式在开销上较为合适但是实现起来相对麻烦并且我似乎没有找到很好的博客介绍。此方法不是本博客的重点,如果有兴趣可以去自己去了解,还是有比较多的论文研究应用这种方法。
LR range test调参
LR range test在论文《Cyclical Learning Rates for Training Neural Networks》中首次提出,当然这篇论文重点不在于LR range test,而是提出了一个新的设置lr变化的方式,很有意思,有兴趣的小伙伴可以看看。我觉得LR range test是个权衡了效率和准确性的方法,但是这种方法仅限于lr超参数的调整,没法像上面几种方式具有普适性。本博客参考了多篇博客和论文,具体见参考资料。
三、LR range test
简介
这种方法可以通过网络的一个训练运行几个epoch或者多个iteration来估计合理的lr最小和最大边界值。它是一种" LR范围检验"方法;在让学习率在低LR值和高LR值之间增长的同时,运行模型几个合适的epoch。当面对一个新的架构或数据集时,这个测试是非常有价值的,可以说效率很高,针对大的数据集和大模型非常合适。但是有一点要注意!这是一个估计最大和最小界的方法,某种程度上也可以选出理想的lr(但可以不会最优的)。换句话说这是一种估计的方法而不是精确定量的方法!
这种方法的核心思想其实是经验调参自动化,即根据loss的变化来选择合适的lr,具体方法是在训练和更新权重的同时将lr从较小值增长到较大值,在这个过程中记录下loss随lr变换的图,同时如有必要可以再考虑loss随epoch变化和lr随epoch变化的图(具体见图二),可以更加清晰地认识到变化情况。

图二 LR range test辅助可视化曲线
通常在loss随lr变化的过程中会有三个区间(具体见图三),一个是lr过小导致loss无法下降的过程,一个是lr合适loss下降的过程,另外一个是loss过大导致loss开始上升的过程。这个过程也可以用来判断我们的模型和选用的优化器是否合适,如果有明显的三个区间则可以验证其正确性,如果没有三个区间或者不连续等情况则需要重新检查模型(具体见仁见智)。

图三 loss随lr变化的曲线(图片来源于网络,侵删)
其方法的有效性是在lr变化过程中较大的lr相对于较小的lr占主导,此时在一定范围内的lr的训练可以视为是某个特定lr的训练过程,所以在这段合理区间内相当于是设置了该lr进行训练,这段区间内的loss变化也可以视为在该lr下的变化过程。所以我觉得要使得这个方法更加有效,一个是设置合适的lr随epoch(iteration)变化的情况使得在某个更加关注的区间内变化较慢(有足够的时间/足够长的区间来对loss进行反应),另一个是要设置足够多的epoch(iteration)数来使得变化更加充分。具体见具体实现部分。
具体关键步骤
(1)最小最大lr的确定
根据lr的理论有效区间,我们最大可以设置最小为 ,最大为1。当然不同的模型会有不同的区间,一般情况下NLP的有效区间值会更小一些,可以适当调低最大lr;CV的可以适当调高最小lr,具体模型根据具体情况来设置。
,最大为1。当然不同的模型会有不同的区间,一般情况下NLP的有效区间值会更小一些,可以适当调低最大lr;CV的可以适当调高最小lr,具体模型根据具体情况来设置。
(2)lr随epoch(iteration)变化函数的设置
通常可以有线性增加、指数增加等方式,论文中使用的是线性增加,我更加推荐指数增加,因为在较小的lr时通常收敛速度会更慢,也就是需要更多的epoch(iteration)来训练才会在loss上有所体现,所以需要lr增长慢一点来提供更多的训练机会。其具体函数如下:
# 下面时线性增加的lambda表达式,其中d是公差,决定变化快慢(以这种方式是方便后续pytorh代码的实现)
lambda iterations: (1 + d * iterations / min_lr) * min_lr
# 下面是指数增加,2和1000可以根据具体所需快慢来设置
lambda iterations:(2**(iterations / 1000)) * min_lr具体变化情况如下
import numpy as np
import matplotlib.pyplot as plt
if __name__=='__main__':
min_lr = 1e-5
d = 5e-5
iterations = np.linspace(0, 17000)
# 线性
lrs_linear = (1 + d * iterations / min_lr) * min_lr
# 非线性
lrs_exp = (2**(iterations / 1000)) * min_lr
plt.plot(iterations, lrs_linear, label='linear')
plt.plot(iterations, lrs_exp, label='exp')
plt.show()
图四 lr随iteration线性变化曲线

图五 lr随iteration指数变化曲线
(3)epoch(iteration)的设置
一般需要设置多个epoch(至于设置多少个epoch我觉得是需要根据数据量来确定,论文中所用的为8个epoch),我认为大致17000个左右的iteration(batch)就可以。
(4)lr区间和最佳lr的选择的选择
应该选择loss下降速度接近0且稍微往左一些的点。比如分析下面的图,有效区间为 ,可以发现0.01是最合适的点。当然要是有条件可以选择几个合适的lr然后再分别进行训练筛选即可。
,可以发现0.01是最合适的点。当然要是有条件可以选择几个合适的lr然后再分别进行训练筛选即可。

图六 loss随lr变化曲线(来源于网络、侵删)
三、完整案例代码
在调参过程中可以选择合适优化器和加入warm-up策略等,可以使用pytorch中提供的优化器中lr修改接口,本部分会演示一个完整的lr range test调参过程,感兴趣的可以自己先去实现,不是很难,给自己挖个坑,等有机会我再补充此部分。
四、参考资料
[1506.01186] Cyclical Learning Rates for Training Neural Networks (arxiv.org)
Estimating an Optimal Learning Rate For a Deep Neural Network | by Pavel Surmenok | Towards Data Science文章来源:https://www.toymoban.com/news/detail-445136.html
自 Adam 出现以来,深度学习优化器发生了什么变化? - 知乎 (zhihu.com)文章来源地址https://www.toymoban.com/news/detail-445136.html
到了这里,关于深度学习学习率(lr)调参的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!