目录
一、开发背景
二、网络结构
三、模型特点
四、代码实现
1. model.py
2. train.py
3. predict.py
4. spilit_data.py
五、参考内容
一、开发背景
GoogLeNet在2014年由Google团队提出, 斩获当年ImageNet(ILSVRC14)竞赛中Classification Task (分类任务) 第一名,VGG获得了第二名,为了向“LeNet”致敬,因此取名为“GoogLeNet”。
GoogLeNet做了更加大胆的网络结构尝试,虽然深度只有22层,但大小却比AlexNet和VGG小很多。GoogleNet参数为500万个,AlexNet参数个数是GoogleNet的12倍,VGGNet参数又是AlexNet的3倍,因此在内存或计算资源有限时,GoogleNet是比较好的选择,从模型结果来看,GoogLeNet的性能也更加优越。
二、网络结构
GoogLeNet 总共有22层,由 9 个 Inception v1 模块和 5 个池化层以及其他一些卷积层和全连接层构成。该网络有3个输出层,其中的两个是辅助分类层,如下图所示:

清晰图见:https://nndl.github.io/v/cnn-googlenet
inception v1结构
传统网络为了减少参数量,减小过拟合,将全连接和一般卷积转化为随机稀疏连接,但是计算机硬件对非均匀稀疏数据的计算效率差。为了既保持网络结构的稀疏性,又能利用密集矩阵的高计算性能,GoogLeNet提出了一种并联结构,Inception网络结构。其主要思想是寻找用密集成分来近似最优局部稀疏连接,通过构造一种“基础神经元”结构,来搭建一个稀疏性、高计算性能的网络结构。
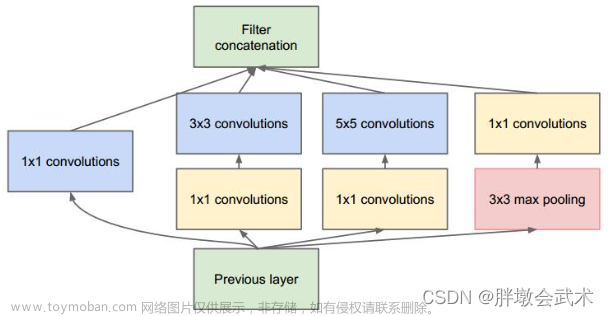
下图是论文中提出的inception v1结构。Inception块由四条并行路径组成,前三条路径使用窗口大小为1×1、3×3和5×5的卷积层,从不同空间大小中提取信息。中间的两条路径在输入上执行1×1卷积,以减少通道数,减少模型训练参数,从而降低模型的复杂性。第四条路径使用3×3最大汇聚层,然后使用1×1卷积层来改变通道数。这四条路径都使用合适的填充来使输入与输出的高和宽一致,以保证输出特征能在通道维度上进行拼接。最后我们将每条线路的输出在通道维度上连结,并构成Inception块的输出。Inception块的通道数分配之比是在ImageNet数据集上通过大量的实验得来的。如下图所示:

注:CNN参数个数 = 卷积核尺寸×卷积核深度 × 卷积核组数 = 卷积核尺寸 × 输入特征矩阵深度 × 输出特征矩阵深度
辅助分类器(Auxiliary Classifier)
网络主干右边的两个分支就是辅助分类器,他们也能预测图片的类别,其结构一模一样。它确保了即便是隐藏单元和中间层也参与了特征计算,在inception网络中起到一种调整的效果,避免梯度消失。在训练模型时,将两个辅助分类器的损失乘以权重(论文中是0.3)加到网络的整体损失上,再进行反向传播。实际预测时,这两个辅助分类器会被去掉。如下图所示:

三、模型特点
- 采用了模块化的结构,方便增添和修改;
- 引入Inception结构,在加深的基础上进行加宽,稀疏的网络结构,但能产生稠密的数据,既能改善神经网络表现,又能保证计算资源的使用效率,并且它通过不同窗口大小的卷积层和最大池化层来并行抽取信息,融合不同尺度的特征信息;
- 使用1x1的卷积核减少通道数来减少计算量和参数,从而降低模型复杂度;
- 添加两个辅助分类器帮助训练,其实这种训练方式可以看作将几个不同深度的子网络合并到一块进行训练,由于网络的卷积核共享,因此计算的梯度可以累加,这样最终的梯度便不会很小甚至消失;
- 采用全局平均池化层来代替全连接层,大大减少模型参数,除去两个辅助分类器,网络大小只有VGG的1/20,准确率提高0.6%,实际在最后还是加了一个全连接层,便于对输出进行灵活调整;
- Googlenet提出了多尺度融合的网络结构,这种结构非常有意义,在目标检测领域应用非常广泛,目标检测的特征金字塔特征融合的方法和网络结构正是借鉴了Googlenet的思想。
四、代码实现
- model.py :定义GoogLeNet网络模型
- train.py:加载数据集并训练,计算loss和accuracy,保存训练好的网络参数
- predict.py:用自己的数据集进行分类测试
- spilit_data.py:划分给定的数据集为训练集和测试集
1. model.py
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义GoogLeNet网络模型
class GoogLeNet(nn.Module):
# init():进行初始化,申明模型中各层的定义
# num_classes:需要分类的类别个数
# aux_logits:训练过程是否使用辅助分类器,init_weights:是否对网络进行权重初始化
def __init__(self, num_classes=1000, aux_logits=True, init_weights=False):
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
# ceil_mode=true时,将不够池化的数据自动补足NAN至kernel_size大小
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
# 如果为真,则使用分类器
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
# AdaptiveAvgPool2d:自适应平均池化,指定输出(H,W)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
# 如果为真,则对网络参数进行初始化
if init_weights:
self._initialize_weights()
# forward():定义前向传播过程,描述了各层之间的连接关系
def forward(self, x):
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
# 设置.train()时为训练模式,self.training=True
if self.training and self.aux_logits:
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
if self.training and self.aux_logits:
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
if self.training and self.aux_logits:
return x, aux2, aux1
return x
# 网络结构参数初始化
def _initialize_weights(self):
# 遍历网络中的每一层
for m in self.modules():
# isinstance(object, type),如果指定的对象拥有指定的类型,则isinstance()函数返回True
# 如果是卷积层
if isinstance(m, nn.Conv2d):
# Kaiming正态分布方式的权重初始化
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
# 如果偏置不是0,将偏置置成0,对偏置进行初始化
if m.bias is not None:
# torch.nn.init.constant_(tensor, val),初始化整个矩阵为常数val
nn.init.constant_(m.bias, 0)
# 如果是全连接层
elif isinstance(m, nn.Linear):
# init.normal_(tensor, mean=0.0, std=1.0),使用从正态分布中提取的值填充输入张量
# 参数:tensor:一个n维Tensor,mean:正态分布的平均值,std:正态分布的标准差
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
# 基础卷积层(卷积 + ReLU)
class BasicConv2d(nn.Module):
# init():进行初始化,申明模型中各层的定义
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
# ReLU(inplace=True):将tensor直接修改,不找变量做中间的传递,节省运算内存,不用多存储额外的变量
self.relu = nn.ReLU(inplace=True)
# 前向传播过程
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
# Inception结构
class Inception(nn.Module):
# init():进行初始化
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super(Inception, self).__init__()
# 分支1,单1x1卷积层
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
# 分支2,1x1卷积层后接3x3卷积层
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
# 保证输出大小等于输入大小
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1)
)
# 分支3,1x1卷积层后接5x5卷积层
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
# 保证输出大小等于输入大小
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2)
)
# 分支4,3x3最大池化层后接1x1卷积层
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
# forward():定义前向传播过程,描述了各层之间的连接关系
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
# 在通道维上连结输出
outputs = [branch1, branch2, branch3, branch4]
# cat():在给定维度上对输入的张量序列进行连接操作
return torch.cat(outputs, 1)
# 辅助分类器
class InceptionAux(nn.Module):
# init():进行初始化
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1)
# 上一层output[batch, 128, 4, 4],128X4X4=2048
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
# 前向传播过程
def forward(self, x):
# 输入:分类器1:Nx512x14x14,分类器2:Nx528x14x14
x = self.averagePool(x)
# 输入:分类器1:Nx512x14x14,分类器2:Nx528x14x14
x = self.conv(x)
# 输入:N x 128 x 4 x 4
x = torch.flatten(x, 1)
# 设置.train()时为训练模式,self.training=True
x = F.dropout(x, 0.5, training=self.training)
# 输入:N x 2048
x = F.relu(self.fc1(x), inplace=True)
x = F.dropout(x, 0.5, training=self.training)
# 输入:N x 1024
x = self.fc2(x)
# 返回值:N*num_classes
return x2. train.py
import os
import sys
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from tqdm import tqdm
from model import GoogLeNet
def main():
# 如果有NVIDA显卡,转到GPU训练,否则用CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
data_transform = {
