目录
1、前言
2、数据集
3、添加ECVBlock
4、BackBone+ECVBlock
5、Head+ECVBlock
6、训练结果
6.1 Backbone
6.2 Head
1、前言

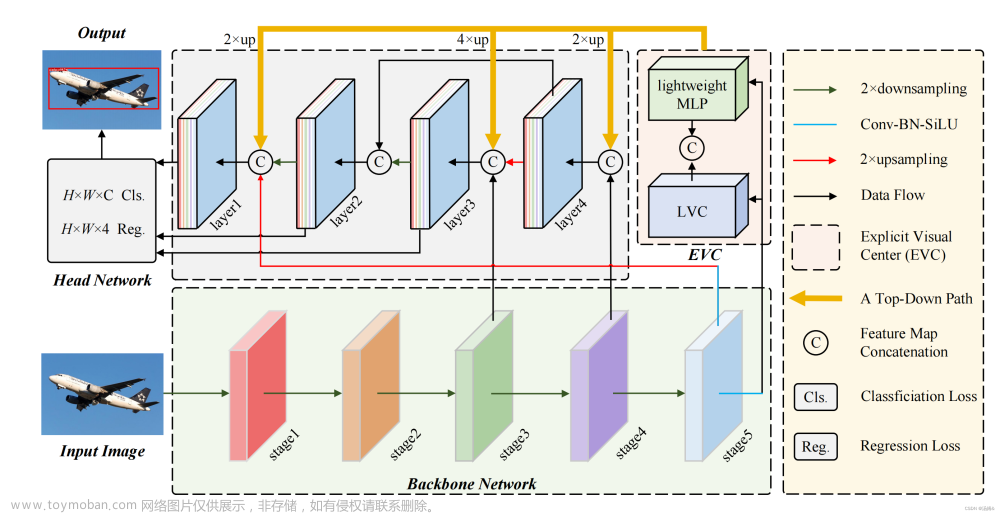
视觉特征金字塔在广泛的应用中显示出其有效性和效率的优越性。然而,现有的方法过分地集中于层间特征交互,而忽略了层内特征规则,这是经验证明是有益的。尽管一些方法试图借助注意机制或视觉变换器学习紧凑的层内特征表示,但它们忽略了对密集预测任务很重要的被忽略的角点区域。为了解决这一问题,本文提出了一种基于全局显式集中式特征规则的集中式特征金字塔(CFP)对象检测方法。具体而言,我们首先提出了一种空间显式视觉中心方案,其中使用轻量级MLP来捕捉全局长距离依赖关系,并使用并行可学习视觉中心机制来捕捉输入图像的局部角区域。在此基础上,我们以自顶向下的方式对常用的特征金字塔提出了一个全局集中的规则,其中使用从最深层内特征获得的显式视觉中心信息
以调节额叶浅部特征。与现有的特征金字塔相比,CFP不仅具有捕获全局长距离依赖关系的能力,而且能够有效地获得全面但有区别的特征表示。在具有挑战性的MS-COCO上的实验结果验证了我们提出的CFP能够在最先进的YOLOv5和YOLOX目标检测基线上实现一致的性能增益。

开源得github网址:
https://github.com/QY1994-0919/CFPNethttps://github.com/QY1994-0919/CFPNet
里面得issuse,有提到有人在自己得数据有所增强,告诉了怎么添加得位置


2、数据集
训练集:930张 验证集:265张 测试集:130张
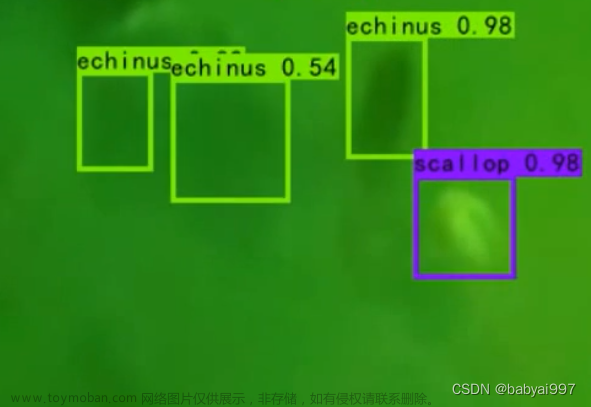
可以看到数据集中需要检测的是图像的边缘突出的小毛刺,一方面特备的小,一方面分辨率又不是很高。所以存在极大的难度,目前基于YOLOV5s模型最佳的map也只是0.904
3、添加ECVBlock
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Copyright (c) 2014-2021 Megvii Inc. All rights reserved.
