论文链接: https://www.cv-foundation.org/openaccess/content_cvpr_2014/papers/Girshick_Rich_Feature_Hierarchies_2014_CVPR_paper.pdf
论文技术报告链接: https://arxiv.org/pdf/1311.2524.pdf
出处: CVPR 2014
参考视频: https://www.bilibili.com/video/BV1d64y1W74E/?spm_id_from=333.999.0.0&vd_source=e321967bf2cdc2338238788250d12de8
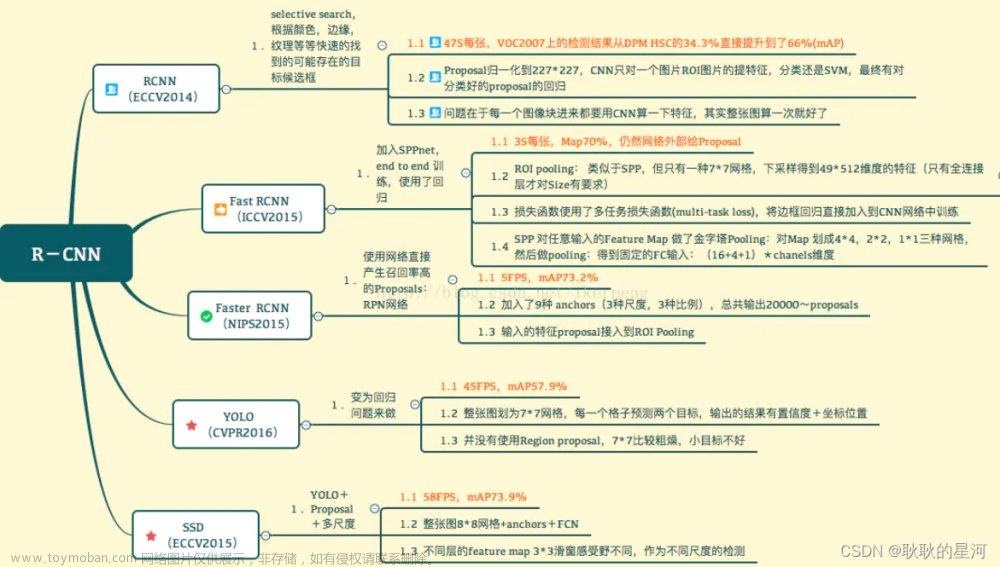
R-CNN基本原理


总结起来就是:输入原图,然后用selective search算法生成2000个候选框,再将每个候选框缩放为
227
×
227
227\times227
227×227的固定大小,再逐一喂到同一个卷积神经网络提取4096维的特征,用该4096维的特征同时进行分类(线性SVM)和回归,最终得到目标检测结果。
可以看到R-CNN严重依赖上下游的多个步骤协作完成目标检测任务:①提取候选框;②缩放;③用CNN提取特征;④分类和回归。只要有一个步骤出现问题,整个检测系统就会出现问题。每个步骤都需要单独去优化,因此并不是一个端到端的系统。

R-CNN是一个非常耗时、非常低效、非常臃肿、一点不端到端的算法: 因此,可以对R-CNN进行改进:
因此,可以对R-CNN进行改进:
产生候选框-Selective Search
论文链接: https://www.koen.me/research/selectivesearch/

将候选框缩放至 227 × 227 227\times227 227×227固定大小

最终,作者采用连带邻近像素的非等比例缩放方法,连带像素
p
=
16
p=16
p=16。 这种将像素向外扩一圈,并将扩展之后的结果作为候选框的方法叫做Dilate proposal。
这种将像素向外扩一圈,并将扩展之后的结果作为候选框的方法叫做Dilate proposal。
可视化能够使得某个feature map的某个值最大化的原始候选框


从AlexNet最后一个池化层得到的feature map的形状是
6
×
6
×
256
6\times6\times256
6×6×256,我们可视化其中的某一个channel的某一个值,找到使得这个值最大化的原始的候选框。
作者从
6
×
6
×
256
6\times6\times256
6×6×256的feature map中选了60多个channel来可视化能够使得某个channel的某个值最大化的24个原始候选框:


对比实验
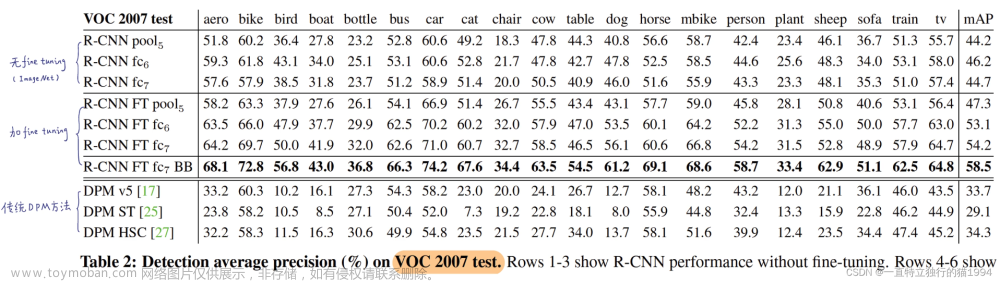
说明了fine-tuning的重要性。
R-CNN用于语义分割:

为什么不直接用softmax分类而要用线性SVM分类?
原因①:
fine-tuning时与训练各类别SVM时的正负样本选择策略是不一样的,所以,如果直接用softmax的话,就必须都按照fine-tuning的正负样本的选择策略来,但是如果用SVM来分类的话,会更好,因为训练SVM时加入了hard negtive mining,而且选择正负样本时也和fine-tuning时不一样。因此,不能直接用softmax而是要用SVM的。 原因②:
原因②:
为什么不使用SVM的正负样本选择策略去训练softmax?作者是使用Matlab实现的,Matlab是一个封装的很死的一个库,不允许有太多的自由的修改,不像python一样可以自由的修改底层代码。RBG大神当时写R-CNN时用的是Matlab,可能matlab只有SVM可以进行hard negtive mining。所以没有直接用softmax而是用的SVM。
Bounding Box Regression
所谓回归就是对候选框进行精调,使回归模型输出一系列偏移量,再对候选框施加偏移量从而得到最终的预测框。
 具体来讲:
具体来讲:
让黄色去拟合蓝色,即找一套线性权重,使得损失函数最小。
R-CNN的Slides讲解
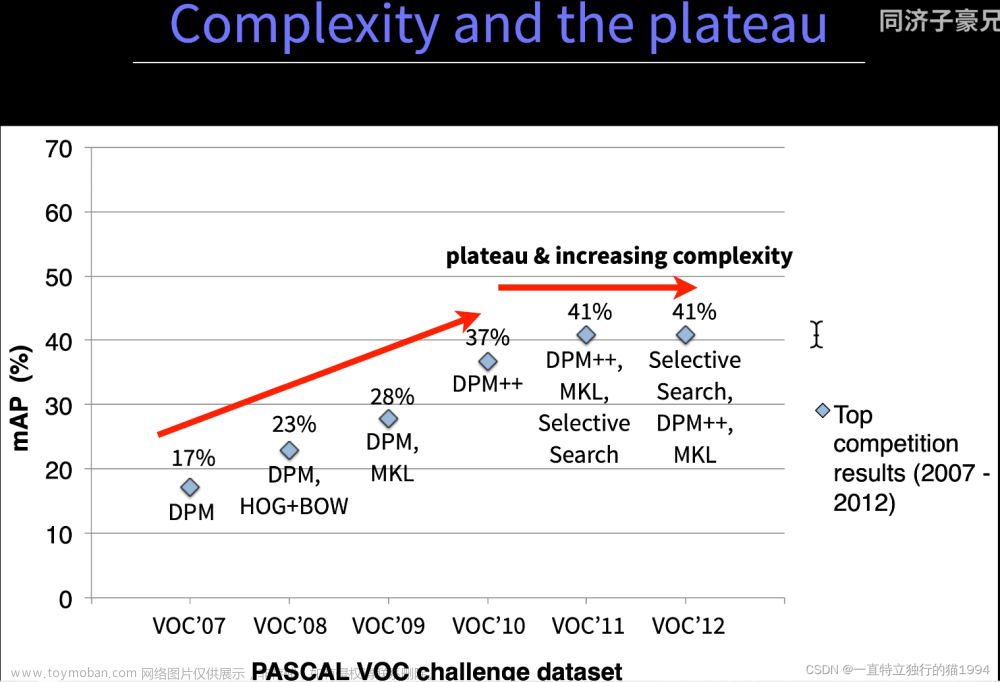
 没有什么实质性的进展。
没有什么实质性的进展。 R-CNN取得了实质性的突破。
R-CNN取得了实质性的突破。
R-CNN论文精度

Selective Search产生Region proposals
 强行缩放:
强行缩放:
候选框特征提取
 使用Caffe实现的AlexNet作为特征提取的骨干网络,包括5个卷积层和2个全连接层。
使用Caffe实现的AlexNet作为特征提取的骨干网络,包括5个卷积层和2个全连接层。 把所有一千万个候选框输入,找到能使某个feature map中的某个值产生最大激活的候选框,也就是使某单次卷积、单个神经元产生最大激活。
把所有一千万个候选框输入,找到能使某个feature map中的某个值产生最大激活的候选框,也就是使某单次卷积、单个神经元产生最大激活。
不对这个feature map求平均,只关注某个feature map中的某个值。 使6个通道中的某6个神经元产生最大激活的top regions。
使6个通道中的某6个神经元产生最大激活的top regions。 没有fine turning时,预训练模型中CNN的特征表示性能大部分来自卷积层而非全连接层,去掉全连接层影响不大。进行fine turning时,CNN提取通用特征,FC完成特定领域任务。
没有fine turning时,预训练模型中CNN的特征表示性能大部分来自卷积层而非全连接层,去掉全连接层影响不大。进行fine turning时,CNN提取通用特征,FC完成特定领域任务。 加了边界框回归能有效降低定位误差。
加了边界框回归能有效降低定位误差。 输入CNN之前,强行将候选框缩放至统一尺寸、统一长宽比,所以在不同尺寸和长宽比上FT性能提升意味着全连接层学习到更有用的特征。文章来源:https://www.toymoban.com/news/detail-445289.html
输入CNN之前,强行将候选框缩放至统一尺寸、统一长宽比,所以在不同尺寸和长宽比上FT性能提升意味着全连接层学习到更有用的特征。文章来源:https://www.toymoban.com/news/detail-445289.html
正负样本的问题:为什么在fine turning训练卷积神经网络和在训练各类别的线性SVM时的正负样本的选取不一样?

fine turning时,正样本与GT有偏离,精准定位性能差;
用softmax并不能解决这一问题(掉点);
用SVM时,GT框为该类正样本,精准定位性能好,且加入了难例挖掘,能够较好的解决问题。文章来源地址https://www.toymoban.com/news/detail-445289.html
到了这里,关于目标检测经典论文精读-R-CNN的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!