# Compose():将多个transforms的操作整合在一起
# 训练
"train": transforms.Compose([
# RandomResizedCrop(224):将给定图像随机裁剪为不同的大小和宽高比,然后缩放所裁剪得到的图像为给定大小
transforms.RandomResizedCrop(224),
# RandomVerticalFlip():以0.5的概率竖直翻转给定的PIL图像
transforms.RandomHorizontalFlip(),
# ToTensor():数据转化为Tensor格式
transforms.ToTensor(),
# Normalize():将图像的像素值归一化到[-1,1]之间,使模型更容易收敛
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
# 验证
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
# abspath():获取文件当前目录的绝对路径
# join():用于拼接文件路径,可以传入多个路径
# getcwd():该函数不需要传递参数,获得当前所运行脚本的路径
data_root = os.path.abspath(os.getcwd())
# 得到数据集的路径
image_path = os.path.join(data_root, "flower_data")
# exists():判断括号里的文件是否存在,可以是文件路径
# 如果image_path不存在,序会抛出AssertionError错误,报错为参数内容“ ”
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
# 加载训练数据集
# ImageFolder:假设所有的文件按文件夹保存,每个文件夹下存储同一个类别的图片,文件夹名为类名,其构造函数如下:
# ImageFolder(root, transform=None, target_transform=None, loader=default_loader)
# root:在指定路径下寻找图片,transform:对PILImage进行的转换操作,输入是使用loader读取的图片
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
# 训练集长度
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
# class_to_idx:获取分类名称对应索引
flower_list = train_dataset.class_to_idx
# dict():创建一个新的字典
# 循环遍历数组索引并交换val和key的值重新赋值给数组,这样模型预测的直接就是value类别值
cla_dict = dict((val, key) for key, val in flower_list.items())
# 把字典编码成json格式
json_str = json.dumps(cla_dict, indent=4)
# 把字典类别索引写入json文件
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
# 一次训练载入32张图像
batch_size = 32
# 确定进程数
# min():返回给定参数的最小值,参数可以为序列
# cpu_count():返回一个整数值,表示系统中的CPU数量,如果不确定CPU的数量,则不返回任何内容
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8])
print('Using {} dataloader workers every process'.format(nw))
# DataLoader:将读取的数据按照batch size大小封装给训练集
# dataset (Dataset):输入的数据集
# batch_size (int, optional):每个batch加载多少个样本,默认: 1
# shuffle (bool, optional):设置为True时会在每个epoch重新打乱数据,默认: False
# num_workers(int, optional): 决定了有几个进程来处理,默认为0意味着所有的数据都会被load进主进程
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
# 加载测试数据集
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
# 测试集长度
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
# 模型实例化,将模型转到device
net = GoogLeNet(num_classes=5, aux_logits=True, init_weights=True)
net.to(device)
# 定义损失函数(交叉熵损失)
loss_function = nn.CrossEntropyLoss()
# 定义adam优化器
# params(iterable):要训练的参数,一般传入的是model.parameters()
# lr(float):learning_rate学习率,也就是步长,默认:1e-3
optimizer = optim.Adam(net.parameters(), lr=0.0003)
# 迭代次数(训练次数)
epochs = 30
# 用于判断最佳模型
best_acc = 0.0
# 最佳模型保存地址
save_path = './googleNet.pth'
train_steps = len(train_loader)
for epoch in range(epochs):
# 训练
net.train()
running_loss = 0.0
# tqdm:进度条显示
train_bar = tqdm(train_loader, file=sys.stdout)
# train_bar: 传入数据(数据包括:训练数据和标签)
# enumerate():将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在for循环当中
# enumerate返回值有两个:一个是序号,一个是数据(包含训练数据和标签)
# x:训练数据(inputs)(tensor类型的),y:标签(labels)(tensor类型)
for step, data in enumerate(train_bar):