import torch
import torch.nn as nn
from torch.nn import functional as F
from .Functions import Encoding, Mean, DropPath, Mlp, GroupNorm, LayerNormChannel, ConvBlock
class SiLU(nn.Module):
"""export-friendly version of nn.SiLU()"""
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
def get_activation(name="silu", inplace=True):
if name == "silu":
module = nn.SiLU(inplace=inplace)
elif name == "relu":
module = nn.ReLU(inplace=inplace)
elif name == "lrelu":
module = nn.LeakyReLU(0.1, inplace=inplace)
else:
raise AttributeError("Unsupported act type: {}".format(name))
return module
class BaseConv(nn.Module):
"""A Conv2d -> Batchnorm -> silu/leaky relu block""" # CBL
def __init__(
self, in_channels, out_channels, ksize, stride, groups=1, bias=False, act="silu"
):
super().__init__()
# same padding
pad = (ksize - 1) // 2
self.conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=ksize,
stride=stride,
padding=pad,
groups=groups,
bias=bias,
)
self.bn = nn.BatchNorm2d(out_channels)
self.act = get_activation(act, inplace=True)
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class DWConv(nn.Module):
"""Depthwise Conv + Conv"""
def __init__(self, in_channels, out_channels, ksize, stride=1, act="silu"):
super().__init__()
self.dconv = BaseConv(
in_channels,
in_channels,
ksize=ksize,
stride=stride,
groups=in_channels,
act=act,
)
self.pconv = BaseConv(
in_channels, out_channels, ksize=1, stride=1, groups=1, act=act
)
def forward(self, x):
x = self.dconv(x)
return self.pconv(x)
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(
self,
in_channels,
out_channels,
shortcut=True,
expansion=0.5,
depthwise=False,
act="silu",
):
super().__init__()
hidden_channels = int(out_channels * expansion)
Conv = DWConv if depthwise else BaseConv
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
self.conv2 = Conv(hidden_channels, out_channels, 3, stride=1, act=act)
self.use_add = shortcut and in_channels == out_channels
def forward(self, x):
y = self.conv2(self.conv1(x))
if self.use_add:
y = y + x
return y
class ResLayer(nn.Module):
"Residual layer with `in_channels` inputs."
def __init__(self, in_channels: int):
super().__init__()
mid_channels = in_channels // 2
self.layer1 = BaseConv(
in_channels, mid_channels, ksize=1, stride=1, act="lrelu"
)
self.layer2 = BaseConv(
mid_channels, in_channels, ksize=3, stride=1, act="lrelu"
)
def forward(self, x):
out = self.layer2(self.layer1(x))
return x + out
class SPPBottleneck(nn.Module):
"""Spatial pyramid pooling layer used in YOLOv3-SPP"""
def __init__(
self, in_channels, out_channels, kernel_sizes=(5, 9, 13), activation="silu"
):
super().__init__()
hidden_channels = in_channels // 2
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=activation)
self.m = nn.ModuleList(
[
nn.MaxPool2d(kernel_size=ks, stride=1, padding=ks // 2)
for ks in kernel_sizes
]
)
conv2_channels = hidden_channels * (len(kernel_sizes) + 1)
self.conv2 = BaseConv(conv2_channels, out_channels, 1, stride=1, act=activation)
def forward(self, x):
x = self.conv1(x)
x = torch.cat([x] + [m(x) for m in self.m], dim=1)
x = self.conv2(x)
return x
class CSPLayer(nn.Module):
"""C3 in yolov5, CSP Bottleneck with 3 convolutions"""
def __init__(
self,
in_channels,
out_channels,
n=1,
shortcut=True,
expansion=0.5,
depthwise=False,
act="silu",
):
"""
Args:
in_channels (int): input channels.
out_channels (int): output channels.
n (int): number of Bottlenecks. Default value: 1.
"""
# ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
hidden_channels = int(out_channels * expansion) # hidden channels
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
self.conv2 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
self.conv3 = BaseConv(2 * hidden_channels, out_channels, 1, stride=1, act=act)
module_list = [
Bottleneck(
hidden_channels, hidden_channels, shortcut, 1.0, depthwise, act=act
)
for _ in range(n)
]
self.m = nn.Sequential(*module_list)
def forward(self, x):
x_1 = self.conv1(x)
x_2 = self.conv2(x)
x_1 = self.m(x_1)
x = torch.cat((x_1, x_2), dim=1)
return self.conv3(x)
class Focus(nn.Module):
"""Focus width and height information into channel space."""
