注:个人愚见,有问题欢迎批评指针。
论文:《TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios》
- ICCV 2021 Open Access Repository
代码:GitHub - TfeiSong/tph-yolov5: CBAM-TPH-biFPN-yolov5
TPH:Transformer Prediction Head
总结比较实用的点:
1. tph(transformer prediction head)。能够捕获更多的全局信息和上下文信息(使用的self-attention和全连接)。
2. CBAM提高通道和空间注意力机制。简单有效好嵌入CNN架构。
3. 增加小目标预测head。在大尺寸feature上实现对小目标的预测,提高小目标预测的准确率。
4. self-training classifier。对难区分的类别截取预测框,送小网络训练一个分类器,提高类别预测准确度。
5. ms-testiong。nms融合多个尺度图像的预测结果,提高mAP。
6. 模型集成:训练多个模型,融合多个模型的预测结果,提高mAP。
摘要:无人机拍摄场景下的目标检测最近很时兴。难题:1. 因无人机总是在不同高度拍摄图像,导致目标尺寸变化剧烈,网络不易优化。2. 且高速低空飞行会对密集堆叠的物体产生运动模糊,对区分目标带来更大挑战。解决方法:本文提出TPH-yolov5,在yolov5中使用transformer prediction heads 替换原始的预测头,探索自注意力机制,去检测不同尺寸的目标。同时也整合CBAM模块,稠密目标的关注区域。另外,增加了有效策略:数据增强,多尺度测试,多模型融合,利用额外分类器。测试集:VisDrone2021。之前的sota方法:DPNetV3,提升1.81%。比yolov5提升了7%。
1. 介绍
无人机场景的目标检测主要有三个问题:1.尺寸多变,2.目标高密度,3.目标对象覆盖范围大。

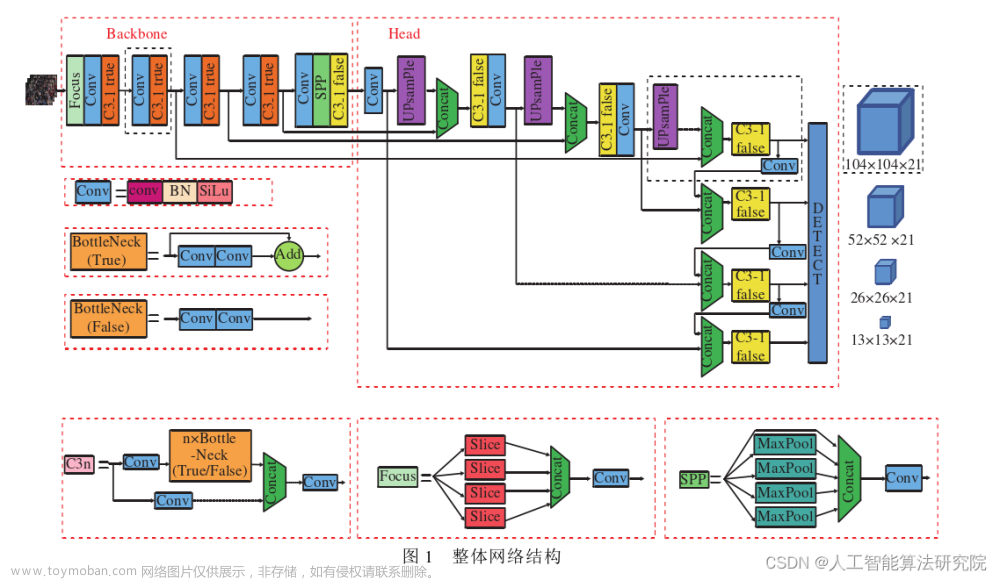
网络结构框架:

整体较yolov5的改变:TPH,CBAM,增加更多头对不同尺寸检测,应用训练技巧(数据增强、多尺度测试、模型集成和自训练分类器)
对于类别相似的图像作者使用了self-trained classifier,把图像裁剪出来作为分类训练集训练模型。
本文贡献:
1. 增加更多的预测头,来处理大尺度变化的目标。
2. 整合TPH模块到yolov5中,提高在稠密场景下位置定位的准确性。
3. 整合CBAM到yolov5中,有利于网络寻找大区域内的感兴趣区域。
4. 对于无人机捕获到的场景使用有效地训练技巧:。
5. 使用自训练分类器,提高区分相似类别的分类能力。
2. 相关工作
2.1 数据增强
扩充不同场景的数据集,提高模型鲁棒性。光学变化增强(hue,saturation and value of the images),几何变化增强(random scaling, cropping, translation, shearing, and rotating),mixup,CutMix,Mosaic。
2.2 多模型集成方法在目标检测上
因为每次训练模型时生成的模型权重文件都是不同的,这就导致不同模型预测结果不同。为了降低差异,联合多个模型的预测结果。联合多个模型的方法是,对多个模型预测的框进行nms,soft-nms,WBF等处理。
2.3 目标检测
目标检测可划分多个类型。
1. one-stage 检测器:YOLOX,FCOS,DETR,Scaled-YOLOv4,EfficientDet。
2. two-stage 检测器:VFNet,CenterNet2
3. anchor-based 检测器:Scaled-YOLOv4,YOLOv5
4. anchor-free 检测器:CenterNet,YOLOX,RepPoints。
5. 专门针对无人机捕捉场景检测器:RRNet,PENet,CenterNet。
目标检测通常有三部分组成:backbone,neck,prediction head。
backbone:VGG,ResNet,DenseNet,MobileNet,EfficientNet,CSPDarknet53,Swin Transformer等等。
neck:neck设计的目的是为了更好地为backbone提供特征提取能力。通常由bottom-up和top-down形式。最早期的neck是up和down采样快。通常使用路径聚合块:FPN,PANet,NAS-FPN,BiFPN,ASFF,SFAM。neck上还有一些额外的块,比如:SPP,ASPP,RFB,CBAM等。
head:检测头目的是用来检测目标框位置和目标类别的。head一般被分为两种类型:one-stage和two-stage的目标检测器。two-stage目标检测方式一直主导方法,比如RCNN系列。one-stage目标检测器直接预测bounding box和目标类别,比如yolo系列,SSD,RetinaNet等。
3. TPH-YOLOv5
3.1 YOLOv5综述
yolov5共四个模型:yolov5s,yolov5m,yolov5l,yolov5x。
yolov5组成:backbone是CSPDarknet53 + SPP,Neck是PANet,detection head是YOLO head。
数据增强:Mosaic,MixUp,photometric distortions,geometric distortions。
3.2 TPH-YOLOv5
TPH-YOLOv5模型框架如图3所示。本文修改官方的yolov5模型,使她更加适应VisDrone2021数据集。