# 前向传播
images, labels = data
# 计算训练值
logits, aux_logits2, aux_logits1 = net(images.to(device))
# GoogLeNet的网络输出loss有三个部分,分别是主干输出loss、两个辅助分类器输出loss(权重0.3)
loss0 = loss_function(logits, labels.to(device))
loss1 = loss_function(aux_logits1, labels.to(device))
loss2 = loss_function(aux_logits2, labels.to(device))
loss = loss0 + loss1 * 0.3 + loss2 * 0.3
# 反向传播
# 清空过往梯度
optimizer.zero_grad()
# 反向传播,计算当前梯度
loss.backward()
# 根据梯度更新网络参数
optimizer.step()
# item():得到元素张量的元素值
running_loss += loss.item()
# 进度条的前缀
# .3f:表示浮点数的精度为3(小数位保留3位)
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# 测试
# eval():如果模型中Batch Normalization和Dropout,则不启用,以防改变权值
net.eval()
acc = 0.0
# 清空历史梯度,与训练最大的区别是测试过程中取消了反向传播
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
# torch.max(input, dim)函数
# input是具体的tensor,dim是max函数索引的维度,0是每列的最大值,1是每行的最大值输出
# 函数会返回两个tensor,第一个tensor是每行的最大值;第二个tensor是每行最大值的索引
predict_y = torch.max(outputs, dim=1)[1]
# 对两个张量Tensor进行逐元素的比较,若相同位置的两个元素相同,则返回True;若不同,返回False
# .sum()对输入的tensor数据的某一维度求和
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
# 保存最好的模型权重
if val_accurate > best_acc:
best_acc = val_accurate
# torch.save(state, dir)保存模型等相关参数,dir表示保存文件的路径+保存文件名
# model.state_dict():返回的是一个OrderedDict,存储了网络结构的名字和对应的参数
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()3. predict.py
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import GoogLeNet
def main():
# 如果有NVIDA显卡,转到GPU训练,否则用CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 将多个transforms的操作整合在一起
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 加载图片
img_path = "../tulip.jpg"
# 确定图片存在,否则反馈错误
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
# imshow():对图像进行处理并显示其格式,show()则是将imshow()处理后的函数显示出来
plt.imshow(img)
# [C, H, W],转换图像格式
img = data_transform(img)
# [N, C, H, W],增加一个维度N
img = torch.unsqueeze(img, dim=0)
# 获取结果类型
json_path = './class_indices.json'
# 确定路径存在,否则反馈错误
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
# 读取内容
with open(json_path, "r") as f:
class_indict = json.load(f)
# 模型实例化,将模型转到device,结果类型有5种
# 实例化模型时不需要辅助分类器
model = GoogLeNet(num_classes=5, aux_logits=False).to(device)
# 载入模型权重
weights_path = "./googleNet.pth"
# 确定模型存在,否则反馈错误
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
# 在加载训练好的模型参数时,由于其中是包含有辅助分类器的,需要设置strict=False舍弃不需要的参数
missing_keys, unexpected_keys = model.load_state_dict(torch.load(weights_path, map_location=device),
strict=False)
# 进入验证阶段
model.eval()
with torch.no_grad():
# 预测类别
# squeeze():维度压缩,返回一个tensor(张量),其中input中大小为1的所有维都已删除
output = torch.squeeze(model(img.to(device))).cpu()
# softmax:归一化指数函数,将预测结果输入进行非负性和归一化处理,最后将某一维度值处理为0-1之内的分类概率
predict = torch.softmax(output, dim=0)