def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu"):
super().__init__()
self.conv = BaseConv(in_channels * 4, out_channels, ksize, stride, act=act)
def forward(self, x):
# shape of x (b,c,w,h) -> y(b,4c,w/2,h/2)
patch_top_left = x[..., ::2, ::2]
patch_top_right = x[..., ::2, 1::2]
patch_bot_left = x[..., 1::2, ::2]
patch_bot_right = x[..., 1::2, 1::2]
x = torch.cat(
(
patch_top_left,
patch_bot_left,
patch_top_right,
patch_bot_right,
),
dim=1,
)
return self.conv(x)
class LVCBlock(nn.Module):
def __init__(self, in_channels, out_channels, num_codes, channel_ratio=0.25, base_channel=64):
super(LVCBlock, self).__init__()
self.out_channels = out_channels
self.num_codes = num_codes
num_codes = 64
self.conv_1 = ConvBlock(in_channels=in_channels, out_channels=in_channels, res_conv=True, stride=1)
self.LVC = nn.Sequential(
nn.Conv2d(in_channels, in_channels, 1, bias=False),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True),
Encoding(in_channels=in_channels, num_codes=num_codes),
nn.BatchNorm1d(num_codes),
nn.ReLU(inplace=True),
Mean(dim=1))
self.fc = nn.Sequential(nn.Linear(in_channels, in_channels), nn.Sigmoid())
def forward(self, x):
x = self.conv_1(x, return_x_2=False)
en = self.LVC(x)
gam = self.fc(en)
b, in_channels, _, _ = x.size()
y = gam.view(b, in_channels, 1, 1)
x = F.relu_(x + x * y)
return x
# LightMLPBlock
class LightMLPBlock(nn.Module):
def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu",
mlp_ratio=4., drop=0., act_layer=nn.GELU,
use_layer_scale=True, layer_scale_init_value=1e-5, drop_path=0., norm_layer=GroupNorm): # act_layer=nn.GELU,
super().__init__()
self.dw = DWConv(in_channels, out_channels, ksize=1, stride=1, act="silu")
self.linear = nn.Linear(out_channels, out_channels) # learnable position embedding
self.out_channels = out_channels
self.norm1 = norm_layer(in_channels)
self.norm2 = norm_layer(in_channels)
mlp_hidden_dim = int(in_channels * mlp_ratio)
self.mlp = Mlp(in_features=in_channels, hidden_features=mlp_hidden_dim, act_layer=nn.GELU,
drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. \
else nn.Identity()
self.use_layer_scale = use_layer_scale
if use_layer_scale:
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones((out_channels)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((out_channels)), requires_grad=True)
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(self.layer_scale_1.unsqueeze(-1).unsqueeze(-1) * self.dw(self.norm1(x)))
x = x + self.drop_path(self.layer_scale_2.unsqueeze(-1).unsqueeze(-1) * self.mlp(self.norm2(x)))
else:
x = x + self.drop_path(self.dw(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
# EVCBlock
class EVCBlock(nn.Module):
def __init__(self, in_channels, out_channels, channel_ratio=4, base_channel=16):
super().__init__()
expansion = 2
ch = out_channels * expansion
# Stem stage: get the feature maps by conv block (copied form resnet.py) 进入conformer框架之前的处理
self.conv1 = nn.Conv2d(in_channels, in_channels, kernel_size=7, stride=1, padding=3, bias=False) # 1 / 2 [112, 112]
self.bn1 = nn.BatchNorm2d(in_channels)
self.act1 = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=1, padding=1) # 1 / 4 [56, 56]
# LVC
self.lvc = LVCBlock(in_channels=in_channels, out_channels=out_channels, num_codes=64) # c1值暂时未定
# LightMLPBlock
self.l_MLP = LightMLPBlock(in_channels, out_channels, ksize=1, stride=1, act="silu", act_layer=nn.GELU, mlp_ratio=4., drop=0.,
use_layer_scale=True, layer_scale_init_value=1e-5, drop_path=0., norm_layer=GroupNorm)
self.cnv1 = nn.Conv2d(ch, out_channels, kernel_size=1, stride=1, padding=0)
def forward(self, x):
x1 = self.maxpool(self.act1(self.bn1(self.conv1(x))))
# LVCBlock
x_lvc = self.lvc(x1)
# LightMLPBlock
x_lmlp = self.l_MLP(x1)
# concat
x = torch.cat((x_lvc, x_lmlp), dim=1)
x = self.cnv1(x)
return x
4、BackBone+ECVBlock
Yaml文件:
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]], # 4
[-1, 1, EVCBlock, [256, 256]], # update
[-2, 1, Conv, [512, 3, 2]], # 6-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 8-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 10
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 7], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 5], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 15], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
5、Head+ECVBlock
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[-1, 1, EVCBlock, [512, 512]], # update
[[-1, 6], 1, Concat, [1]], # cat backbone P4 -2 输出
[-1, 3, C3, [512, False]], # 13 ---
[-1, 1, Conv, [256, 1, 1]], #
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3 # 512
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 15], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
6、训练结果
6.1 Backbone
Yolov5s+ECVBlock
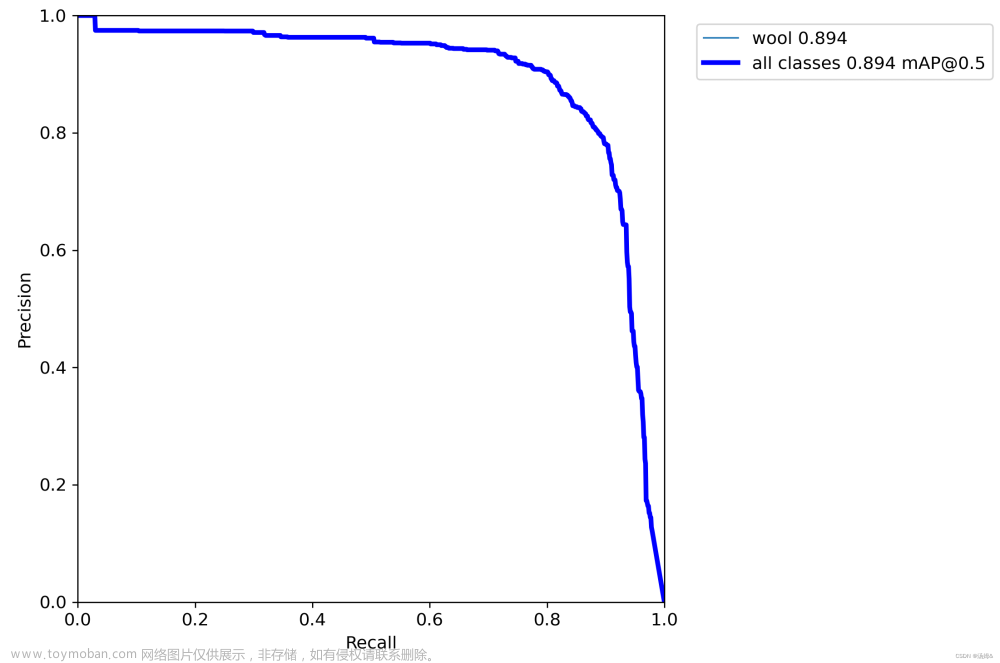
YOLOV5S:
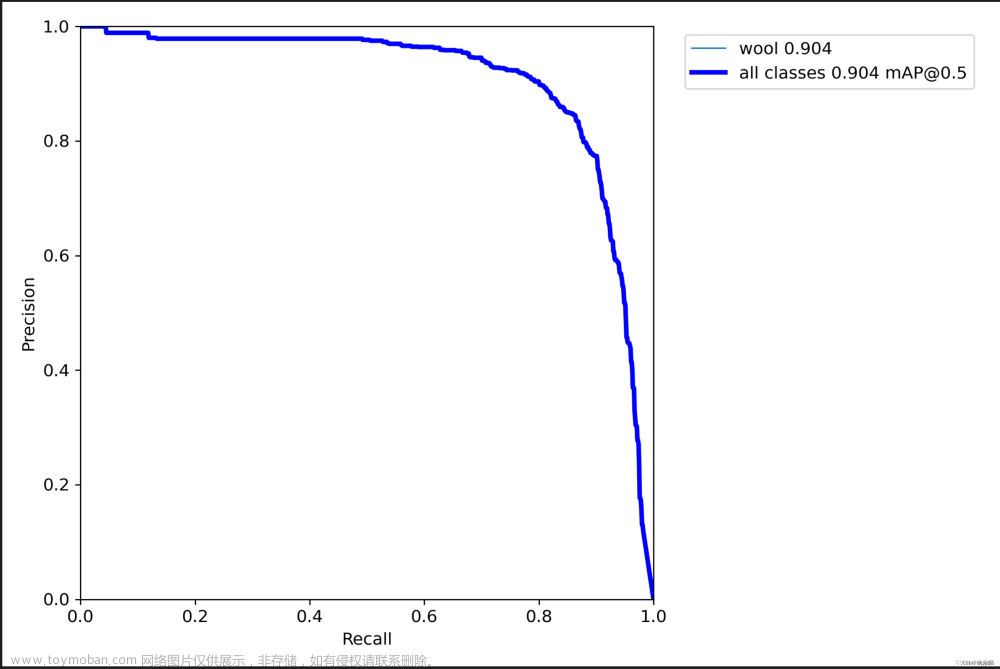
6.2 Head
 文章来源:https://www.toymoban.com/news/detail-445727.html
文章来源:https://www.toymoban.com/news/detail-445727.html
。。。。。。。。。。。。。。。怎么说呢 就是感觉可能在自己的数据上不是很好吧。文章来源地址https://www.toymoban.com/news/detail-445727.html
到了这里,关于YoloV5+ECVBlock:基于YoloV5-ECVBlock的小目标检测训练的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!