Prediction head for tiny objects:因为比赛数据集VisDrone2021包含了很多极其小的目标,所以增加更多小目标的预测头。共四个预测头,来缓解物体剧烈变化带来的尺寸变化。如图3第一个TPH就是专门用来预测小目标(tiny object)产生的。虽然计算量和内存增加,但是效果也有很大提升。
Transformer encoder block:受transformer启发,本文使用transformer encode block替换convolutional blocks和CSP bottleneck blocks。这个结构如图4所示。

作者认为transformer encode block相对于CSPDarknet53块 能够捕获更多的全局信息和丰富的上下文信息。transformer encode block包含两子层:多头注意力层和全连接层。
Convolutional block attention module (CBAM):CBAM是一个轻量级且有效的模块,可轻易嵌入CNN框架中。给出一个特征图,CBAM可以在通道和空间上给出注意力图。CBAM如图5所示。实验表明CBAM对最终效果有巨大的提升。

Ms-testing and model ensemble:本文在不同视角训练五个不同的模型。推理时,使用ms-testing策略:1. 缩放图像至原图的1.3倍。2. 分别把图像缩小1倍,0.83倍,0.67倍。3. 水平翻转图像。最终获取6个人不同尺度的图像,并使用nms融合预测结果。 不同模型使用相同的ms-testing操作,最终通过WBF融合5个模型的预测结果。
Self-trained classifier:自训练分类器,主要对一些预测的检测框很准确但是对分类能力较差的类别从原图上剪切出来,并resize到64*64大小,使用ResNet18做一个分类网络,最终结果提升0.8%~1.0%的AP。
4. 实验
数据集:VisDrone 2021。
测试集:VisDrone 2021中的testset-challenge,testset-dev
测评指标:mAP([0.5:0.95],AP50)
4.1 实现细节
pytorch版本:1.8.1
算法:TPH-YOLOv5
显卡:NVIDIA RTX3090 GPU (训练和测试)
预训练模型:yolov5x。因为TPH-YOLOv5和YOLOv5共享大部分backbone(block 0~8)和部分head(block 10~13 和 block 15~18)。
训练epoch:65 epoch。因为训练集较少。
warm-up:2 epoch。
优化器:adam optimizer。
初始学习率:3e-4。
schedule:cosine lr。
last epoch学习率:衰减到初始学习率的0.12倍。
输入图像尺寸:最长边1536个像素
batch size:2
数据分析:模型训练前先遍历整个数据,对提高mAP是有很大帮助的。本文分析VisDrone2021训练集的bounding boxes,当输入是1536时,有622 / 342391个label框小于3个像素的,如图7所示。对训练集做预处理:用灰色方块覆盖小目标,在训练的话mAP提高了0.2。

多尺度测试:训练时使用多种数据增强方式提高模型效果,那么测试时使用数据增强,理论上也能够带来性能的提升。本文使用三种不同尺寸的图像做测试,并且每种尺寸图像做翻转增强,所以一张测试图像共获取6张不同的图像。然后测试这6张不同图像,融合他们的结果,得到最终结果。
4.2 对比sota算法
对比数据集:VisDrone2021-DET testset-challenge。
受比赛服务器的限制,本文只得到了4个模型在测试集挑战上的结果和5个模型集成的最终结果。
效果mAP:39.18(VisDrone2021) > 38.37(VisDrone2020)
比赛排名:5名,比第一名39.43,低了0.25。 如果没有提交次数限制,本算法将获取更高的排名。
table1 是历年VisDrone比赛得分和提交算法的对比。

4.3 消融实验
测试数据集:VisDrone2021-DET testset-dev。
table 2就是本文算法的消融实验结果,添加对应模块的效果。

有效额外预测头:增加小目标检测头,yolov5x层的数量有607增加到719。GFLOPs:219.0 -> 259.0。虽然计算量增加了,但是效果也有很大的提升。如图9所示,小目标的检测效果有很大的提升,所以增加计算量是值得的。

有效的transformer编码块:使用transformer encoder block后,模型层数由719 -> 705,GFLOPs由259.0 -> 237.3。使用transformer encoder block不仅能够提高mAP,还能够降低网络尺寸。同时,在稠密目标和大目标检测中,扮演者重要角色。
有效的模型集成:table 3是5个不同模型在每个分类上的最终融合结果和对比。 每个模型都是不一样的:In training phrase, we use different input image sizes and change the weight of each category to make each model unique.文章来源:https://www.toymoban.com/news/detail-445458.html
 文章来源地址https://www.toymoban.com/news/detail-445458.html
文章来源地址https://www.toymoban.com/news/detail-445458.html
到了这里,关于TPH-yolov5论文解读的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!