# argmax(input):返回指定维度最大值的序号
# .numpy():把tensor转换成numpy的格式
predict_cla = torch.argmax(predict).numpy()
# 输出的预测值与真实值
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
# 图片标题
plt.title(print_res)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
plt.show()
if __name__ == '__main__':
main()
4. spilit_data.py
import os
from shutil import copy, rmtree
import random
def mk_file(file_path: str):
if os.path.exists(file_path):
# 如果文件夹存在,则先删除原文件夹在重新创建
rmtree(file_path)
os.makedirs(file_path)
def main():
# 保证随机可复现
random.seed(0)
# 将数据集中10%的数据划分到验证集中
split_rate = 0.1
# 指向解压后的flower_photos文件夹
# getcwd():该函数不需要传递参数,获得当前所运行脚本的路径
cwd = os.getcwd()
# join():用于拼接文件路径,可以传入多个路径
data_root = os.path.join(cwd, "flower_data")
origin_flower_path = os.path.join(data_root, "flower_photos")
# 确定路径存在,否则反馈错误
assert os.path.exists(origin_flower_path), "path '{}' does not exist.".format(origin_flower_path)
# isdir():判断某一路径是否为目录
# listdir():返回指定的文件夹包含的文件或文件夹的名字的列表
flower_class = [cla for cla in os.listdir(origin_flower_path)
if os.path.isdir(os.path.join(origin_flower_path, cla))]
# 创建训练集train文件夹,并由类名在其目录下创建子目录
train_root = os.path.join(data_root, "train")
mk_file(train_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(train_root, cla))
# 创建验证集val文件夹,并由类名在其目录下创建子目录
val_root = os.path.join(data_root, "val")
mk_file(val_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(val_root, cla))
# 遍历所有类别的图像并按比例分成训练集和验证集
for cla in flower_class:
cla_path = os.path.join(origin_flower_path, cla)
# iamges列表存储了该目录下所有图像的名称
images = os.listdir(cla_path)
num = len(images)
# 随机采样验证集的索引
# 从images列表中随机抽取k个图像名称
# random.sample:用于截取列表的指定长度的随机数,返回列表
# eval_index保存验证集val的图像名称
eval_index = random.sample(images, k=int(num*split_rate))
for index, image in enumerate(images):
if image in eval_index:
# 将分配至验证集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(val_root, cla)
copy(image_path, new_path)
else:
# 将分配至训练集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(train_root, cla)
copy(image_path, new_path)
# '\r'回车,回到当前行的行首,而不会换到下一行,如果接着输出,本行以前的内容会被逐一覆盖
# end="":将print自带的换行用end中指定的str代替
print("\r[{}] processing [{}/{}]".format(cla, index+1, num), end="")
print()
print("processing done!")
if __name__ == '__main__':
main()五、参考内容
1.文章
Going Deeper with Convolutionshttps://arxiv.org/abs/1409.4842
含并行连结的网络(GoogLeNet)http://zh-v2.d2l.ai/chapter_convolutional-modern/googlenet.html
2.视频
使用pytorch搭建GoogLeNet网络https://www.bilibili.com/video/BV1r7411T7M5/?spm_id_from=333.788&vd_source=78dedbc0ab33a4edb884e1ef98f3c6b8文章来源:https://www.toymoban.com/news/detail-445326.html
GoogLeNet代码(超详细注释)+数据集下载地址:
https://download.csdn.net/download/qq_43307074/86731566?spm=1001.2014.3001.5503文章来源地址https://www.toymoban.com/news/detail-445326.html
到了这里,关于CNN经典网络模型(四):GoogLeNet简介及代码实现(PyTorch超详细注释版)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!