(零)前言
本篇继续讲怎么管理大量的模型,生成预览图的技巧,模型备注大用途,分组管理的不足。
更多不断丰富的内容参考:🔗《继续Stable-Diffusion WEBUI方方面面研究(内容索引)》
(一)模型预览图
咱已经了解《管好【SD-WEBUI】中大量的模型:名称+预览图+备注+分组管理》这部分,使用子文件夹分组管理了模型,突然之间觉得管理很多模型也不难,于是下载了一堆模型……
(1.1)预览图姿态(证件照)
对于多个模型(这里的例子是人物LoRA),我们通常希望生成描述相同的预览图。
这样方便直观的看到模型之间的差异。大概如下图例子:
这时仅仅用相同的参数加上相同的随机种子,是很难生成统一角度照片的。
我们可以找一张证件照的图片(我就是随便网上找的)。
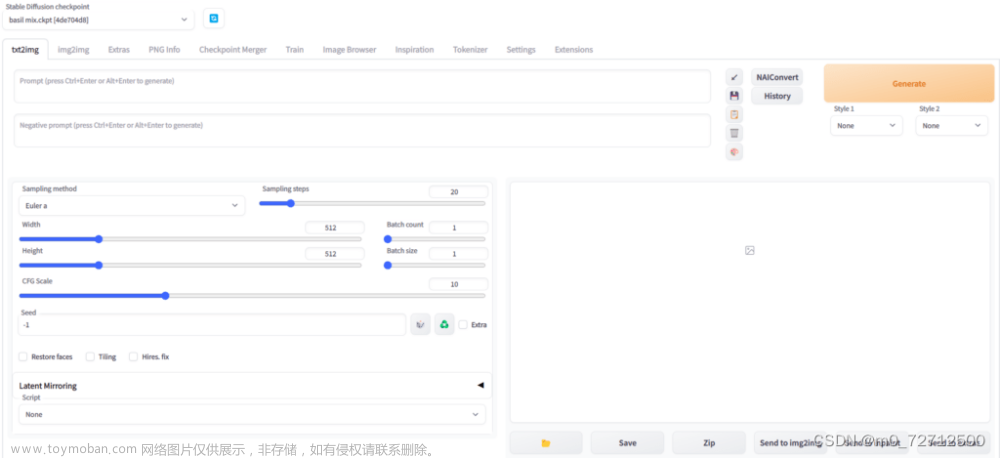
然后配合ControlNet(我用的是深度模型)。
注意参数,不要让ControlNet控制得太死,毕竟每个人的发型并不是完全一样的。
大概如下图设置:
(1.2)预览图姿态(半身动作)
同理,但是如果我们想生成半身照,那么可能用骨骼姿态而不是深度,更加能体现模型间的区别。
生成时我直接用了已有的骨骼姿态图。
所以不选预处理器了。如下图设置。
(二)LoRA模型名称
这里的例子依然是人物LoRA模型,因为基础模型不是这样用的。
之前说不要改名模型,否则后续很难管理升级等,但是咱也经常手贱改了……
WEBUI现在增加了一个选项,可以让你选择如何使用提示词中的LoRA模型的名字。
- 选文件名(文件名是:Keanu Reeves v1.0.safetensors),则提示词是:
... head portrait,..., best quality, <lora:Keanu Reeves v1.0:1> - 选文件中的模型名(别名),则提示词是:
... head portrait,..., best quality, <lora:KeanuV5:1>
改成Alias from file后,就算我们修改了模型的文件名,也不会影响模型出现在提示词中的名字——上例中的KeanuV5这个模型的别名是不会变的,相对也容易管理版本升级了。
当然坏处也有,有些模型它的模型别名并不是很容易理解(取决于作者)。
(三)模型的备注
对于有些LoRA模型,并不是加入提示词<lora:xxxx model:1>就可以用了。
比如下面这几位,基本上都需要一个触发词才能正确的画出来。
思域那个,触发词是civtypr我感觉不太方便记忆……
这时候我们可以把触发词写在备注里面。
备注还可以包括是否需要特殊的引导强度?特殊使用注意事项?都Memo一下吧。
- 💡备注支持多行(方便)
- 💡备注支持表情图标(Yes)
PS:最后感谢GTR34的作者,否则我们想画GTR时,出来的都是R35。
PS2:头文字D周杰伦版本里面余文乐开的是R32。而且到R34为止,GTR都有Skyline的前缀(扯远了……)。
下图是另一个备注的例子,比如泼墨写了2行,还需要降低CFG使用:
(四)子目录分组的局限
显而易见,就是一个模型不能属于多组了。对于比较模糊的情况,可能难选分组。
当然好处就是不需要额外的配置,超方便。
(五)第三部分
用插件管理非常详细的模型信息(比如:原作者发布的信息)。
参考:🔗管好【SD-WEBUI】中大量的模型:模型信息预览插件(Part.3)文章来源:https://www.toymoban.com/news/detail-445680.html
🤪 to be continued…文章来源地址https://www.toymoban.com/news/detail-445680.html
到了这里,关于管好【SD-WEBUI】中大量的模型:名称+预览图+备注+分组(Part.2)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!